最近半年来,随着AWS的各线服务都开始支持lambda,serverless architecture便渐渐成为一个火热的话题。lambda是amzon推出的一个受控的运行环境,起初仅仅支持nodejs(之后添加了java/python的支持)。你可以写一段nodejs的代码,为其创建一个lambda资源,这样,当指定的事件来临的时候,aws的运行时会创建你的运行环境,执行你的代码,执行完毕(或者timeout)后,回收一切资源。这看起来并不稀罕,整个运行环境还受到很多限制,比如目前aws为lambda提供了哪些事件支持,你就能用哪些事件,同时你的代码无法超过timeout指定的时间执行(目前***是5min),内存使用最多也就是1.5G。那么问题来了,这样一个看起来似乎有那么点鸡肋的服务,为什么还受到如此热捧?原因就在于无比低廉的价格(每百万次请求0.2美元 + 每百万GB秒运行时间16.67美元),毋须操心infrastructure,以及近乎***扩容的能力。
使用lambda处理事件触发
在服务器端,我们所写的大部分代码是事件触发的:
处理用户对某个URI的请求(打开某个页面,点击某个按钮)
用户注册时发邮件验证邮箱地址
用户上传图片时将图片切割成合适的尺寸
当log持续出现若干次500 internal error时将错误日志聚合发给指定的邮箱
半夜12点,分析一天来收集的数据(比如clickstream)并生成报告
当数据库的某个字段修改时做些事后处理
同时,在处理一个事件的过程中,往往会触发新的事件。基本上我们做一个系统,如果能厘清内部的数据流和事件流,以及对应的行为,那么这个系统的架构也就八九不离十了。如果要让我们自己来设计一个分布式的事件处理系统,一般会使用Message Qeueue,比如RabbitMQ或者Kafka作为事件激发和事件处理的中枢。这往往意味着在现有的infrastructure之外至少添置事件处理的broker(MQ)和worker(读取并处理事件的例程)。如果你用aws的服务,SQS(或者SNS+SQS)可以作为broker,然后配置若干台EC2做worker。如果某个事件流的产生速度大大超过这个事件流的处理速度,那么我们还得考虑使用auto scaling group在queue的长度超过一定阈值或者低于一定阈值时scale up / down。这不仅麻烦,也无法满足某些要求一定访问延迟保障的场景,因为,新的EC2的启动直至在auto scaling group里被标记为可用是数十秒级的动作。
lambda就很好地弥补了这个问题。lambda的执行是置于container之中的,所以启动速度可以低至几十到数百毫秒之间,而且它可以被已知的事件或者某段代码触发,所以基本上你可以在不同的上下文中直接调用或者触发lambda函数,当然也可以使用SNS(kenisis)+lambda取代原本用MQ+worker完成的工作。
我们看上述事件的处理:
处理用户对某个URI的请求(打开某个页面,点击某个按钮):使用API gateway + lambda
用户注册时发邮件验证邮箱地址:
可以在用户注册的流程里直接调用lambda函数发送邮件
如果使用dynamodb,可以配置lambda函数使其使用dynamodb stream在用户数据写入数据时调用lambda
用户上传图片时将图片切割成合适的尺寸
可以配置lambda函数被S3的Object Create Event触发,在lambda函数里使用libMagic的衍生库处理图片。
当log持续出现若干次500 internal error时将错误日志聚合发给指定的邮箱
如果用kenisis来收集log,那么可以配置lambda函数使其使用kenisis stream
半夜12点,分析一天来收集的数据(比如clickstream)并生成报告
使用aws***支持lambda cronjob
当数据库的某个字段修改时做些事后处理
如果使用dynamodb,同上(配置lambda函数使其使用dynamodb)
如果使用RDBMS,可以使用database trigger + lambda cronjob
想进一步深入代码的童鞋,可以看我的这个repo: https://github.com/tyrchen/aws-lambda-thumbnail 。它接收S3的Object Create Event,并对event中所述的图片做resize,代码使用es6完成。为了简便起见,没有使用cloudformation创建/更新lambda function,而是使用了aws CLI(见makefile)。如果想要运行此代码,你需要定义自己的 $(LAMBDA_ROLE),手工创建S3 bucket并将其和lambda函数关联(目前aws cli不支持S3 event)。
使用lambda处理大数据
lambda近乎***扩容的能力使得我们可以很轻松地进行大容量数据的map/reduce。你可以使用一个lambda函数分派数据给另一个lambda函数,使其执行成千上万个相同的实例。假设在你的S3里存放着过去一年间每小时一份的日志文件,为做security audit,你需要从中找出非正常访问的日志并聚合。如果使用lambda,你可以把访问高峰期(7am-11pm)每两小时的日志,或者访问低谷期每四小时的日志交给一个lambda函数处理,处理结果存入dynamodb。这样会同时运行近千个lambda函数(24 x 365 / 10),在不到一分钟的时间内完成整个工作。同样的事情交给EC2去做的话,单单为这些instance配置网络就让人头疼:instance的数量可能已经超出了子网中剩余IP地址的数量(比如,你的VPC使用了24位掩码)。
同时,这样一个量级的处理所需的花费几乎可以忽略不计。而EC2不足一小时按一小时计费,上千台t2.small运行一小时的花费约等于26美金,相当可观。
使用lambda带来的架构优势
如果说lambda为事件处理和某些大容量数据的快速处理带来了新的思路,并实实在在省下了在基础设施和管理上的真金白银,那么,其在架构上也带来了新的思路和优势。
web系统是天然离散的系统,里面涵盖了众多大大小小,或并联,或串联的子系统。因为基础设施的成本问题,很多时候我们做了逻辑上的分层和解耦,却在物理上将其部署在一起,这为scalability和management都带来了一些隐患。scalability上的隐患好理解,management上的隐患是指这无形把dev和ops分成不同的team:一个个dev team可以和逻辑上的子系统一一对应,但ops却要集中起来处理部署的问题,免得一个逻辑上「解耦」的功能更新,在物理上却影响了整个系统的正常运行。这种混搭的管理架构势必会影响部署的速度和效率,和「一个team负责从功能开发到上线所有的事情」的思路是相悖的。
举个例子:「用户上传图片时将图片切割成合适的尺寸」这一需求可能在不断变化和优化。对于任何失焦的照片我们还希望做一些焦距上的优化,此外,如果上传的是头像,那么我们希望切割的位置是最合适的头像的位置,如果上传的是照片,除了切割外,我们可能还要生成黑白/灰度等等不同主题的图片。这个功能在不改变已有接口的前提下,并不会影响其他团队的工作,但因为和其他功能放在一起部署,所以部署的工作并不能自己说了算。因为部署交由专门的ops团队完成(可能一天部署一次,也可能一周部署一次),这个团队无法很快地把一些有意思的点子拿出来在生产环境试验,拖累了试错和创新。
而lambda解决了基础设施上的问题,每个子系统甚至子功能(小到函数级的粒度)都可以独立部署,这就让功能开发无比轻松。只要界定好事件流的输入输出,任何事件处理的功能本身可以按照自己团队的节奏更新。
部署和管理上的改变反过来会影响架构,促成以micro-service为主体的系统架构。micro-service孰好孰坏目前尚有争论,但micros-ervice不仅拥抱软件设计上的解耦,同时拥抱软件部署上的解耦是不争的事实。一个web系统的成败和其部署方案有着密切的关系,耦合度越低的部署方案,其局部部署更新的能力也就越强,而一个系统越大越复杂,就越不容易整体部署,所以对局部部署的要求也越来越高。这如同一个有机体,其自我更新从来不靠「死亡-重生」,而是通过新陈代谢。
此外,lambda还是一个充分受限的环境,给代码的撰写带来很多约束条件。我之前在谈架构的时候曾经提到,约束条件是好事,设计软件首先要搞明白约束条件。lambda***的几个约束是:
lambda函数必须设计成无状态的,因为其所有状态(内存,磁盘)都会在其短短的生命周期结束后消失
lambda函数有***内存限制
lambda函数有***运行时间限制
这些限制要求你把每个lambda函数设计得尽可能简单,一次只做一件事,但把它做到***。很符合unix的哲学。反过来,这些限制强迫你接受极简主义之外,为你带来了***扩容的好处。
JAWS和server-less architecture
两三个月前,我介绍了JAWS,当时它是一个利用aws刚刚推出的API gateway和lambda配合,来提供REST API的工具,如果辅以架设在S3上的静态资源,可以打造一个完全不依赖EC2的网站。这个项目从另一个角度诠释了lambda的巨大威力,所以demo一出炉,就获得了一两千的github star。如今JAWS羽翼臻至丰满,推出了尚处在beta的jaws fraemwork v1版本:https://github.com/jaws-framework/JAWS,并且在re:invent 2015上做了相当精彩的主题演讲(见github)。JAWS framework大量使用API gateway,cloudformation和lambda来提供serverless architecture,值得关注。
一个完整的serverless website可以这么考虑:
用户注册使用:API gateway,lambda,dynamodb,SES(发邮件)
用户登录使用:API gateway,lambda,或者(cognito和IAM,如果要集成第三方登录)
用户UGC各种内容:API gateway,lambda,dynamodb
其他REST API:API gateway + lambda
各种事件处理使用lambda
所有的静态资源放在S3上,使能static website hosting,然后通过javascript访问cognito或者REST API
日志存放在cloudWatch,并在需要的时候触发lambda
clickstream存在在kenisis,并触发lambda
如此这般,一个具备基本功能的serverless website就搭起来了。
如果你对JAWS感兴趣,可以尝试我生成的 https://github.com/tyrchen/jaws-test。
避免失控
lambda带来的部署上的解耦同时是把双刃剑。成千上万个功能各异的lambda函数(再加上各自不同的版本),很容易把系统推向失控的边缘。所以,***通过以下手段来避免失控:
为lambda函数合理命名:使用一定规格的,定义良好的前缀(可类比ARN)
使用cloudformation处理资源的分配和部署(可以考虑JAWS)
可视化系统的实时数据流/事件流(类似下图)
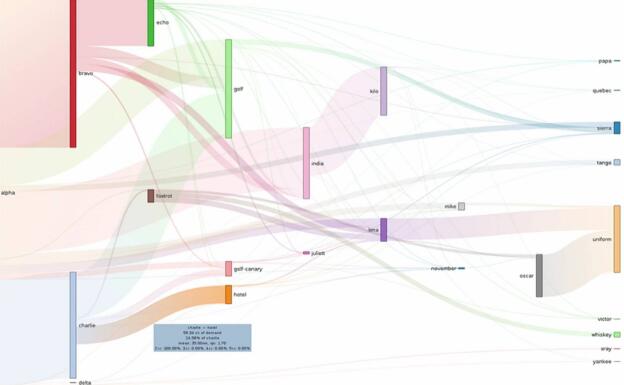
(图片来自youtube视频截图:A Day in the Life of a Netflix Engineer,图片和本文关系不大,但思想类似)
由于基于lambda的诸多应用场景还处在刚刚起步的阶段,所以很多orchestration的事情还需要自己做,相信等lambda的使用日趋成熟时,就像docker生态圈一样,会产生众多的orchestration的工具,解决或者缓解系统失控的问题。