Serverless 不意味着没有服务器,而是从应用可以在一个抽象层上忽略它的存在,而只关注在功能实现上和自身的请求处理上;每一个功能实现在不是单纯的业务逻辑处理的代码,相反每个功能调用具有了 Server 的特质,进化成为了一个具有自省、自知和自治的工作负载单元;他们更像是能够衍生出其它新功能单元的生物体。这样整个 Serverless 应用架构之内,每个生命可以衍生下去,子子孙孙无穷匮也。
处在这技术日新月异的时代里,新的技术浪潮经常对当前的技术产生着威胁和颠覆。在编写应用的时候我们目前经常谈论到“Serverless”技术。它的核心思想是把应用作为一系列的功能/function来部署,这些功能在需要的时候被按需部署。服务器管理应该是不需要去操心的事情,所有功能被按需调用,被运行在群集之上。
但是 Serverless 里不意味着没有 Docker,事实上 ”Docker 就是 Serverless”。你可以用 Docker 来容器化这些功能,然后按需地运行在 Swarm 群集上。Serverless 是一种构建分布式计算的应用的方法,而 Docker 是***的构建和运行他们的平台。
从 Server 到 Serverless
那么我们如何来编写 Serverless 的应用?让我们先看下这个例子:“一个有5个子服务组成的投票应用”:
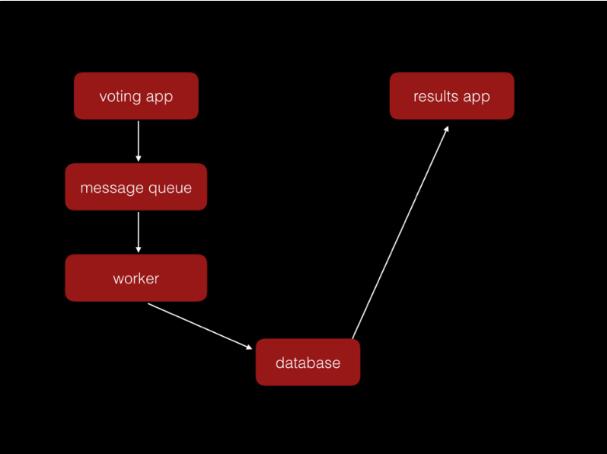
它的结构如下:
1. 两个 Web 前端
2. 一个后台的处理投票的 Worker 服务
3. 一个处理投票的消息队列
4. 一个数据库
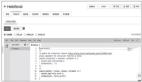
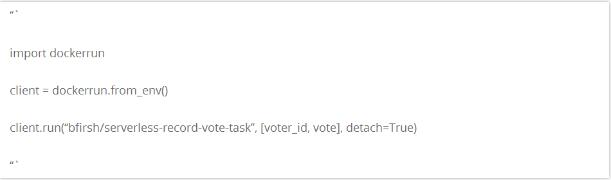
那个后台处理投票的进程是非常容易成为转换为 Serverless 架构的目标。在投票应用内,我们可以运行一点类似于下面的代码,来执行后台任务:
Worker 和消息队列能用按需在 Swarm 上运行的容器来替换,并自动地按需扩容。
我们甚至可以消除掉 Web 前端。我们可以这么做:用 Docker 容器来相应每一个HTTP 请求,每个 HTTP 请求都用一个自生长的跑着轻量 HTTP 服务器的容器来处理。之前使用的是长时间持续运行的 HTTP 服务器,现在变成了具有 HTTP 相应和处理能力的按需跑起来的容器,而且他们能自动地扩容来支持所有访问请求。
我们新的架构大概如下图所示:
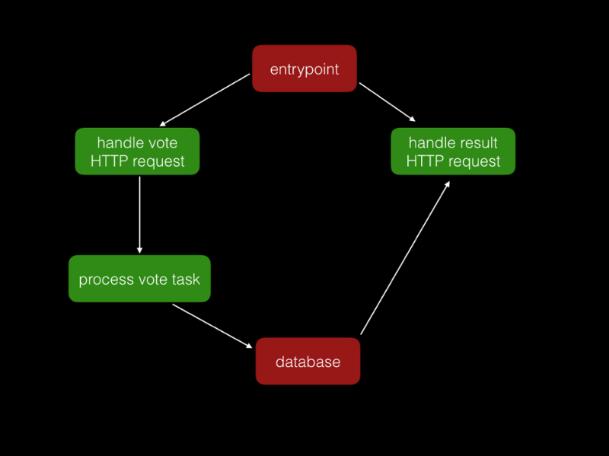
其中红色的方块是需持续长期运行的服务,而绿色方块成了按需被调用的 Docker容器。这样这个应用变成了只有少数几个需要被管理的 long-running 服务,在相应请求的时候使用原生的 Swarm 扩容能力,处理能力的上限是 Swarm 群集的上限。
具体如何实现
这里有三个有用的技巧,可以在你的程序中使用:
1. 把你代码中的 function 作为按需拉起的 Docker 容器
2. 使用 Swarm 在群集上运行这些容器
3. 从容器里面运行这些功能容器,绕过了一个 Docker API socket
使用以上技术的组合,程序执行负载发生的可能性将和您如何架构你的应用相关。运行后台任务就是一个非常适合的例子,但是整个应用中的其它工作负载也是有可能的,例如:
1.考虑到延迟,用启动一个容器来服务所有用户的 HTTP 请求可能是不现实的。可是你可以写一个内置的负载均衡逻辑,让它知道何时需要主动地自动扩容 Web 前端自身,通过在 Swarm 群集上运行更多 web 处理容器。
2.一个 MongoDB 容器可以在 Swarm 上成为一个具有自省能力的架构,它能自动地运行出正确数量的 shard 和 replica 容器。
接下来
我们已经得到了这些激进的新工具,用做构建应用的抽象层,我们隐约看到了如何深入下去的可能性。我们依然像长时间以来在一堆服务器上构建应用一样,而以后可以来利用 Swarm 能按需地在基础架构里的任何地方执行功能代码的能力。
希望这些能够给您一些如何构建应用的新思路,但是我们还需要你们的帮助。我们已经有的是一些构建 Serverless 应用的基础功能,然而他们依然不是很完备,我们需要更好的工具、库、样例程序,文档等等。