本文是WOT2016互联网运维与开发者大会的现场干货,新一届主题为WOT2016企业安全技术峰会将在2016年6月24日-25日于北京珠三角JW万豪酒店隆重召开!
在本次WOT峰会上,黄继老师分享了《小米运维动态部署和资源管理实践》,主要内容包括小米运维在业务部署中由人工进入自动化过程中有哪些设计和整合,Docker/Mesos等热门技术如何运用,规模化过程中走过哪些弯路,以及小米运维实践的分享。
【讲师简介】
黄继,小米运维部高级运维研发工程师, 负责消息、推送系统运维管理工作,主导负责小米资源管理和动态调度部署相关系统的设计和开发工作,在部署、资源管理和系统优化方面有丰富的经验。
小米运维发展和演进
开场,黄继先展示了小米整个运维自动化发展和演进的过程,如图1所示。
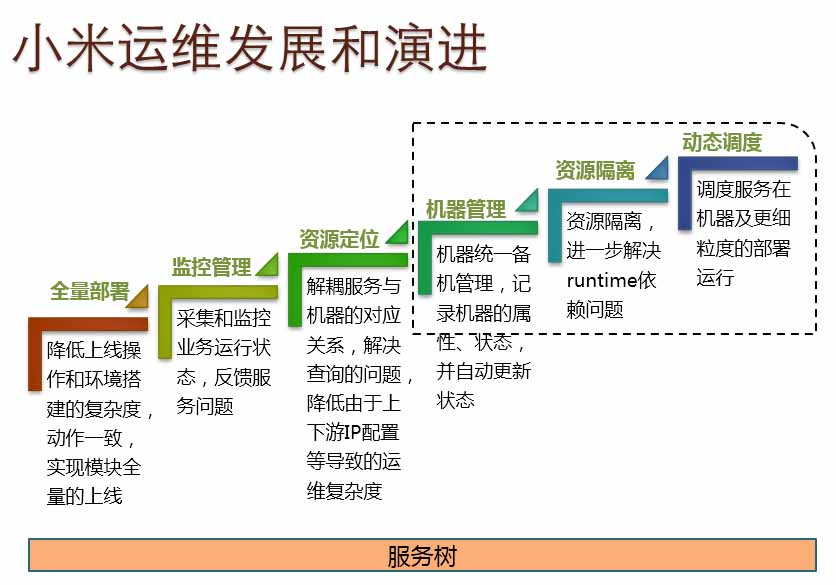
图1:小米运维发展和演进
黄继指出,小米服务树的概念几年前就提出来了,目前,前三个部分:全量部署、监控管理、资源定位都已经成型,并且开始使用了,此次主要讲的是机器管理、资源隔离、动态调度。
为什么要做资源管理和资源隔离
以动制动,动态维护,不靠人工干预,是整个运维和管理中的一个目标。具体来说,运维中有三个基本点:监控、业务、主机。这三个部分的关系如图2所示:
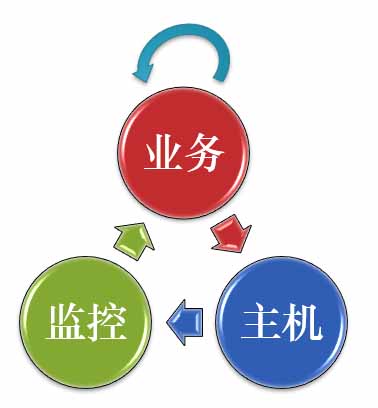
图2:需求和目标
小米的目标是让这三者之间的部署做到完全自动化,如此以来,就不需要再有资源预算,也不需要做人为规划,比如设定机器组是放前端还是后端,只要告诉机器前端要部署即可。从而实现抛弃资源预算和规划,提高部署效率,容量调整,故障快速自愈的目的。
PaaS与运维
黄继先从PaaS的优缺点讲起。
优点:
1. 对业务来讲是透明的,而且是一个***的资源池。
2. PaaS模块化的基础设施和组件,便于扩展。
3. 天然自带标准化 ,对开发来讲,是有利的。
缺点:
1. 架构标准化程度要求高 。
2. 业务类型受限,它只是开放了一个业务逻辑的层面,前面的接口和存储都是已经固化好的,通常来讲只允许接入一些HTTP服务。
3. 运行环境有特定要求。
所以,我们其实需要的是运维角度的PaaS平台。
小米私有类PaaS平台
运维角度的PaaS应该像一个大杂铺或者大池子,在这个池子里,不用考虑服务类型,前端和存储里都可以放服务。并且具有构建集群的能力,扩展的能力和自愈能力。
具体的方案选型如图3所示。
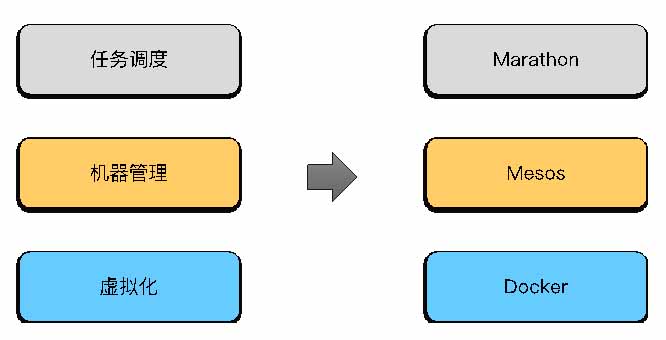
图3:方案选型
黄继提到,方案里很多功能都是开源实现的,例如动态主机的选择,集群自动创建,集群维护,自愈能力等。
接下来,黄继总结了三个运用中的实际问题。
. 业务无缝迁移。其性能和效率要达到物理机的程度,才会让业务人员接受。
. 要和周边的系统,比如服务树、监控、服务这些成型的系统相结合。
. 保证整套动态系统里边的资源的正确性。
硬件效率
Docker网络模式决定了Container的适用性。Docker的***种模式是Host Only,Host Only只是用了Docker的一些简单资源,而且是部分功能,无法把整个容器当成一个纯数据化的环境,因而不符合需求。第二种模式是用NAT,NAT虽然可以解决上述问题,但它也有两个局限性:一是要管理和维护物理机和容器里面IP的预测关系,二是对于一些网络延迟特别敏感的服务,运行时间在物理机的基础上最多可以增加30%,这是不能被接受的。
解决方法
1. 把Docker本身的网槽和物理主机的网卡调至一个模块,为了区分到底是物理机还是容器,在调制过程中让网络设备做配合,放置一个trunk,这样一来,物理机用的是一部分网络地址,容器用的是另外一部分网络地址,而且可以很容易地把容器这部分的网络地址分配交给DHCP SERVER去做,这个容器无论在什么地方启动,都可以是一个可以访问到的容器。这样就解决了容器独立性的问题。
2. 直接在物理机上开LVM,这样做的好处是和物理机读写这个设备的效率是一样的,也就是说在LVM效率上面是没有损失的。而且,因为设备的大小有限,所以天然就把存储空间也限制了。
3. 直接对Docker进行修改,让它在每起一个容器的时候,都生成一条网络输出的限制规则。
此时,整个容器的环境相对来说就是一个完整主机的环境,各方面的资源相对合理,而且是可以限制的。
编译和发布
在新的方式中,业务编译好之后生成Docker lmage,用Docker去分发。
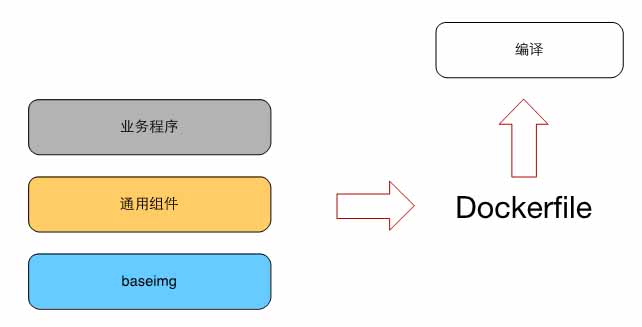
图4:编译发布
其中,baseimg是必备的,常见的通用组件可选用,上层组件可替换下层组件配置。
环境依赖和周边系统接驳:在容器里面放了init,它不仅解决启动业务的程序,还负责设置crontab,在后台程序启动stats,采集内部的一些信息,注册lvs,进行引流,或者注册xbox,mysql等。
动态实例衍生问题
在解决了动态任务分配和管理、隔离容器环境、业务平滑迁移、跟其它系统对接等难题后,接下来面对的将是一些动态实例衍生问题。例如容器IP:如何登录容器是用户始终关心的一个点,比如人工介入管理,白名单授权,HealthCheck。第二就是数据一致性保证,即数据回收。
数据一致性回收也是需要启动容器,CIP的上报可以由图5概括。

图5:CIP上报
这样的流程带来的好处就是真实性,业务和IP的对应关系无法伪造,这就给第三方验证带来很大方便,这样,登录问题就都自然而然地解决了。
同时,在这个过程中,数据一致性回收也解决了,因为,在整个系统里,Marathon做的是最完整、最准确的信息,其它系统里的数据都可以和Marathon数据作比较,通过这样的形式来保证所有系统的数据最终都是跟动态部署的是保持一致的。
部署控制
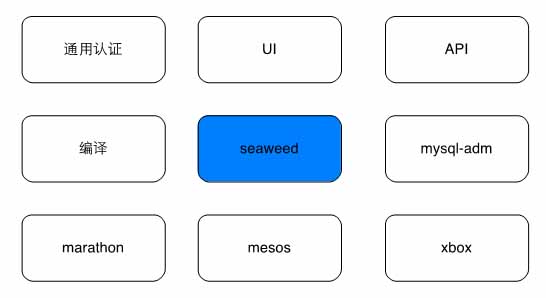
图6:部署控制
这是一个管理任务定义、生成部署任务、控制部署的过程,整合信息之后提供自动化接口。
用户界面
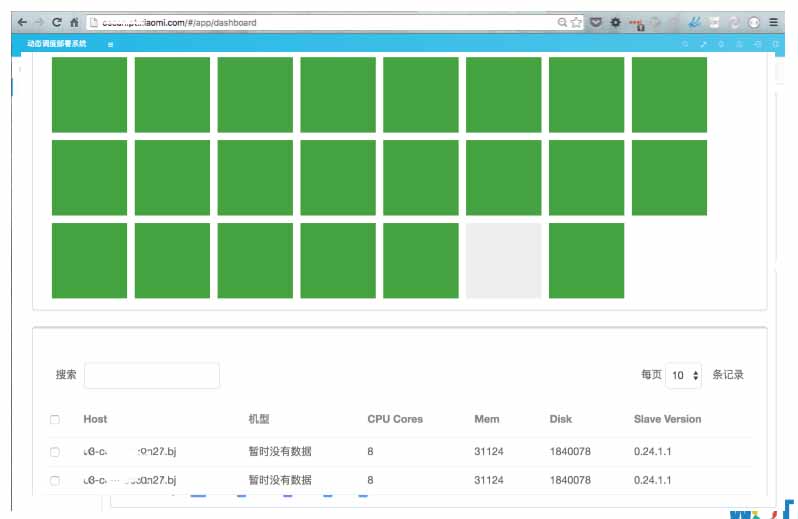
图7:用户界面
绿色表示已经上线,白色表示未上线。管理员可以通过这个界面看到整个集群所有节点的状态,如果某个节点比如说负载发生变化了,或者CPU反馈高了,就会在这个节点上做一些颜色的变化。
现状和展望
从2014年到目前,小米已经拥有2套集群,70多个节点,5个业务上线(其中2个100%承载),321个常驻实例,主机利用率提高约50%〜60%。
未来小米要做有状态的服务,包括数据存储、状态保持、资源动态调整,还要做一些类似VPC的部分。此外,容器的伸缩量也要扩展,添加一些像日志分析结果等数据源。
***,黄继表示,小米运维团队的理念口号是Ops Make NoOps,把运维的日常工作尽可能的自动化起来,减少手工运维操作。