本文是WOT2016互联网运维与开发者大会的现场干货, 新一届主题为WOT2016企业安全技术峰会将在2016年6月24日-25日于北京珠三角JW万豪酒店隆重召开!
杨大海表示,对于一个外行人或刚入门的人来说,建立一个数据平台就是搭一个Hadoop集群而已。但基于这个集群,想要把它很好的用起来会暴露很多的问题。那么针对这些问题就需要研发很多系统来应对,所以建立统一数据平台是非常重要的。
为什么说建立统一数据平台是重要的
门槛,这里杨大海表示,并不是现在做大数据的门槛有多高,因为整个大数据领域的技术非常成熟,人员也很多,很多公司都自己的团队做大数据。这里所说的门槛是指非大数据领域的一些人,如分析师可能只会写一些SQL语句或只能看懂一些数据,出一些报表,如果让这类人写Mapreduce或数据收集研发东西,就会觉得非常难,如果建立一个完善的数据平台,可有效帮助他们。
共享, 假设某公司有很多技术团队、不同部门、不同业务团队。如每个团队都搭一套Hadoop群,中间的数据共享就成了问题。还就是资源浪费,像人力资源浪费和服务器资源浪费等。
规范,基于大数据系统做一个数据产品,需要数据采集、收集、存储和计算等多个步骤,这样整个流程是非常长,花30%时间做业务系统开发,70%时间用于平台搭建或一些开源的完善,是非常不划算的。设想做数据产品之前就已经有系统供选择,有数据需要采集,有新计算模型需要诞生时候只需要接入,不需要再花时间调研。制定规范之后,日志放在哪,通过标准配置,就可以把日志采上来供使用。这样一来,就保证尽可能缩短数据采集整个的流程。
成本,这里指人力成本和服务器,就是硬件资源的成本。有统一数据平台,就可以做很多优化。面对一千台规模的服务器,可通过一些修改原码、参数优化等提升10%,就可节省约64G或者128G、4核服务器一百台。
时间,开发一套业务系统,大可不必花一个月的时间调研Hadoop,花一个月时间的调研Kafka,因为这些不在业务团队的竞争范围之内。更多的精力应放在产品或系统,如何把系统做得更***,而不是怎么把Hadoop打好。
Hadoop集群的发展进程
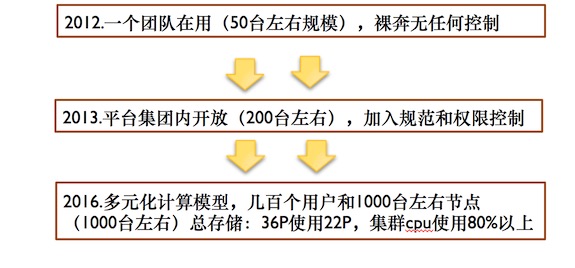
Hadoop发展规模
如上图,杨大海表示,从2012年到2016年,Hadoop集群在不断进化发展中。集群最初起点比较低,只是为了满足数据分析团队和推荐团队使用,只有三四十台的规模。在2012年到2013年的时间,集群扩张的非常快。到2013年接入很多用户,公司其他团队如广告、分成等团队接进。集群膨胀厉害,半年时间翻了四五倍,到200台左右的规模。到2016年时间,整个集群将近一千台规模,中间做了一次升级,就是1.3升级2.3,当时升级是为了满足周边的一些生态圈。
Hadoop集群发展过程中遇到的问题

hadoop问题演变
如上图,杨大海表示,整个集群发展过程中遇到的问题是随着阶段的推移不断地变化的,也就是说不同阶段遇到的不同的问题各不一样。
50台规模时,整个生态圈不完善,像Hive等本身还有很多Bug,但因为刚开始,应用简单所以并没有发现。此时团队技术功底非常差,集群管理基本上没做,直接搭了一条集群,裸奔的集群。
200百台规模时,遇到的问题相对多一些,杨大海在这里介绍了权限问题、用户管理、资源调度、调度系统、数据安全、目录规范、参数规范、本地化八大问题。
- 权限问题, 用户增多,十个上百个,那权限就成了问题。
- 用户管理,如何把用户管理好,保证用户的作业及时提交,而不是因为某个用户提交一个大作业,把整个集群资源占完,其他的脚本没法跑。如何保证这个用户存储不会***扩张。如何给用户规划存储。
- 资源调度,保证用户一定独立空间,控制占有的资源数目,不至于把整个集群的资源给占完。
- 调度系统,一台服务器,一台客户端,可能会给三个团队用,每天晚上会有上万个,甚至几千个、几百个作业来提交,通过这台机器来提交。调度系统是为了解决客户端单节点的问题,单点故障的问题。
- 数据安全,公司内部虽是同一个集团公司,但分为不同的BU,这些BU之间的数据是需要共享、也需隔离。
- 目录规范,日志如何存储,用户目录如何规划,目录需要多大的空间,如果超过空间我如何提醒删除。
- 参数规范,Hadoop有很多参数,需要增加,也需要优化。
- 本地化 ,有时需对Mapreduce本地化,因为突然间上了两百台机器,Mapreduce从中取数据,但本地没有需远程,这还需要对本地化参数做优化。
1000台左右高可用多计算模型共存时,问题就更多,更加繁琐。如用户水平、高可用、小文件、数据迁移、任务问题、存储计划、机房瓶颈、归档、资源争强分类、资源隔离、任务监控、列队监控等。
- 用户水平,用户水平有低有高,这就需要有一个人专门解答每天用户的问题。
- 高可用,这里需要做HHA,因为宕机后影响太大,所有团队的任务都需要重跑,所有团队的数据都需要重铺。
- 小文件,集群有一千台服务器,小文件数是非常多。内目录内存现在已经用到150G左右,这就需要对文件数进行控制,对近两年文件做归档。
- 任务,需要看许多指标找出问题,这更强大的监控系统来支持。
- 存储计划,同运维报一个存储计划,如集群打算一个月扩多少台服务器、如根据流量、数据量、任务量去申报。因为不可能现在突然间扩一百个机器,运维也不一定有两百台的机器提供。
- 资源争抢,是比较严重的问题,集群升级变快,但突然间可能提交不上去。
- 因为当时的调度策略,在做版本迭代升级时,有一些新功能刚推出,很多特径还不支持。
- 资源隔离,这个是之后需要做的事情。如一个任务死循环把整个服务器跑挂问题的解决。
Hadoop数据平台的发展现状
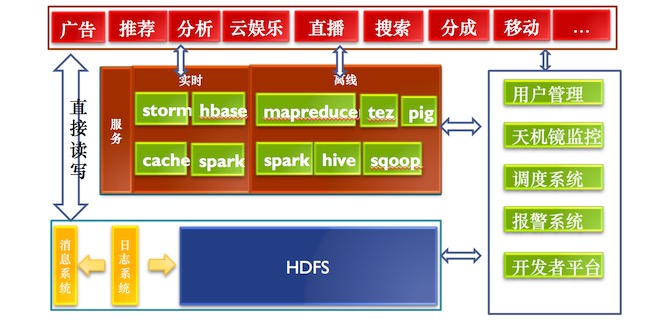
数据平台现状
杨大海表示,上图是现在数据平台的发展现状。最上层系统如团队、广告、推荐、分析、云娱乐、直播、搜索、分成、移动等,这些系统最原始的它们需要数据,所以有一套日志系统,把数据采集并存储。日志系统是研发的,因为需要解决跨机房的问题。日志收集需要遍布在全国很多个机房,机房日志收集是需要聚合,最终的数据都要聚合到一个点。左边是数据的计算部分,可直接读取日志系统的数据。右边用户管理系统是为了满足用户申请账号、放文件、需要归属一个团队、访问团队资源。监控报警系统,来做统一的监控报警。
Hadoop数据平台的未来
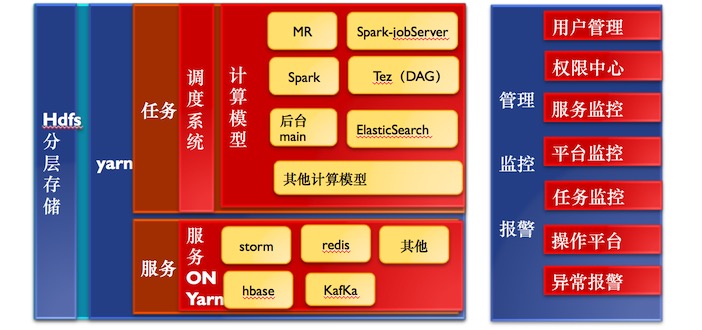
hadoop平台未来
杨大海表示,上图是集群的未来的样子,现在我们已经做到90%,但还没有完全解决。未来整个存储分为实时和离线两部分。HDFS存储可能会遍布到大数据所有服务器,很多团队是不做存储的,所以可以把存储遍布到所有的服务器,给你团队的账号。基于Yarn话会做虚拟化,完全把解决资源,资源无法隔离的痛点。基于Yarn开发更多的计算模型出来,如自定义的一些计算模型。
Hadoop平台将要面临的挑战

Hadoop平台将要面临的挑战
如上图,杨大海表示,Hadoop平台将要面临的挑战分为三部分HDFS、Yarn、Client。针对HDFS面临的挑战有Namenode性能瓶颈、日志大小的控制、节点操作的API、多机房方案、集群规模太大Namenode性能瓶颈等。针对Yarn面对的挑战有调度个性化分类、资源隔离、数据仓库的必要性、基于标签调度完善、更强大的监控平台等。针对Client面对的挑战有Docker统一管理、配置问题、业务依赖升级问题等。
Hadoop数据平台的运营问题
关于Hadoop数据平台的运营问题 ,杨大海这样说,对内部运营是非常有必要的,综上那么多问题,就因为初期运营预料到这些问题,但没有做好,导致后期花非常大的代价去挽回。他还从规范、计划、流程和策略四方面针对运营问题,做了讲解。
- 规范,就是目录怎么存,可以放多大文件,放多少文件,占用多少资源。让用户一开始就了解这个事情,以免一起限制导致客户烦感。
- 计划,集群要做一下计划,不同的时间做不同的事情,满足用户更个性化的需求,如何时完善更多的计算模型。
- 流程,用户在使用平台期间详细的知道整套的流程,如用户账号申请,如用HDFS的话做那些事,用Kafka的话做哪些事等等。所有系统之间的账号全部打通,一个账号全部搞定。
- 策略,很多时间需要制定策略来限制用户,这里说的限制并不是让用户用的不爽,是让它更健康的发展下去。
在演讲***,杨大海提到了两个问题数据仓库和数据服务。建立一个数据仓库,对数据平台来说表面上看起来是两件毫不相关的事情,一个是做数据底层,一个是做数据服务。其实两边关系非常大,如果没有一个数据仓库,做底层的会非常痛苦。这里的痛苦并不是技术满足不了,而是要不断的扩容。数据服务更大的意义是保证数据的一致性,如广告团队算了一个视频的VV量和播放量和分析团队算的一个视频的播放量不一致,这个数据是没法解释的。其实大家原数据都一样,统计口径不一样,才造成这个问题。所以数据服务是把一部分可以公开的数据算好,通过接口去公开,部分不可以公开数据,做成带有偷窥认证,带有用户认证数据结构提供出去。尽可能做到的把公司的业务前面的几个主题做仓库。
演讲视频:
http://edu.51cto.com/lesson/id-100760.html
http://edu.51cto.com/lesson/id-101082.html
【讲师简介】
杨大海,前优酷土豆大数据平台高级架构师,优酷土豆的大数据开放平台研发负责人,主要负责优酷土豆开放大数据平台的研发和运营。曾就职于亚信联创负责bi商业智能产品的研发。