












1、 机器学习
汤姆·米歇尔教授任职于卡内基梅陇大学计算机学院、机器学习系,根据他在《机器学习》一书中的定义,机器学习是“研究如何打造可以根据经验自动改善的计算机程序”。机器学习在本质上来说是跨学科的,使用了计算机科学、统计学和人工智能以及其他学科的知识。机器学习研究的主要产物是算法,可以帮助基于经验的自动改善。这些算法可以在各个行业有广泛应用,包括计算机视觉、人工智能和数据挖掘。
2、 分类
分类的含义是,打造模型,将数据分类进入不同的类别。这些模型的打造方式,是输入一个训练数据库,其中有预先标记好的类别,供算法进行学习。然后,在模型中输入类别未经标记的数据库,让模型基于它从训练数据库中所学到的知识,来预测新数据的类别。
因为这类的算法需要明确的类别标记,因此,分类算是“监督学习”的一种形式。
3、 回归
回归是与分类紧密联系在一起的。分类是预测离散的类别,而回归则适用的情况,是当预测“类别”由连续的数字组成。线性回归就是回归技术的一个例子。
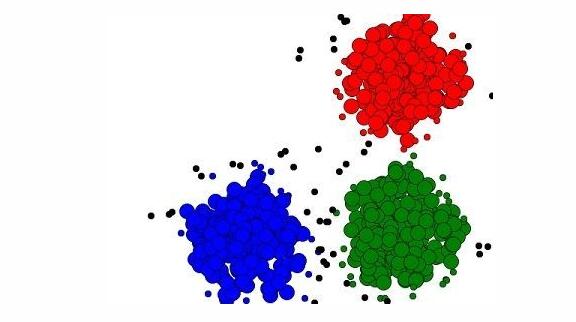
4、 聚集
聚集是用来分析不含有预先标记过的类别的数据,甚至连类别特性都没有标记过。数据个体的分组原则是这样的一个概念:最大化组内相似度、最小化组与组之间的相似度。这就出现了聚集算法,识别非常相似的数据并将其放在一组,而未分组的数据之间则没那么相似。K-means聚集也许是聚集算法中最著名的例子。
由于聚集不需要预先将类别进行标记,它算是“无监督学习”的一种形式,意味着算法通过观察进行学习,而不是通过案例进行学习。
5、 关联
要解释关联,最简单的办法是引入“购物篮分析”,这是一个比较著名的典型例子。购物篮分析是假设一个购物者在购物篮中放入了各种各样的物品(实体或者虚拟),而目标是识别各种物品之间的关联,并为比较分配支持和置信度测量(编者注:置信度是一个统计学概念,意味着某个样本在总体参数的区间估计)。这其中的价值在于交叉营销和消费者行为分析。关联是购物篮分析的一种概括归纳,与分类相似,除了任何特性都可以在关联中被预测到。 Apriori 算法被称为最知名的关联算法。
关联也属于“无监督学习”的一种形式。
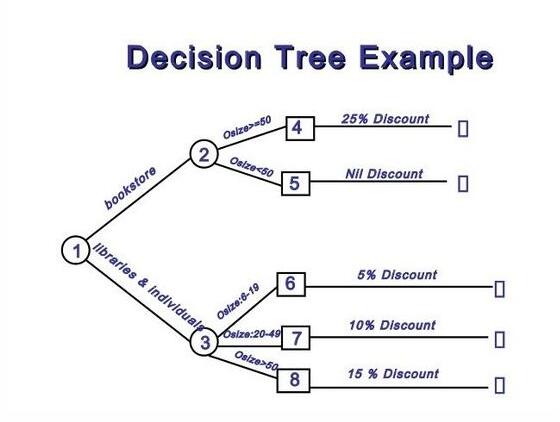
决策树的例子,分步解决并分类的方式带来了树形结构。图片来源: SlideShare 。
6、 决策树
决策树是一种自上而下、分步解决的递归分类器。决策树通常来说由两种任务组成:归纳和修剪。归纳是用一组预先分类的数据作为输入,判断最好用哪些特性来分类,然后将数据库分类,基于其产生的分类数据库再进行递归,直到所有的训练数据都完成分类。打造树的时候,我们的目标是找到特性来分类,从而创造出最纯粹的子节,这样,要将数据库中所有数据分类,只需要最少的分类次数。这种纯度是以信息的概念来衡量。
一个完整的决策树模型可能过于复杂,包含不必要的结构,而且很难解读。因而我们还需要“修剪”这个环节,将不需要的结构从决策树中去除,让决策树更加高效、简单易读并且更加精确。
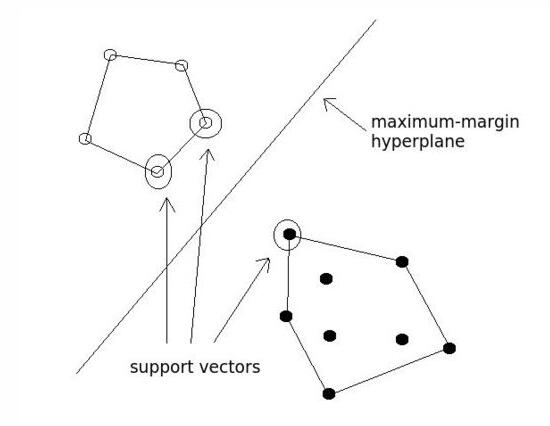
右上箭头:最大间隔超平面。左下箭头:支持向量。图片来源: KDNuggets 。
7、 支持向量机(SVM)
SVM可以分类线性与非线性数据。SVM的原理是将训练数据转化进入更高的维度,再检查这个维度中的最优间隔距离,或者不同分类中的边界。在SVM中,这些边界被称为“超平面”,通过定位支持向量来划分,或者通过最能够定义类型的个例及其边界。边界是与超平面平行的线条,定义为超平面及其支持向量之间的最短距离。
SVM的宏伟概念概括起来就是:如果有足够多的维度,就一定能发现将两个类别分开的超平面,从而将数据库成员的类别进行非线性化。当重复足够多的次数,就可以生成足够多的超平面,在N个空间维度中,分离所有的类别。
8、 神经网络
神经网络是以人类大脑为灵感的算法,虽然,这些算法对真实人脑功能的模拟程度有多少,还存在很多的争议,我们还没法说这些算法真正模拟了人类大脑。神经网络是由无数个相互连接的概念化人工神经元组成,这些神经元在互相之间传送数据,有不同的相关权重,这些权重是基于神经网络的“经验”而定的。“神经元”有激活阈值,如果各个神经元权重的结合达到阈值,神经元就会“激发”。神经元激发的结合就带来了“学习”。
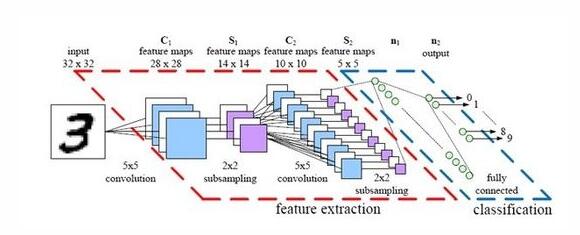
9、 深度学习
深度学习相对来说还是个比较新的词汇,虽然在网络搜索大热之前就已经有了这个词汇。这个词汇在研究和业界都名声大噪,主要是因为其他一系列不同领域的巨大成功。深度学习是应用深度神经网络技术——具有多个隐藏神经元层的神经网络架构——来解决问题。深度学习是一个过程,正如使用了深度神经网络架构的数据挖掘,这是一种独特的机器学习算法。
10、增强学习
对于“增强学习”最好的描述来自剑桥大学教授、微软研究科学家Christopher Bishop,他用一句话精确概括:“增强学习是在某一情景中寻找最适合的行为,从而最大化奖励。”增强学习中,并没有给出明确的目标;机器必须通过不断试错的方式进行学习。我们来用经典的马里奥游戏举个例子。通过不断试错,增强学习算法可以判断某些行为、也就是某些游戏按键可以提升玩家的游戏表现,在这里,试错的目标是最优化的游戏表现。
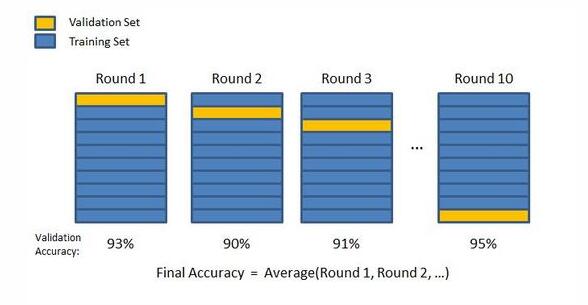
K层交叉检验的例子,在每一轮使用不同的数据进行测试(蓝色为训练数据、黄色为测试数据),方框下为每一轮的验证精度。最终的验证精度是10轮测试的平均数。图片来源: GitHub 。
11、K层交叉检验
交叉检验是一种打造模型的方法,通过去除数据库中K层中的一层,训练所有K减1层中的数据,然后用剩下的第K层来进行测验。然后,再将这个过程重复K次,每一次使用不同层中的数据测试,将错误结果在一个整合模型中结合和平均起来。这样做的目的是生成最精确的预测模型。
12、贝叶斯
当我们讨论概率的时候,有两个最主流的学派:经典学派概率论看重随机事件发生的频率。与之对比,贝叶斯学派认为概率的目标是将未确定性进行量化,并随着额外数据的出现而更新概率。如果这些概率都延伸到真值,我们就有了不同确定程度的“学习”。













