













百度开放云大数据平台研发经理郭江亮在由51CTO高招主办的“CTO训练营第四课百度技术专场”做了主题为“百度私有云和开放云中的大数据平台”的分享。其内容主要介绍百度私有云中的大规模分布式计算技术和百度开放云中的大数据产品、技术架构以及当前百度对开放云+大数据+行业的一些思考。
目前,百度在云计算和大数据,金融和医疗的结合中均有一些产品思路和经验积累。百度的前几年是做分布式存储,近几年在做分布式计算,比较新兴的像Hadoop。从14年开始,百度推出了在往外孵化出的公有云业务,是类似于阿里云、AWS这样的企业级服务的开放云,公有云是以前百度做内部的风控架构后来扩展做对外的企业服务。
私有云的分布式计算
私有云分布式计算技术栈
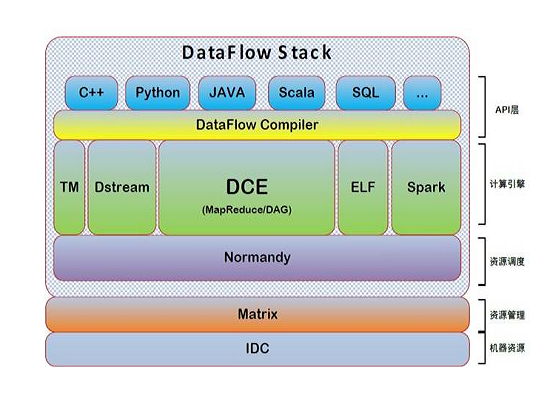
在Matrix的资源调度之上,做分布式计算。分布式计算和底层资源相当于是适配器,这两个结合起来和社区里的对应。往上,是各种计算引擎,离线计算还有实时的。底层资源的两个是实时计算平台。中间是DCE,是一个类似于Hadoop的计算引擎。旁边有ELF的一个平台,最右边是spark。
百度所有机器都已经资源化,把所有的资源管理起来,然后离线,离线是全部已经保存下来。现在百度在逐步做一些在线的业务,因为在线业务和离线业务还是不一样的,所以百度的机房也是在线机房和离线机房分开的。
为什么以前百度都是自研呢?因为百度内部有一些自己的诉求,同时也涉及一些其他问题。百度本身是一个做搜索的大数据公司,它不仅仅是一个数据公司。其所面临的数据挑战非常巨大,超过社区所面对的问题。所以百度一开始也有参考社区的一些思路,但是后面由于需求量又大又快,社区的思路完全跟不上,才开始走上自研的道路。这个相当于是百度整个的技术站。
除了谷歌之外,百度的应该是全球***的一个离线计算集群了,或者离线计算平台。一开始是从Hadoop出来,中间做了很多C++的扩展,因为它要解决很多性能问题。
百度离线计算
- 为百度提供高吞吐的离线计算服务
- 10W+台服务器, 20+个集群,单机群***规模1.3w台
- 日均吞吐百PB级,日均作业数50w+
百度实时计算
- 为百度提供高时效性的计算服务,毫秒级延迟
- 集群规模近1W、应用产品线80+
- 提供通用流式Join解决方案
另一个思路,搭建这些平台还需要相应的技术专家,还需要一些集群资源等网络,以及成本,成本是比较高昂的。但是如果是不想建的话,可以选择公有云,比如说百度开放云。
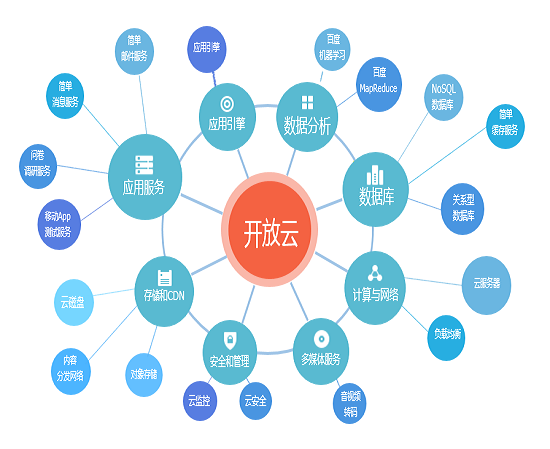
开放云和大数据的平台
百度开放云,可以做数据应用,支撑R+的用户数据,主要对象是一些APP,比如说手机百度、百度地图这些,所有数据也是用统一的收集和处理,所以有多个产品的支撑,有专业的技术专家。
百度开放云产品概览
大数据处理
如果遇到一个数据需求,会有完整的流程规划,从数据的收集到存储,中间可能还有一个传输。从收集、传输、存储,一直到数据的处理变形,到最终的数据分析和应用,是一个完整的流。但是现在的数据和之前的不一样,比如CRM,现在从互联网到移动互联网,数据种类越来越多,对数据的时效性,都有很高的要求。所以如何能快速的收集,并且能够快速的传输,这个也是一个问题。
收集,百度面对原始数据种类多样,格式、位置、存储、时效性等迥异问题,采用的是从异构数据源中收集数据并转换成相应的格式,从而方便做处理。
存储有多种需求,一些行业存在特殊需求,比如说基因行业、基因大数据,做测序。我们一个人的基因数据要测的话,要上很多G,量比较大。还有时效性的要求。像广电是网络的需求,但是广电又有一些网络出来,都是在线的模式。另外还有一个硬盘IP,存量数据的话,硬盘就是比较好用的方式,当然里面有一些数据安全,有一些加密甚至是协议在里面。可能是硬盘快递的方式,把存量的数据全部放上来之后,后续增量的数据,先慢慢的通过公网以后,断电也好,可以慢慢的持续的上升。这个是存储。因为是大数据的处理,所以首先要把它存起来。收集好的数据需要根据成本、格式、查询、业务逻辑等需求,存放在合适的存储中,方便进一步分析。
变形,原始数据需要变形与增强之后才适合分析。比如网页日志中吧IP地址替换成省市、传感器数据的纠错、用户行为统计等等。
分析,通过整理好得数据分析what happened、why did it happen、what is happening和what will happen,多提些这样的问题来帮助企业做决策。
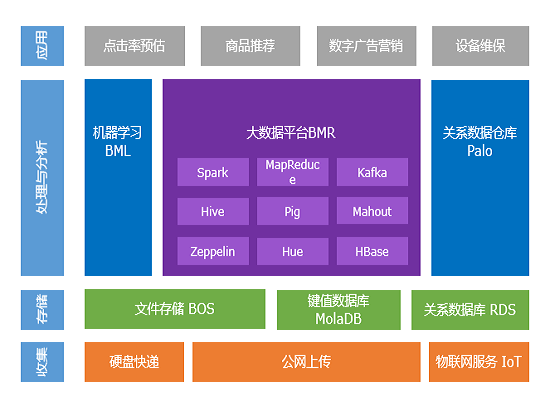
百度开放云大数据堆栈
优势
依托百度技术。百度搜索收录全世界超过万亿网页、承载中国网民每天几十亿次的请求,大数据技术支撑20多个用户过亿产品以及百万企业客户,2013年百度建成全球***的Hadoop集群,2014年百度大数据处理能力BaiduSort获得国际排序大赛冠军。
开源开放。提供开源产品托管服务或者接口完全兼容产品,方便互联网公司和传统企业平滑迁移,用户无需担心被特定平台或者技术绑定。
产品先进。强化开源产品,让开源产品更稳定、更高效、更安全,大大提高成熟度,云端托管服务,让用户聚焦业务而不是修复缺陷和运营,产品在百度内部久经考验,适合企业部署生产环境。
BMR
BMR是Hadoop/Spark托管服务,为方便使用MapReduce、Spark、Hbase、Hive、Pig、Kafka等进行大数据处理,是国内***完全兼容开源Hadoop的大数据服务。有着几分钟便可创建集群,无需为节点分配、部署、优化操心;借助丰富的示例和场景教程,能够快速上手达成业务目标。并且适用集群可大可小,支持动态伸缩,能够有效避免资源浪费;支持计算与存储分离,集群可以处理存放在BOS云存储服务上。完全兼容开源社区版本的Hadoop/Spark,客户可以使用开源标准API边写作业,无需任何修改便可以迁移上云端。集群内的Hadoop、Spark、Hbase等关键组件都支持高可用特性,确保服务可用性。
适用的业务场景有日志分析、数据整理、实时流处理。
Palo
PB级联机分析处理(OLAP)引擎,集稳定、高效、低成本等优势的在线报表和多维分析服务。业界领先的MPP查询引擎、列式存储、智能索引、向量执行;高度兼容SQL标准,并提供库内分析、窗口函数等高级分析功能。数据、元数据多副本存储,宕机期间不影响查询服务,机器故障副本自动迁移。无须停服务即可建立物化视图、更改表结构;支持灵活高效的数据恢复。可视化集群管理,便捷的数据导入;支持标准的SQL操作。
适用的业务场景有联机分析、多维分析、在线报表。
BML
针对海量数据提供的云端托管的分布式机器学习平台,助力客户轻松使用最前沿的机器学习技术获得大数据预测分析能力。基于百度内部积累多年的(包括深度学习)机器学习算法库,国内***个机器学习服务。大同特征功能、模型训练、模型评估和预测服务全流程,拖拽式操作。分布式、全内存集群提供强大的计算能力,海量数据也可以轻松处理。搭载多个分类、聚类、回归、主图模型、推荐和深度学习算法。提供数字广告营销、推荐系统、文本分析、故障检测等多个完善的解决方案,能够使用户快速的把机器学习技术应用到业务系统中。
适用的业务场景有数字广告营销、商品和商家推荐、主题和摘要提取。
现在很多创业公司做公有云大数据平台是比较困难的,因为公有云它是一个数据和应用的结合体,服务器成本、网络成本等等,技术上比较困难,基本上会属于***批。当然体制内的,比如政企的会有一套自己的公有云并不用BAT的。BAT体量的公司来做公有云,或者公有云大数据方面,他们成本是所有的数据。数据将来可能会越来越成为一个资产,也可以说数据的作用会越来越大。每个人可能有每个人的数据,每家小饭馆,或者小公司都有自己的数据,客户数据,营运数据,都可以作为交换发挥价值。
郭江亮认为,公有云大数据平台有很多潜在机会,目前百度数据、公有云也在做,但是因为百度是一个信息的集成的集市,所以在应用这方面还有所欠缺。
















