百度商业安全部资深架构师耿志峰在由51CTO高招主办的“CTO训练营第四课百度技术专场”做了主题为“大数据驱动网络反欺诈”的分享。其内容主要围绕大数据如何作用于欺诈网页展开,分为什么是欺诈网页、大数据分析挖掘和欺诈网页检测三部分。
【演讲人简介】
耿志峰·百度商业安全部资深架构师
耿志峰,百度商业安全部资深架构师。2013年进入百度,从事大数据安全方面的工作,在将大数据技术应用在网址安全扫描、网络反欺诈等方面,具有丰富的经验。
透过经典案例深入了解欺诈网页真面目
案例一: iCloud密码泄漏。在这起案件里,很多美国好莱坞巨星被骗。犯罪分子被擒获后,发现其作案手法非常简单。过程是给受害者发电子邮件,告知其邮件里有很多骚扰邮件,iCloud密码已泄漏,需要马上重置。具体第一步就是要受害者输入原始密码。结果可想而知,很多明星输入导致大规模泄露事件。
案例二:假机票。出行时,需买火车票、飞机票等。当买不到时很多人会去百度搜索,看看有没有其他购票途径。这样就很容易受到卖假票网站的欺骗。
案例三:热门节日中奖诈骗。一个典型案例,我要上春晚节目通知某人中奖,但需要交一定的保护费费就可以领取,之后上当受骗的人不在少数。
耿志峰表示,百度针对欺诈网页做了相对应的应用。当用户搜索网页时,疑似欺诈网页大部分会屏蔽,少部分显现出来的会被标注“风险”字样。有些网站是用户真实想要的,如说博彩,百度把它显示出来,但会告诉用户这是一个风险网站。风险含义包括有诈骗、欺诈、钓鱼,被黑、网页乱码和违法等。
什么是钓鱼网站?就是未经授权,通过模仿第三方网站从而诱导用户采取只有正规网站才能进行的操作,属于社会工程学的范畴。简单来讲,利用用户对某些其他网站的一个信任,然后再盗取用户个人信息,如银行卡、银行卡密码,用户名密码等。
欺诈网站有哪些特点?有模板化、多宿主、时效性和游击战四大特点。
- 模板化。快速繁殖。
- 多宿主。可能存在于不同的国家和地区、不同的机房、不同的服务器、不同的网站。
- 时效性。数据显示,钓鱼网页的平均存活时间为三天,绝大多数的有效时间少于1天。
- 游击战。不同地域不同时间段看到的内容不同,不同时段出现的欺诈内容不同。
耿志峰表示,做黑产的人会对人性加以研究,对技术研究较少。其发布的欺诈网站多为模板化,买一个模板,填一些内容马上生成或用机器去填写生成从而达到快速繁殖的目的。还有很多人来百度做广告,执行开始之前,百度会有非常严格的审查环节。这审查环节也会投入巨大精力。在审核时没有任何问题,就是普通的一个公司官网、ICP备案等都正常。但在特定的时段或者特定的地区,如四川地区在晚上十二点时,内容就会发生这样那样的变化,看到的完全不是之前审核内容,是一个动态的内容。
欺诈网站有哪些分类?虚假信息和知名站点模仿两大类。虚假信息,不去模仿或是投入技术手段做内容,只发布虚假信息。如购物信息(药品、商城)、中奖信息(节日中奖、游戏中奖)、 金融诈骗(小额贷款、信用卡)。知名站点模仿,如模仿京东官网,卖一些东西,用户付款后收钱不发东西。如火车票、飞机票,10086这些都非常典型。其他违法检测(赌博、色情)
大数据特点有哪些?大数据如何分析挖掘?
什么是大数据?指无法在可承受的时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力来适应海量、高增长和多样化的信息资产。

大数据时代三V
大数据的特点。如上图三V:数据量大、数据产生和传输的高速性、多样性。

大数据信息挖掘
大数据分析挖掘。大数据主要应用场景有哪些?可以用大数据做什么?耿志峰在演讲中,主要提到如上图三点。
- 了解现状、把握规律,预测未来。百度旅游热点预测是典型的案例。在刚刚过去的五一非常红,请求量特别大。大家五一想要该去哪儿,去颐和园还是去天安门,百度旅游就会告诉用户根据以往经验或者最近趋势,某个地区热度会达到每立方米一千个人,最好不要去。还有谷歌预测和医疗类疾病诊断等也是经典应用场景。
- 个性化的需求。如在买东西时,逛淘宝会推荐很多店。如买过某件东西的人还买了什么。根据所买产品做从各个维度做对应的推荐。
- 信息识别和过滤准则。垃圾邮件的过滤、虚假评论、刷单属于这一范畴。如百度钱包拉新活动是给用户一个链接,用户拿链接去邀请新同学注册百度钱包。百度钱包就会返现50元。面对利益,就会有人刻意刷单,最高记录显示,某人一天有几十万拉新记录,这就可以利用大数据去建立挖掘。当他在请求时,就可知道其使用环境,如是不是代理、是不是通过IP代理、手机号在运营商是否真实存在、陶宝上是否有号码注册机,有无专门收验证码,都可以把他找出来。
在欺诈网页上如何应用大数据的技术?
欺诈网页检测
欺诈网页检测模型需要四个流程。收集:网址安全信息查询服务、系统:大规模数据处理架构、引擎:大数据+机器学习/深度学习算法、运营:数据分析和可视化。
收集,网址安全信息查询服务。收集就是获取任务,数据来源主要有百度索引(不良或不好数据过滤掉)和API查询(新浪微博、普通浏览器I国际国内涉及反馈网页信息的服务厂商)。百度有大容量KV数据库(几十亿URL Link,近10万的domain) ,每天会有百亿级的有效查询。还有来自搜索/设备/运营商/社交等复杂的场景以及高并发、低延时。
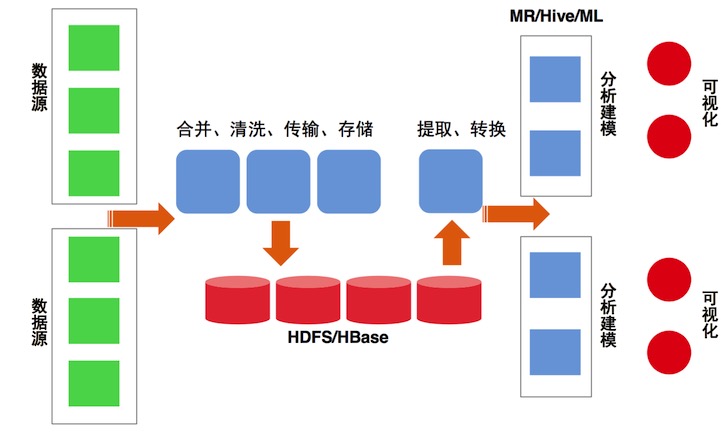
网页数据处理框架理架构
系统:大规模数据处理架构。怎么样来做快速处理的十几亿网页架构呢? 针对大量数据源会先做合并、信息传输和存储。生成任务后,输入模型来提取,转化成模型需要的方式,最终用模型来尽快来检测,达到可视化呈现。
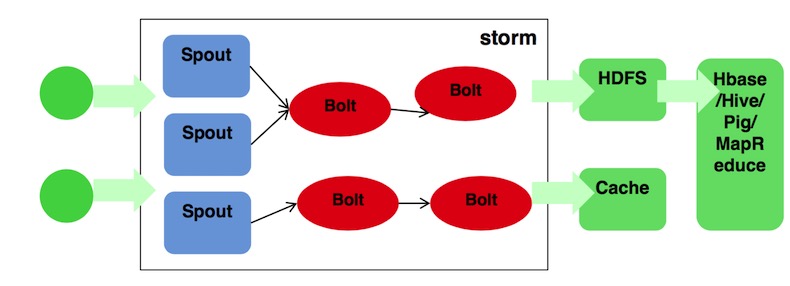
模型工作流程
模型是工作一个典型的storm,在实时计算方面会非常的有优势。存储是HDFS。
引擎:大数据+机器学习/深度学习算法。怎么样去鉴定一个网页到底是不是一个欺诈网页呢?
大数据+机器学习算法神经网络设计示意图
如上图,是一个内神经网络设计示意图。 耿志峰表示,就是把众多的原子拆分成非常细的纬度,把各个纬度进行组合,这就是深度学习的精髓。通过反复组合,组合成一个有意义的组织,输入到模型中训练。架构引擎在设计时就是把原子纬度提出来,进行合并,和基于训练数据基础上的某个模型进行合作,最后再输入模型。
大数据+机器学习/深度学习算法的历程
Rule Based(基于规则),是最早也是最有效的一个方法。基于规则的优势是上线快,准确高,容易理解。缺点是依赖于人,工作量比较大、容易受到干扰和召回低。侯选规则自动推导,线性模型/树模型进行文本特征选择、Word Embedding进行特征词扩展和聚类、关联规则和共现频率进行类目内的规则发现。
Nearest Neighbor Based(基于相近),是从历史挖掘高质量具有代表性的样本,提取框架和文本特征,进行相似度特征匹配。优点是上线速度快,准确率高高。仿冒类效果较好,但关键词规则不能较好的表达仿冒特征、结构和内容相似。
Model Based(基于模型),对大量数据进行挖掘,提供和清洗训练样本,针对亿级别的训练样本,提取扩展千万的特征。之后利用大规模机器学习和深度学习平台进行模型训练,深度神经网络优化的多分类模型,这中间用到Paddle/Caffe框架来处理一些问题。优点是有准召率高、预测效率高、善于发现新模型、从海量数据中总结规律、模型非常稳定、还有能力同时应对多个分类。
Topological Based(基于拓扑),针对图论进行检测,利用URL间跳转关系构造有向图,获得千万节点,亿级边。这样就可更抽象和高层的视角把握黑产规律。优点是掌握黑产品质的规律,让受攻击的影响降到最小。可以分析欺诈的源头,对恶意URL传播源头进行定位,对恶意种子节点标注,对恶意的网站进行排名。
运营:数据分析和可视化。运营意义在于把信息鉴定出来,对某个网址对全局进行了解。如某个地域网站更容易是一个欺诈网页。数据分析是对存有100M黑样本的样本库进行建设和完善,对离线数据挖掘发现样本,做特征归类。建立Ad-hoc查询接口,完成友好交互界面。对欺诈进行分布,如地域分布、用户人群、时间序列分析(预警)等。数据可视化呈现是科学与艺术的完美结合,是建立在数据分析基础上的。在大数据环境下辅助探索和理解问题,使得统计结果如趋势、分布等得到很好的展示。样本可以聚类呈现,如恶意网页地域分布、域名所在地、受害用户所在地等。
演讲接近尾声时,耿志峰表示,我们的生活方式越来越多,导致欺诈的手段层出不穷。大数据能够有助于我们把握规律,进行合理预测,做到安全智能化。当然副作用也很明显那就是隐私问题。其实最有效的方法还是网民自己提高安全意识。