本文是WOT2016互联网运维与开发者大会的现场干货, 新一届主题为WOT2016企业安全技术峰会将在2016年6月24日-25日于北京珠三角JW万豪酒店隆重召开!
卢学裕的演讲分为小米数据工场的技术架构和小团队如何玩转大数据两部分,从中开发者可以知道小米数据工场的技术架构是怎样的? 面对大数据的技术纷繁复杂,小团队要如何面临缺技术/缺分析师/缺数据等问题?在这种现状下如何做好技术选型,如何权衡面临的使用成本和数据隐私担忧?卢学裕主张一半自建一半用云,然而这又要面临哪些运维挑战?
小米数据工场的技术架构
卢学裕表示, 小米数据工厂跟各家的大数据平台、数据系统有很多类似之处也有自己独特的点。工厂整个底层基础平台建立在Hadoop体系,除此小米跟Cloudera合作也非常紧密。小米整个底层平台会有专门平台组去开发,***用的HDFS,上面用的Hive、Spark和Mapreduce这些是混合到一个亚运集群上。Impala小米很早就在用,是一个很重的计算角色。
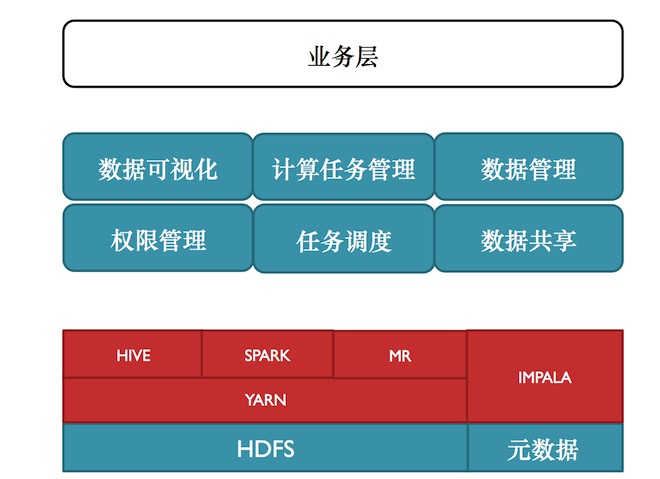
小米数据工场总体结构
如上图, 上半部分是自研的数据工厂,是为最顶业务层提供服务的。数据工厂主要是提供数据可视化、计算任务管理、数据管理、权限管理、任务调度、数据共享等服务。卢学裕表示,公司越大就更希望数据能够开放给公司的各个部门,数据可相互利用。但不能没有任何限制的去使用,所以需要对数据权限做管理。任务调度是整个工厂里面最重的部分。数据共享就是类似非常火的用户画像类数据,还有其他公共数据如IP库,这些数据具有公共特点,就不用重复计算,就可以通过数据共享的方式在各个团队之间使用这些数据。
数据管理,分为数据预览、元数据、数据源三部分。数据预览是每个团队用来互相了解数据的。
元数据,就是数据使用过程中要把非结构化的数据转换结构化的数据。元数据管理就是去了解每个字段的含义和机器解析。机器解析包括Mapreduce程序可直接读文件可解析,如用Impala、Spark和Hive同样也能解析,而不需要每个使用者再去格式化,再去解析这个数据。但面临的问题是数据一旦出现格式的转变或者某些字段的调整,以前任务可能都会出现问题,故一定要统一管理的地方。数据源,数据管理非常核心的是数据集成,能够把各个地方的数据集成到平台上来。
HDFS目录管理。有公共数据空间、业务数据空间、团队数据空间、个人数据空间、Yarn计算空间五部分。
- 公共数据空间,是用来把公共数据放到上面,把维护权限和读的权限分开。这样大部分都是读这个空间,空间数据安全性等级相对来讲比较低,可以付给更多人。
- 业务数据空间,因为每个业务数据的增长量是不一样的,甚至有些业务会出现如刚上来一个新功能,数据量迅速的增大,有的甚至会出现某个团队的数据增加,导致把整个集群空间全吃掉,又没有事先招呼。这种情况下做好业务间的限额配额是非常重要,防止某一个团队的增长导致整个集群出现一些问题。
- 团队数据空间,就是把权限控制到个人,用来帮助做团队之间的数据协作。如把线上任务会放到团队账号中去,团队账号的权限要做好控制,权限不随便开放。团队人员发生变动后,整个团队任务不用再去切换账户而导致交接的复杂性。
- 个人数据空间,数据工程师、开发工程师等是需要做一些调试或做自己的计算这就要给这些人一定空间的同时对其数据做配额。这是为了防止这些人过多的使用资源和为了空间不够需要清理数据时,哪些数据要清理,哪些数据不能清理一目了然。这样限制空间的情况下,这种废文件或者垃圾文件的积累会相对较少。
- Yarn计算空间,做配额限制呢是为了杜绝空间滥用的问题。卢学裕举例道,“之前发生过一件事,某人在Reduce里面写了一个死循环,不停的输出数据,导致整个集群很快就去报警。后来才发现这个计算造成的一些问题,***差点导致那些日志上传、数据的写入都出问题,幸亏处理的比较及时。”所以,Yarn计算空间是需要做一个配额限制,防止对整个集群造成过大的影响。
卢学裕表示,小米数据存储格式统一采用的Parquet,优点在于其使用的是列式存储,支持Mapreduce、Hive、Impala、Spark和读取快占用空间少。

客户端数据接入两种模式优劣势
客户端数据接入。客户端指的是如说Wap、App等数据,存在方式有SDK和服务端Log两种模式。上图为两种模式的优劣势。
服务器端数据源。除前端数据源外,整个处理数据时还会有大量服务器端数据源需要处理。业务数据库类,用ETL工具做导入。服务器端日志,用Scribe将数据写入HDFS。
元数据管理。当公司业务变多后,每一个数据的处理方式都有可能不一样,这时候就凸显出元数据管理的重要性。如视频播放日志,分析师希望用Hive,用Impala直接写SQL去计算,但数据挖掘工程师就要去写Mapreduce,写Spark的方式去读,去解析。元数据管理就是要做数据统一,既能够满足Hive、Spark、Impala,还能满足Mapreduce。这样一来节省大家对数据理解、执行的时间。
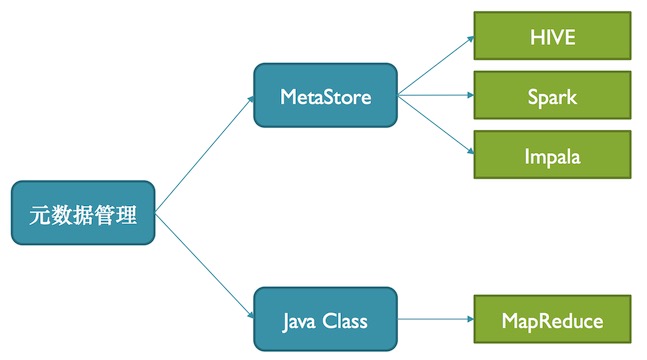
元数据管理
如上图,小米数据工厂是每一份数据的描述都需要在数据工厂上提交,之后数据工厂会在MetaStore中做建表的同时带上元数据的行为,供Hive、Spark、Impala使用。数据管理还会生成Jave Class,给Mapreduce使用。当去解析用某个数据时候,可以直接用这样的方式把它解析成Jave类。

计算管理
计算管理。卢学裕表示,计算是很重要的事情,数据管理相对来讲是一次性的活,计算就是很复杂的事情。计算任务数一天达到几千或过万时,就会变得非常复杂。对于计算管理这快优化,小米做了如上图的一些工作。
Docker。为了管理好这些纷繁的计算框架和模型,在计算的执行方面,小米使用Docker来解决对环境的不同需求和异构问题,并且与Hive、Impala、Spark这些不同的计算模型都进行了对接,去适配不同应用场景计算不同数据的模型。另外,在不同业务场景下,同一个计算逻辑也可以选用不同的计算模型,Docker 的使用也避免了资源的浪费。比如一个计算任务每天凌晨运行,为了追求吞吐量,可以放到Hive里跑;还是同样一个计算模型,现在就要跑,可以不用更改,就放到Impala里运行。Docker不仅解决了环境的异构,也解决了资源问题。另外,Docker的环境适应性很强,做横向扩展会比较容易。对于数据隐私方面,小米考虑得非常重。采用Docker与自身安全策略的综合,小米用户数据的隐私和安全性也得到了极其严格的控制。
小团队如何玩转大数据
小团队玩大数据会面临哪些问题?小团队会面临人力资源不足,技术储备不足,时间有限等问题。面对这些问题,卢学裕在技术选型上给出如下三个建议。
- 选择热门技术。因为人才比较多,相对获取这样人才会比较容易。技术成熟,因为小团队没有时间去踩坑。还有帮助多,这如说网上文档帮助、社群帮助,朋友帮助等。
- 够用。针对一些小团队或者初创公司的特点,业务变化特别快,也不稳定,这种情况下做到够用就好,不需要过分的设计和采用过重的系统。尽量根据业务驱动,业务需要什么数据就抓什么数据。
- 演进。随着需求的变化需要不断的演进,包括系统演进、使用方式演进。
一定要做好数据积累。卢学裕表示,无论你用什么样的技术,用Hadoop也好,不用Hadoop也好,一定要做好数据的积累,这是对一家数据公司非常重要的部分。这就需要提前规划好数据,还要避免逻辑孤岛。还需要注意ID问题,也就是关联的问题。当采集了数据,却发现没有采用户ID,没有提前做好这个规划,当算到用户级别时候那就尴尬了。
演讲***,卢学裕强调:“现在越来越多业务都回到了用户时代,以前讲的是流量时代,讲的是PV如何。回到用户时代,核心问题就是我们要做好用户的数据积累,尤其是用户模型建立。模型包括的画像、用户点点滴滴行为等。这些行为在业务发展之后,尤其是要做数据挖掘,做推荐系统时,会非常非常的有帮助。建议大家做好这样的数据积累,在数据技术上随着变化可以不停的再做一些改变,甚至做一些混合,在不同的地方用不同的方式。
演讲视频:http://edu.51cto.com/lesson/id-100757.html
讲师简介:
现任火线数据创始人兼CEO,前小米科技小米云团队,负责小米数据工场。之前担任优酷土豆大数据团队技术总监,打造了优酷土豆的大数据开放平台、数据分析、数据挖掘、推荐系统等。最早服务于腾讯客户端安全团队做技术开发。