本文是WOT2016互联网运维与开发者大会的现场干货,新一届主题为WOT2016企业安全技术峰会将在2016年6月24日-25日于北京珠三角JW万豪酒店隆重召开!
关于本次的技术分享,主要是游戏行业运维体系的介绍,侧重于游戏行业的运维体系的构建。
第一部分,37游戏的运维体系
马辰龙总结道,公司从创业到后面的上市基本会经历四个阶段。
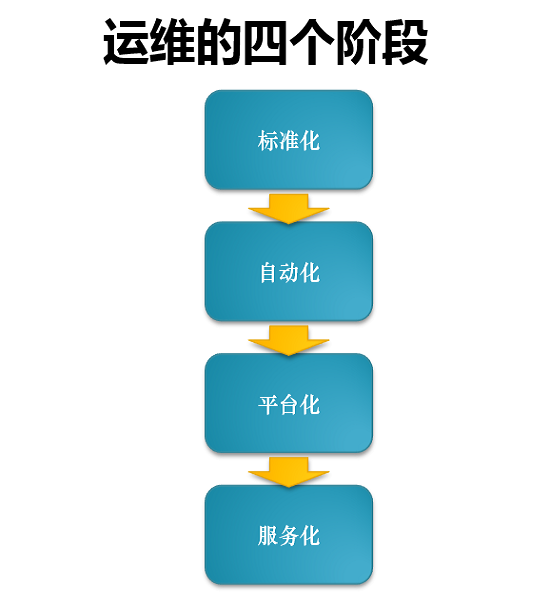
第一个阶段就是标准化。标准化的意思是把主机名、内网以及配置文件统一起来,如果不统一,后面的东西就无法继续。没有一个标准化的环境,脚本是无法写下去的。
第二个阶段是自动化。中小型企业阶段都是自动化到平台化的过渡,平台化就是把自动化的东西分装,把功能整合,把数据做聚合,然后放在平台上来可视化。
第三个阶段是平台化。以后的趋势是脚本和功能必须是外部化的,这样新来的一个人才能接手。不用在服务器上跑脚本,还要同下个人交代在哪儿装。
最后一个阶段就是服务化。服务化是指现在云平台所承载的东西。举个例子,搭一个redis集群,用户不需要知道服务器有多少个,因为所提供的NOSQL服务打开后,用户就可以直接使用了。
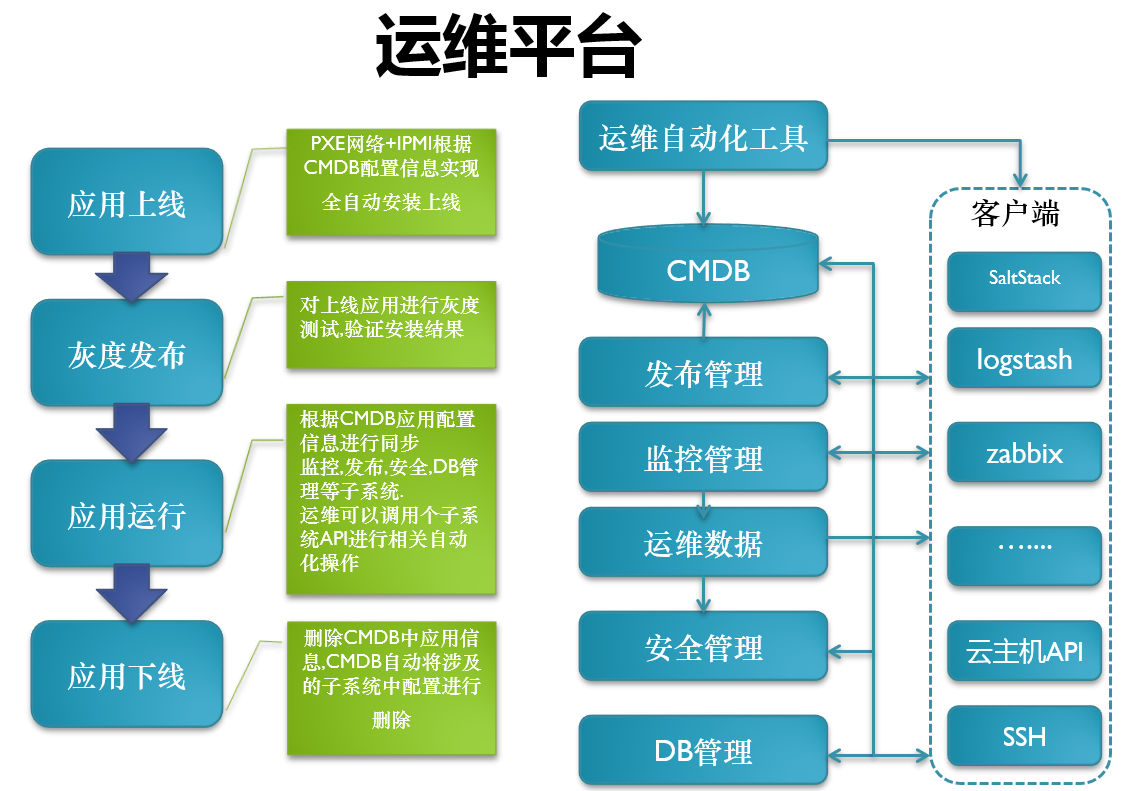
37游戏的自动化工具。37游戏所有的重点数据都在CMDB当中。公司刚开始建立的时候发布是很头疼的事情,虽然利用SVN来提交,但是没有一个自动化的发布流程。运维的重点工作是监控,监控做好,运维就会清闲许多,因为大部分的时间都在接收短信告急。很多公司只知道运维是给开发打杂的,熟不知有了运维数据,便可以推动业务的发展。安全管理。如果在大公司里面的话,有专业的团队做安全管理,跟运维是分离的。如果是在中型企业的话,安全管理是跟运维在一个部门的,二者是离不开的。最后一个是DB管理,DB是37游戏相关的关系型数据库,NOSQL和集群的管理。
客户端的分类。服务器操作类就是用SaltStack做Agent,然后用日志收集logstash,API需要的数据可以利用zabbix监控获得。
应用的上线。应用上线,灰度发布,应用运行,应用下线,这四点贯穿在运维平台里。举个例子,配置一个wab服务,wab服务首先是应用去安装,从CMDB拉数据,再进行灰度发布,然后开始上线,使用到最后下线, CMDB自动将涉及的子系统中配置进行删除。
CMDB是运维里开始最麻烦的,其实最主要是理清关系,然后信息关联。在这里简单地分了几类,比如域名库、软件库、资源库、IP库、配置库,这些建立起来的话,CMDB必须是可维护性的,建立这些模型之初一定要想到它的可维护性,没有可维护性后面的数据会很乱从而自动化就不用谈了。DB管理、安全管理、监控管理。DB管理分为DB部署、DB监控,里面是关于数据的操作,权限的一些划分。安全管理就是安全规则管理。
第二部分,监控、日志数据智能分析。
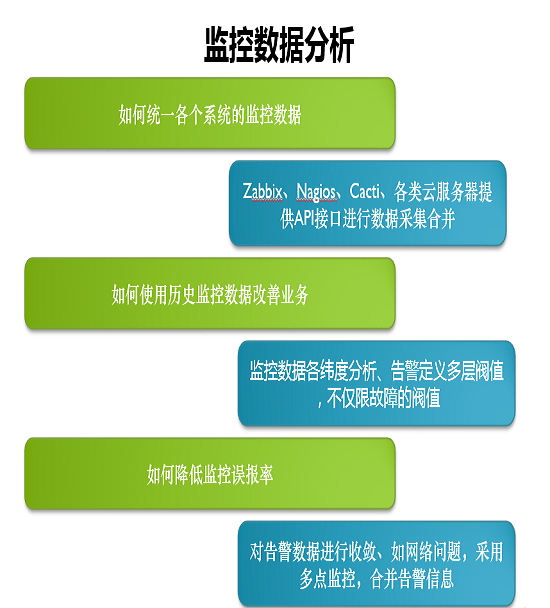
监控数据,因为平台众多,所以怎么统一这些数据?37游戏有Zabbix、Nagios、Cacti各种云资源服务器的管理数据,通过API拿到这些数据。Zabbix应该是支持所有的去、增、长、改、查。Nagios其实本身是不支持API的,但可以从它的配件文件里面把数据抓过来。Cacti可以从页面上抓下来,这些都有一些实践。只要云服务商是比较可靠的云,也就可能提供API接口。
如何改善我们的监控业务,我们的监控数据从各维度分析,告警定义,就是多层阈值。
还有一个是降低误报率,运维每天可能收到一百条短信,大概九十条都是误报。
马辰龙举了一个例子:怎么样用我们的监控数据去推动业务?运维的工作并不是仅仅处理告警了,也需要推动业务的进程。游戏行业的环境是相当复杂的,37游戏有自己的IDC机房去存放游戏。所有的东西都是通过接口去取,再把监控数据汇总到历史监控数据里。根据天、周、月,和系统应用、网络等其他维度生成一个报表。值得注意的是,所得数据不是实时的,而是监控历史数据,因为用实时分析的话,只能是一个告警。之所以判定服务器出现问题,肯定是根据周期性的平均告警率达到多少,平均的使用率低于一定阈值了,才会判定有问题。阈值需要同运营定义。
Web日志的应用。场景就是安全人员需要运维定期的推送一些异常日志,进行XSS注入分析。游戏行业遇到最多的就是被撞库了,每天都在不停的刷账号,刷密码。这个事不光是在游戏行业,在其他行业也会遇到。
37游戏制订了一个目标,运维负责相关业务日志统一汇总,需要有标准的API查询接口。现在所有跟跨部门合作,或者同其他人合作都是通过API。安全人员可以自己定义Web过滤规则,写正则,对异常日志做分析,然后确定攻击类型,采取相应的措施。各平台有日志的实时汇总,如果是集群的话,则服务器是分片的,只是每一台去统计防护失常,或者PV、UV的东西,很难全局性地去判断。因为经典的架构就是前面ALVS,把它分散到下面的服务器,数据需要先合并,也需要聚合,肯定要花费很大、很长的时间。
拿到数据可以根据用户的地区,优化服务器区服的配置和用户体验。游戏的区域性是很强的,可以根据IP进行精准定位。
37游戏用的是互联网比较经典的架构ELK。logstash收集日志,队列用redis,放到redis里面,然后logstash再取,放给ElasticSearch,最后去存储。建立初期可以直接用图形化,用Kibana做图形化视图的分析。中间的redis只是充当一个队列,但是架构是不变的,所以上手是非常之快的。如果有开发运维的话,直接可以从Lsearch里面把日志分析出来。web端用自己的过滤规则。如果有问题就扔到黑名单里面,业务在前端做逻辑控制。
第三部分,故障自愈。
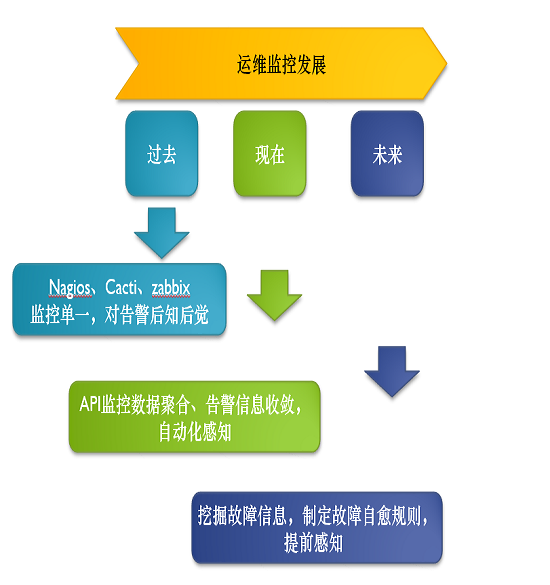
现在大部分中型的企业都有自己的API,监控数据的聚合,告警数据的收敛,很多做自动化。这些做起来并不是很难,关键是在做未来的时候,去挖掘故障信息,去制定自己的故障自愈规则。
其所面临的问题就是系统网络,业务层面自生的逻辑造成的一些异常,监控误报还有监控自身的一些可靠性。还有非自愈业务,因为故障自愈不是万能的,就像现在的人工智能一样,有些东西是机器代替不了的。比如说复杂的业务场景,可能机器是没办法判断的,可能有些东西是需要人工看,才能知道应该怎么处理。
37游戏所有的告警信息都是发送到告警信息处理中心的,比如说的短信告警,这些都是经过信息统一推送。
这里马辰龙分享了一个实例,搬到任意一个场景下都可以应用。用自己的Zabbix监控或者somkeping监控甚至第三方监控,获取监控信息。然后把所有的监控信息全部推送,推送到回调队列里面去,然后去分析这个告警信息。

故障自愈能带来什么呢?非工作时间可以处理自己私人的事情,运维第一个要求就是24小时要待命。减少直接对线上的操作,比如出现了故障,直接去操作线上,很有可能会出现二次故障。所以必须要从故障原因里面分析,锻炼运维人员对工作的积极性,并不是每天都是鼓噪的东西。长远看来,对玩家,对公司利益,以及自身价值都将有显著的提升。

最后马辰龙总结了一点:一定要在自己的领域有独特的解决方案。
“有很多开源方案是不能直接用的,必须要用到自己的生产环境当中,有自己的一些解决方案。运维工具的设计要很简单,因为要考虑下一个接手你的东西的时候,维护成本有多高。敲过代码的人都知道,重写会比维护代码好很多。所有的东西都要以业务为核心,一旦脱离了业务,你做的数据其实并没有什么用。最后要说的是,好的架构是演化来的,不是设计出来的。”马辰龙讲到。
本文整理自,由51CTO传媒主办的WOT2016互联网运维与开发者大会上来自37游戏运维架构师马辰龙主题为《游戏行业运维自动化与故障自愈》的精彩演讲。
演讲视频:http://edu.51cto.com/lesson/id-100749.html
讲师简介:
马辰龙,负责37游戏运维平台开发,目前专注游戏行业运维自动化,监控系统故障自愈,擅长perl开发,正则表达式,日志精确匹配。