前言
前些天帮公司做了网络层的重构,当时就想做好了就分享给大家,后来接着做了新版本的需求,现在才有时间整理一下。
之前的网络层使用的是直接拖拽导入项目的方式导入了AF,然后还修改了大量的源码,时隔2年,AF已经更新换代很多次了,导致整个重构迁移非常的麻烦。不过看着前辈写的代码,肯定也是一个高人,许多思路和我的一样,但是实现方式又不同,给我很好的参考。
在做网络层架构的时候也参考了Casa大神的架构思想,但是还是有所不同。
本文没有太多的理论,没有太多的专业术语,一来是方便大家阅读,二来我的基础也没那么好,没有太多华丽的词汇,对于架构来说主要是思路,有思路在,具体的实现就没有问题了。
本文主要介绍以下几点:
1.网络接口规范
2.多服务器多环境设置
3.网络层数据传递(请求和返回)
4.业务层对接方式
5.网络请求怎么自动取消
6.网络层错误处理
无Demo无文章,Demo下载:https://github.com/SummertimSadness/NetWorkingDemo
网络接口规范
demo里面的请求示例是在网上找的,不符合我说的这套规范,仅作示例用
规范很重要,有合理的规范就可以精简很多代码逻辑,特别是接口的兼容,是最底层最基础的设计,把接口规范放在前面来说
在做这次重构时,我提出了一些规范点,可以给大家参考
1.两层三部分数据结构
接口返回数据第一次为字典,分为两层三部分:code、msg、data
- "code": 0,
- "msg": "",
- "data": {
- "upload_log": true,
- "has_update": false,
- "admin_id": "529ecfd64"
- }
-
code:错误码,可以记录下来快速定位接口错误原因,可以定义一套错误码,比如200正常,1重新登录...
-
msg:接口文案提示,包括错误提示,用来直接显示给用户,所以这一套错误提示就不能是什么一串英文错误了
-
data:需要返回的数据,可以是字典,可以是数组
接口帮我们定义了code和msg,是不是我们就不需要做错误处理了?当然不是,服务端的错误逻辑毕竟是简单的,具体到data里面的数据处理可能还有错误,所以错误的处理是必不可少的,下面会单独对错误处理做介绍
2.网络请求参数上传方式统一
这里一般都能做到,也有额外的,比如我们的一个服务器接口做的比较早,当时POST接口使用的就不规范,普通的应用信息channelID、device_id使用的是拼接在字符串后面的方式,而真正的请求参数则需要转成json放在一个字段里面传递,就是接口GET、POST并存的方式,造成网络层需要做特殊处理
所以说标准的GET、POST请求方式是很有必要的
3.关于Null类型
大家都知道Null类型在iOS里面是很特殊的,我的建议是放在客户端来做,原因有很多:
1)接口的规范定义并不是每个公司都是从一开始就能定义好的,老接口如果要把Null字段去掉的改动非常大
2)客户端用过一个接口过滤也可以解决,一劳永逸,不用再担心因为某天接口的问题出现崩溃,而且通过一些Model的第三方库也可以很好的解决这个问题。这里不得说下swift的类型检测真是太方便了,之前一个项目用swift写的,代码规范一点,根本不会出现因为参数类型问题引起崩溃
多服务器多环境设置
这部分基本上是照搬casa大神的设计,这里我延伸了一个多环境的设计,小的项目一般都是一个服务器,但是像淘宝之类的项目一个服务器显然是不可能的,多个服务器的设计还是非常普遍的。根据一个枚举变量通过ServerFactory单例生成获取对应的服务器配置
1.服务器环境
标准的APP是有4个环境的,开发、测试、预发、正式,特别是服务器的代码,不能说所有的代码更改都在正式环境下,应该从开发->测试->预发->正式做代码的更新,开发就是新需求和优化的时候的更改,测试就是提交给测试人员后的更改,这个时候更改是在一个新的分支上,完成后要和合并到测试分支上并合并到开发分支上,预发这时候的变动就比较小了,一般会在测试人员完成后发布给全公司的人来测试,有问题了才会更改,更改后同样合并到开发分支,正式则是线上发布版本的紧急BUG修复,修改完后同样合并到开发分支上。所以开发分支是一直都是最新的。在此基础上可能会有其他的环境,比如hotfix环境,自定义的h5/后台本地调试的环境。
客户端同样存在这些环境,并且要提供切换的入口。
在我的demo中提供了两套设置,一套是第一次安装应用的初始化环境(宏定义),另外是手动切换环境的设置(枚举EnvironmentType)。这里有一个比较绕的逻辑,宏定义的正式环境设置高于手动切换环境设置,手动切换环境设置高于宏定义其他环境
- //宏定义环境设置
- #if !defined YA_BUILD_FOR_DEVELOP && !defined YA_BUILD_FOR_TEST && !defined YA_BUILD_FOR_RELEASE && !defined YA_BUILD_FOR_PRERELEASE
- #define YA_BUILD_FOR_DEVELOP
- //#define YA_BUILD_FOR_TEST
- //#define YA_BUILD_FOR_PRERELEASE
- //#define YA_BUILD_FOR_HOTFIX
- //#define YA_BUILD_FOR_RELEASE //该环境的优先级最高
- #endif
- //手动环境切换设置
- #ifdef YA_BUILD_FOR_RELEASE
- //优先宏定义正式环境
- self.environmentType = EnvironmentTypeRelease;
- #else
- //手动切换环境后会把设置保存
- NSNumber *type = [[NSUserDefaults standardUserDefaults] objectForKey:@"environmentType"];
- if (type) {
- //优先读取手动切换设置
- self.environmentType = (EnvironmentType)[type integerValue];
- } else {
- #ifdef YA_BUILD_FOR_DEVELOP
- self.environmentType = EnvironmentTypeDevelop;
- #elif defined YA_BUILD_FOR_TEST
- self.environmentType = EnvironmentTypeTest;
- #elif defined YA_BUILD_FOR_PRERELEASE
- self.environmentType = EnvironmentTypePreRelease;
- #elif defined YA_BUILD_FOR_HOTFIX
- self.environmentType = EnvironmentTypeHotFix;
- #endif
- }
- #endif
所以当宏定义正式环境存在的时候是不能手动切换环境的,用于普通用户的发布版本,但是其他宏定义环境时是可以切换到正式环境的。
半个坑
另外手动切换自定义的环境是在基类中实现的,而其他的环境配置是在协议中实现的,这就和其他环境地址的配置不统一了。
可以这样理解,这里的基类是为了提供已返回值,协议是为了返回值的灵活,既然自定义环境的地址配置不需要灵活性,自然是放在基类好。思路是大方向,实现是灵活的,如果非要放在协议中实现也无不可以,无非是赋值粘贴几次一样的代码,但是一模一样的代码是我最不喜欢看到的,所以就放在基类了。如果有更好的解决方案欢迎提供
2.扩展性
model提供的是高扩展性,针对不同的不服务器添加更多的配置,比如加密方法,比如数据解析方法...前面提到了,统一的规范有的时候不是一时半会就能做好的,兼容就成了需求,这个时候不同服务器的个性化设置就可以在协议中声明并实现了,基类提供返回值就好
网络层数据传递(请求和返回)
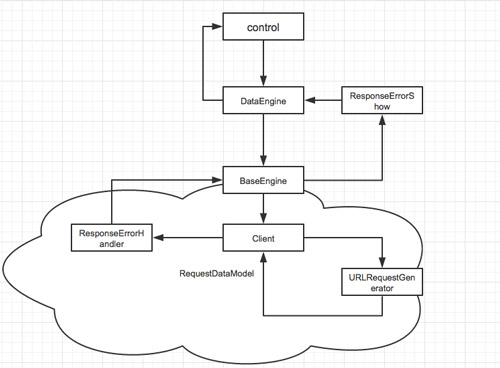
网络层数据传递
Client、BaseEngine/DataEngine、RequestDataModel数据传递
网络请求的发生在我理解中分两步,一步是数据的整理,一步是生成Request并发起请求,基于这个思想我拆分出了Client和Engine,然后又把URLRequestGenerator从Client中拆分出来,Engine拆分出了下层的BaseEngine和面向不同业务的DataEngine,
而从BaseEngine到Client,再到URLRequestGenerator是要做数据传递的,请求参数和返回参数,所以又有了RequestDataModel
RequestDataModel
- @interface YAAPIBaseRequestDataModel : NSObject
- /**
- * 网络请求参数
- */
- @property (nonatomic, strong) NSString *apiMethodPath; //网络请求地址
- @property (nonatomic, assign) YAServiceType serviceType; //服务器标识
- @property (nonatomic, strong) NSDictionary *parameters; //请求参数
- @property (nonatomic, assign) YAAPIManagerRequestType requestType; //网络请求方式
- @property (nonatomic, copy) CompletionDataBlock responseBlock; //请求着陆回调
- // upload
- // upload file
- @property (nonatomic, strong) NSString *dataFilePath;
- @property (nonatomic, strong) NSString *dataName;
- @property (nonatomic, strong) NSString *fileName;
- @property (nonatomic, strong) NSString *mimeType;
- // download
- // download file
- // progressBlock
- @property (nonatomic, copy) ProgressBlock uploadProgressBlock;
- @property (nonatomic, copy) ProgressBlock downloadProgressBlock;
- @end
可以看出来RequestDataModel属性都是网络请求发起和返回的必要参数,这样做的好处真的是太大了,不知道大家有没有这样的场景:因为请求参数的不同做了好多方法接口暴露出去,最后调起的还是同一个方法,而且一旦方法写的多了,最后连应该调用哪个方法都不知道了。我就遇到过,所以现在我的网络请求调起是这样的:
- //没有回调,没有其他的参数,只有一个dataModel,节省了你所有的方法
- [[YAAPIClient sharedInstance] callRequestWithRequestModel:dataModel];
生成NSURLRequest是这样的:
- NSURLRequest *request = [[YAAPIURLRequestGenerator sharedInstance] generateWithYAAPIRequestWithRequestDataModel:requestModel];
可以看到我的demo里面的YAAPIClient类和YAAPIURLRequestGenerator类方法至少,方法少就意味着逻辑简单明了,方便阅读,两个类的代码行数都是120行,120行实现了网络请求的发起和着陆,你能想象吗
另外RequestDataModel带来的另外一个好处就是高扩展性,你有没有遇到网络层需要添加删除一个参数导致调用方法修改了,然后很多地方都要修改方法?用RequestDataModel只需要添加删除参数就行了,只需要改方法体,这个改方法体和同时改方法名方法体是完全两个工作量。哈哈,有点卖虎皮膏药的感觉。这个的确是我的得意创新点
Client
Client做两个操作,一个是生成NSURLRequest,一个是生成NSURLSessionDataTask并发起,另外还要暴露取消操作给Engine,
URLRequestGenerator是生成NSURLRequest,URLRequestGenerator会对dataModel进行加工解析,生成对应服务器的NSURLRequest
然后Client通过NSURLRequest生成NSURLSessionDataTask
Client和URLRequestGenerator都是单例
- - (void)callRequestWithRequestModel:(YAAPIBaseRequestDataModel *)requestModel{
- NSURLRequest *request = [[YAAPIURLRequestGenerator sharedInstance]
- generateWithRequestDataModel:requestModel];
- AFURLSessionManager *sessionManager = self.sessionManager;
- NSURLSessionDataTask *task = [sessionManager
- dataTaskWithRequest:request
- uploadProgress:requestModel.uploadProgressBlock
- downloadProgress:requestModel.downloadProgressBlock
- completionHandler:^(NSURLResponse * _Nonnull response,
- id _Nullable responseObject,
- NSError * _Nullable error)
- {
- //请求着陆
- }];
- [task resume];
- }
取消接口参考了casa大神的设计,使用NSNumber *requestID来做task的绑定,就不多做介绍了
BaseEngine/DataEngine
Engine或者说是APIManager在我的设计中既不是离散的也不是集约的
casa大神的理论
集约型API调用其实就是所有API的调用只有一个类,然后这个类接收API名字,API参数,以及回调着陆点(可以是target-action,或者block,或者delegate等各种模式的着陆点)作为参数。然后执行类似startRequest这样的方法,它就会去根据这些参数起飞去调用API了,然后获得API数据之后再根据指定的着陆点去着陆。比如这样:
- [APIRequest startRequestWithApiName:@"itemList.v1" params:params success:@selector(success:) fail:@selector(fail:) target:self];
离散型API调用是这样的,一个API对应于一个APIManager,然后这个APIManager只需要提供参数就能起飞,API名字、着陆方式都已经集成入APIManager中。比如这样:
- @property (nonatomic, strong) ItemListAPIManager *itemListAPIManager;
- // getter
- -(ItemListAPIManager *)itemListAPIManager
- {
- if (_itemListAPIManager == nil) {
- _itemListAPIManager = [[ItemListAPIManager alloc] init];
- _itemListAPIManager.delegate = self;
- }
- return _itemListAPIManager;
- }
- // 使用的时候就这么写:
- [self.itemListAPIManager loadDataWithParams:params];
各自的优点就不说了,但是由此延伸出几个问题:
1.参数的传递使用字典对于网络层来说是不可知的,而且业务层需要去关注接口字段的变化,其实是没有必要的
2.离散型API会造成Manager大爆炸
3.集约型会造成取消操作不方便
4.取消操作并不是每个接口必须的,如果写成部分离散的部分集约的,代码的整体结构...我是个有强迫症的人,看不得这样的代码
所以我的设计主要就解决了上面的这些问题
1.面向业务层的DataEngine只传递必要的参数进来,不使用字典,比如
- @interface SearchDataEngine : NSObject
- + (YABaseDataEngine *)control:(NSObject *)control
- searchKey:(NSString *)searchKey
- complete:(CompletionDataBlock)responseBlock;
- @end
control暂时先不管,是做自动取消的,后面再介绍。
searchKey就是搜索的关键字
在调用的时候就是这样
- self.searchDataEngine = [SearchDataEngine control:self searchKey:@"关键字" complete:^(id data, NSError *error) {
- if (error) {
- NSLog(@"%@",error.localizedDescription);
- } else {
- NSLog(@"%@",data);
- }
- }];
2.我按业务层来划分DataEngine,比如BBSDataEngine、ShopDataEngine、UserInforDataEngine...每个DataEngine里面包含各自业务的所有网络请求接口,这样就不会出现DataEngine大爆炸,像我们的项目有300多个接口,拆分后有十几个DataEngine,如果使用离散型API设计,那画面太美我不敢看??
3.BaseEngine提供取消操作
每个接口生成一个BaseEngine实例,持有Client返回的requestID,所以就可以做取消操作,简单的使用场景
- #import "ViewController.h"
- #import "SearchDataEngine.h"
- @interface ViewController ()
- @property (nonatomic, strong) YABaseDataEngine *searchDataEngine;
- @end
- @implementation ViewController
- - (void)viewDidLoad {
- [super viewDidLoad];
- // Do any additional setup after loading the view, typically from a nib.
- [self.searchDataEngine cancelRequest];
- self.searchDataEngine = [SearchDataEngine control:self searchKey:@"关键字" complete:^(id data, NSError *error) {
- if (error) {
- NSLog(@"%@",error.localizedDescription);
- } else {
- NSLog(@"%@",data);
- }
- }];
- }
- @end
4.返回的YABaseDataEngine实例ViewController不是必须持有的,当有需要取消操作的时候再去持有就行了
这样的设计就集成了集约型和离散型的有点,又解决了集约型和离散型的缺点
网络请求怎么自动取消
当一个页面的请求正在天上飞的时候,用户等了好久不耐烦了,小手点了个back,然后ViewController被pop被回收。此时请求的着陆点就没了。这是很危险的情况,着陆点要是没了,就很容易crash的。
casa大神说在BaseDataEngine的dealloc里面做取消网络请求操作,我也是这样想的,但是casa大神说要把BaseDataEngine绑定给ViewController,当ViewController销毁时BaseDataEngine也就跟着销毁了,这样我也是同意的,但是要让我不管什么情况都要给ViewController添加BaseDataEngine变量来保存BaseDataEngine这是我万万不能接受的,而且有的ViewController会发起两三种网络请求,难道要我添加两三个变量?代码入侵太大,所以这里偷偷使用了一个巧,使用了runtime,给ViewController添加一个字典,来保存requestID和BaseDataEngine,这样对于ViewController来说就不是必须要写变量来持有BaseDataEngine了,所以就出现了上面的DataEngine里面要把control传递进来的样子
在发起请求的时候进行绑定
- [control.networkingAutoCancelRequests setEngine:self requestID:self.requestID];
在请求完成的时候进行删除
- [weakControl.networkingAutoCancelRequests removeEngineWithRequestID:engine.requestID];
公司上个大神的做法
虽然使用control的做法很方便,但是如果说要把现在已有的接口都添加一个control字段的工作量也是很大的,如果已有的接口是使用字典传递给DataEngine的,这里给大家一个公司上个大神的做法,使用内存地址,将内存地址添加到字典中去,用内存地址做key绑定,也是可以的。如果是像我这样直接把关键参数传递过来的,不是用的字典,就不行了。
- NSString *memoryAddress = [NSString stringWithFormat:@"%p", self];
网络层错误处理
说实话,错误处理该放在按个地方我也是纠结了好久,也和公司同事讨论了好久,最终定下来了一套方案,仅供大家参考。
我们将错误处理分为两个步骤,一个是错误解析,一个是错误的UI展示
大家可以看到我设计的接口返回数据是标准的id data, NSError *error,所以我的想法是Client就把error处理好,不管你是网络超时错误也好,或者是数据格式不正确也好,都error解析完整,把code错误码定义好,上层根据需要通过code来做具体的UI展示,因为有的界面的错误需要用户的点击确认,有的页面的错误只是一闪而过的提示框,把error交给BaseEngine或者DataEngine来处理errorUI,所以我定义了一套errorUI的枚举,当BaseEngine拿到error的时候就去做错误的展示
总结
架构的设计更多的是思路,我希望的是大家能通过我们提供的思路取其精华去其糟粕,总会设计会最适合你的项目的架构的
另外我的这套设计存在的争议的点可能会有很多,有一部分我已经在文中提到了,如果大家有什么其他的想法我们再讨论
1.关于block
对于block和delegate的选择,我更倾向于block,只有一个原因,因为block的结构更方便阅读,这一个优点我觉得足以秒杀他所有的缺点,可以这样说,我现在的项目基本上很少用到delegate了。
什么时候自定义delegate?就是当你的不同时期的回调超过2次的时候(不包含2次),3次回调就看情况了,如果要处理的逻辑比较少就使用block,多的话就使用delegat,一旦超过3次,基本上就不会考虑block,希望大家也不要对block存在偏见,延迟生命周期什么的都是可以解决的,一个宏定义就解决了,顺便给出strongSelf,如果这么方便的宏都不愿意使用,那是真的不适合用block了,谁也救不了你
- #define WEAKSELF typeof(self) __weak weakSelf = self;
- #define STRONGSELF typeof(weakSelf) __strong strongSelf = weakSelf;
2.交付什么样的数据给ViewController?是model还是data
这个有什么好争议的吗?有DataEngine在,交付什么样的数据还不是你说了算。
底层的BaseEngine和Client当然还是data比较合适,到了DataEngine层,你想交付什么样的数据就交什么样的数据,可以看业务层的需求,有的接口根本就不包含model,你非要统一所有的接口都返回model这不是扯淡吗,所以我的建议是根据接口的实际情况来,统一规范,我们的设计因为有些接口是不需要model的,以后就统一返回data
3.优化
我的这套设计只是基本思路,还有很多优化的点,我知道。
这部分就是各显神通的地方了,不是我藏私,而是现在的项目对于网络层没有太多的优化点,所以我也没做太多,做的部分敏感代码太多,实在是没办法拆出来,不过可以告诉大家一个小的优化点,errorUI的处理可以考虑做成队列,比如需要用户点击确定的弹出框,而且内容都是一样的,放在队列里面只显示一次就好
4.为什么业务层没有使用RequestDataModel
model就是对象,下层主要是用来做数据传递的,用model没有问题;而向上到业务层的时候,更多的理念是方法的调用,而且方法的定义更有针对性,这个时候用model就不合适了。就好像超市一样,进货的时候是使用集装箱拉货的,所有的东西都装在一起,当到柜台的时候就会一个个的分类摆好。