如何做好数据科学呢?
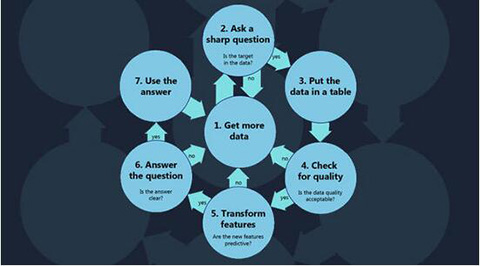
微软高级数据科学家 Brandon Rohrer 概括了做数据科学的七大步骤,手把手教你做数据科学。
1. 获取更多的数据
数据科学的原材料是数字和名称的集合,测量、价格、日期、时间、产品、标题、行动等,数据科学无所不包。你也可以使用图像、文字、音频、视频等复杂数据,只要你能将它们简化为数字和名称。
获取数据的机制可能非常复杂,事实上,数据工程师就像忍者一样。不过,本篇文章将主要聚焦于数据科学。
2. 问一个尖锐的问题
数据科学是通过数字和名称组成的数据集合来回答问题的过程。你问的问题越精确,越容易找到令你满意的答案。在选择问题的时候,想象你的面前是一个可以用数字或字段来告诉你宇宙中一切奥秘的圣人,他的回答总是模糊不清、令人困惑,而你希望问一个精准而无懈可击的问题,让他忍不住告诉你问题的答案。
模糊的问题如“我的数据能告诉我什么?”、“我应该做什么?”我怎样提高利润?”会带来无用的回答,而清晰的问题如“第三季度我能在蒙特利尔卖出多少产品?”、“我车队中的哪一辆车会先坏?”会带来清晰的答案。
在有了问题后,要看你的数据是否能够回答这些问题。如果你的问题是“我的股票下周的价格是多少?”,那就要确保你的数据中有股票的历史价格;如果你的问题是“ 88型航空发动机能够工作多少小时?”,那就要确保你有多台 88 型发动机故障次数的数据。这些就是你的 目标数据 (target) ,即你希望在未来预测或布置的量或种类。如果你没有任何目标数据,需要回到步骤 1 ,获取更多的数据,因为没有目标数据则无法回答问题。
3. 将数据置于表格中
大部分机器学习算法假设数据以表格的形式呈现,每行是一个事件、项目或实例,每列是行数据的一个特征或属性。在一个描述美国足球比赛的数据集中,每行可能代表一场比赛,列可能包括主场队、客场队、主场得分、客场得分、日期、开始时间、出场情况等等。表格中的列可以非常细致,有多少都可以。
将数据集分割成行有许多方法,但只有一种方法能帮助你回答问题:每行有且只能有一个目标实例。以零售店数据为例,一行可以是一次交易、一天、一个零售店、一个顾客等等。如果你的问题是“刚进过店的顾客会回访吗?”,那应当以一个顾客作为一行,你的目标“顾客是否回访”将呈现在每行,而如果以一个零售店或者一天作为每行的数据则不能回答目标问题。
有时你必须通过累积数据来获得需要的数据。如果你的问题是“我每天卖出多少拿铁咖啡?”,那你需要的数据是以天数作为行、卖出的拿铁数作为列,但是你手头的数据可能是带有日期和时间的交易记录。为了将这些数据变为每天的数据,需要对目前的数据进行累积,将每一天卖出的拿铁数进行合计。在这个过程中,有些信息会丢失,例如每杯拿铁卖出的时间,但没有关系,因为它不会帮助你回答问题。
4. 检查数据质量
下一步是认真地排查数据。检查数据有两个目的:***,发现错误数据,修复或去除;第二,充分了解每一行每一列。这一步不能跳过,否则无法让数据发挥***功效。只有你对你的数据表示出爱,它才会爱你哦 ~
以一列数据为例,它的标签是什么?数值与标签匹配吗?标签对你来说有意义吗?这一列数据有记录吗?是怎样测量的?谁来测量的?如果你幸运地认识录入数据的人,不妨约他们出来吃甜甜圈,问问他们是怎样测量的,问问他们录入中有没有有趣的故事,这一顿点心会给你带来回报的。
现在,让我们把用这一列画一个柱状图。整体分布符合你的预期吗?是否有异常数据点?异常点是否有意义?例如,如果这一列代表的是农业分布的经度,有没有一个数据点落在太平洋中?如果这一列是关于考试分数,是否有人的分数是 1% 或者10000% ?用你所知的一切对数据做一个监测,如果有的数据看起来有些奇怪,找出为什么。
校正
在排查数据中,你可能发现一些标签和记录的错误,记录并分享你的发现。
你也可能发现一些值是错误的。一些值可能超过了正常范围,比如一个人竟然 72 米高,或者有些值是不可能出现的,例如一个写成“中心路 7777777777 号”的地址。这种情况下,你有三个选择:如果这个值很容易更改,那就改为正确的值,例如把高 72 米改成 72 英寸;如果错误的值不明显,你可以删掉这个值、注明缺失;如果这个值是关键信息,你可以删除整行或者整列。这样可以让你训练的模型远离错误数据。错误数据可比缺失数据危害更大。
你可能很想移除看起来不理想的数据,例如异常数据或者不支持你的理论的数据——但千万别这样做,否则不仅违背学术伦理,更可怕的是可能会导致错误结果。
替换缺失值
几乎每一个数据集都存在缺失值,可能是由于数值错误被删除了,也可能是你在实验途中去测量了一个新的变量,还可能是这些数据来自不同的数据源。但不管什么情况,大部分机器学习算法要么要求数据无缺失,要么会用默认值填充。而你可以比机器做得更好,因为你了解你的数据。
替换缺失值有很多方法, 处理缺失值的方法 一文 提供了一个办法,而***的处理办法取决于每一列的意义和数值缺失带来的影响,每一个数据集的情况可能都有所不同。
替换完所有的缺失值后,你的数据们现在已经“连上”了,每一个数据点对每一个特征都有意义。现在,这些数据是干净的、可以拿来用了。
有时候你可能发现,在数据清理后,几乎没有剩余的数据了……这是件好事情,因为你刚刚避免了走上用错误的数据建立模型、得到错误的结论、被客户嘲笑、激怒老板的不归路 …… 如果是这样,那就回到***步,从头获取更多的数据吧!
5. 变换特征
在进入机器学习之前还有一步:特征工程 (feature engineering) ,即对现有特征数据进行创意组合,以更好地预测你的目标。举个 ,如果我们把火车到达和出发的时间相减,可以得到火车的运输时间,这个特征对完成目标即预测火车的***速度更加有用。
严格来讲,特征工程并不会增加任何数据信息,只是使用各种方法对原有数据进行组合。然而,仅仅对两栏的数据进行组合就有***种方式,而大部分组合方式对解决目标并没有什么帮助。通常情况下,只有在对数据有充分了解的情况下才可能选出一个好的方式。你需要充分调用你所有的相关知识,让数据为你所用。
特征工程是数据科学中最微妙的一步,没有一成不变的办法,而是要不断试错、依靠直觉和经验。深度学习试图让这个过程自动完成,但大多以失败告终,也许这就是人类智能的特别之处吧。
不过,即使你还不是特征工程的黑带高手,也有一个可以使用的小技巧。你可以根据你的目标,用不同的颜色标识变量,这可以帮你发现变量之间的关系。这可能工作量较大,不过你一定要花些时间过一遍。每当你发现有两个变量与目标相关,那可能就是一个特征工程,意味着这两个变量结合在一起可能比孤立来看更有帮助。
有时候,你会发现你的数据中没有任何变量或变量的组合能够帮你预测目标,这可能意味着你需要测量一些其他变量。那么,重回***步,获取更多的数据吧 !
6. 回答问题
终于到了数据科学家***的部分了 —— 机器学习!简单地说,你需要 确定你的问题属于哪种算法 ,然后 ,使用传统的机器学习技巧来分割数据进行训练、调整、测试数据集、根据选择的模型优化参数。
如果你的模型无法很好地解决问题,或者你不想用机器学习,还有两种非传统的方法:
***种,简单地看一下你的数据图像,很多情况下,只要对数据进行可视化就能找到答案。例如,如果你的问题是“波士顿明年 7 月 4 号的***气温是多少?”,那么只要看一下过去 100 年间波士顿每年 7 月 4 日***气温的直方图就基本可以解决问题了。
第二种方法技术含量更高一些。如果你是因为数据集太小而得不到结果,你可以考虑进行优化。机器学习基于弱先验假设,也就是说,机器学习对数据结构做一些较弱的假设。这种方法的优点在于使用算法之前不需要对数据有太多了解,它能够训练出一些大致的模型,而缺点在于需要大量数据才能获得一个可信的答案。一个替代方法是根据你对数据的了解,对数据做更多的假设。例如,如果你想预测一个物体的飞行轨迹,你可以收集大量物体自由落体的数据,用它们训练机器学习算法。你其实还可以用你了解的牛顿力学知识来制作一个更丰富的模型。这样,只需要一个包括位置和速度的数据点就可以预计这个物体在未来任何一点的位置和速度。这种方法的风险在于你的假设可能不完全正确,但优点是你不需要大量的数据就能完成任务。
如果这些办法对你都不适用,也许意味着你需要收集更多的数据,或者重新思考一下你测量的数据。回到***步,获取更多数据吧 ~
7 .应用答案
不管你如何优雅地用数据回答提出的问题,你的工作直到有用户使用才算完成。将你的结果以某种形式呈现给用户,用户可以用它做决策、完成任务或进行学习。展示的方式有很多:你可以将结果放在 web 页面上,把你发现的最有用的信息呈现在 PDF上,可以在 GitHub 上分享你的代码,可以把结论做成视频分享给你的商业客户,可以制作美观的数据可视化成果发在 Twitter 上,等等。不管采用哪种方式,要让其他人使用你的成果。
森林中的一棵树倒下,即使附近没有人听见,仍然会有响声,但如果你建造了一个精良的模型却没人用,你肯定不会得到赞誉。
那么就从头开始吧,回到***步,获取更多的数据!