作为新的开源数据流分析方案,Apex脱胎于DataTorrent的RTS平台,能够带来出色的速度表现并简化编程要求。
说起数据流分析任务,我们首先想到的自然是Spark。尽管Spark已经凭借着2.0版本将非结构化与结构化两类数据的分析能力融为一体,但Storm的1.0版本解决了自身难于使用的问题。
诞生于2015年6月的Apache Apex可谓横空出世,其同样源自DataTorrent及其令人印象深刻的RTS平台,其中包含一套核心处理引擎,仪表板、诊断与监控工具套件外加专门面向数据科学家用户的图形流编程系统dtAssemble。
作为RTS平台的核心处理引擎,Apex可以说是DataTorrent献给Apache的又一份大礼。Apex的设计目标在于运行大家的现有Hadoop生态系统,并利用YARN实现按需规模伸缩且通过HDFS实现容错能力。尽管其并不像RTS平台那样功能全面,但Apex已经足以提供大家希望数据处理平台所能实现的多数主要功能。
Apex应用示例
下面我们来看一套基本Apex流程示例,其中将涉及多项核心概念。在本示例中,我们将读取Kafka中的日志条目,对日志记录类型进行计数并将其写入控制台当中。相关代码片段将实际列出,大家也可以点击此处获取GitHub上的完整应用。
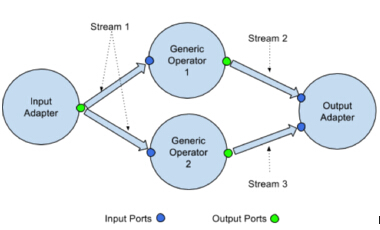
Apex的核心概念在于operator,其属于Java类,负责实现输入信息接收与输出信息生成。(如果大家熟悉Storm,那么其作用基本类似于bolt与spout。)另外,每个operator还会定义一组用于数据输入或输出的端口。该方法的实际作用在于读取来自InputPort的输入信息,或者通过OutportPort向下游发送数据。
通过operator的数据流将进行建模,即将数据流拆分为基于时间的数据窗口——但与Spark的microbathcing不同,Apex中的输入数据处理无需等待窗口结束即可开始进行。
DataTorrent
在以下示例中,我们需要3个operator,它们各自对应三种Apex所支持的operator类型中的一种:输入operator负责由Kafka读取信息条目,通用operator负责对日志类型进行计数,而输出opeartor则将其写入控制台。对于***种与第三种,我们可以直接使用Apex的Malhar库,但在第二种中我们需要使用定制化业务逻辑以对查看到的不同日志类型进行计数。
下面来看我们的LogCounterOperator代码内容:
public class LogCounterOperator extends BaseOperator {
private HashMap counter;
public transient DefaultInputPort input = new DefaultInputPort() {
@Override
public void process(String text) {
String type = text.substring(0, text.indexOf(' '));
Integer currentCounter = counter.getOrDefault(type, 0);
counter.put(type, currentCounter+1);
}
};
public transient DefaultOutputPort> output = new DefaultOutputPort<>();
@Override
public void endWindow() {
output.emit(counter);
}
@Override
public void setup(OperatorContext context){
counter = new HashMap();
}
}
这里我们使用简单的HashMap进行日志类型计数,同时定义2个端口以通过该operator实现数据流处理:其一负责输入,其二负责输出。在输入过程中,不兼容operator将引发编译时失败。需要注意的是,虽然我在这里只定义了1个输入端口与1个输出端口,但大家也可根据需要定义多个端口。
通用opeartor的生命周期非常简单。Apex会首先调用 setup()以进行任何必要的初始化操作;在以上示例中, setup()负责完成HashMap的创建工作。其随后调用beginWindow()以声明新的输入处理窗口/批量任务正在开始,接着在整个过程中对各数据条目调用。如果当前窗口的剩余时间归零,Apex则会调用endWindow()。我们不需要任何针对单一窗口的逻辑,因此将BaseOperator中的beginWindow()定义留空即可。然而,在每个窗口的末尾,我们都需要发送当前计数结果,从而将HashMap通过输出端口进行发送。
与此同时,经过重写的process()方法负责处理我们的业务逻辑,即从日志行中提取***个词并更新计数器。***,我们调用teardown()方法,从而保证Apex流程得到必要的清理——本示例其实并不需要清理,但出于演示的考虑,我们将清理HashMap。
现在我们的operator已经创建完成,接下来需要构建流程本身。如果大家熟悉Storm拓扑结构,那么应该能够轻松理解以下代码:
public void populateDAG(DAG dag, Configuration conf) {
KafkaSinglePortStringInputOperator kafkaInput = dag.addOperator("KafkaInput", new KafkaSinglePortStringInputOperator());
kafkaInput.setIdempotentStorageManager(new IdempotentStorageManager.FSIdempotentStorageManager());
LogCounterOperator logCounter = dag.addOperator("LogCounterOperator", new LogCounterOperator());
ConsoleOutputOperator console = dag.addOperator("Console", new ConsoleOutputOperator());
dag.addStream("LogLines", kafkaInput.outputPort, logCounter.input);
dag.addStream("Console", logCounter.output, console.input);
}
我们首先定义DAG(即operator)节点。之后,我们定义图形边界(在Apex词汇中称其为‘stream’)。这些stream负责将某一operator的输出端口接入另一opeartor的输入端口。在这里,我们将Kafka接入LogCounterOperator,并将输出端口接入ConsoleOutputOperator。工作完成!如果我们编译并运行该应用,则能够在标准输出结果中看到HashMap:
{INFO=1}
{ERROR=1, INFO=1}
{ERROR=1, INFO=2}
{ERROR=1, INFO=2, DEBUG=1}
…
Malhar: 丰富的实用组件
Operator的***优势在于其体积小巧且经过明确定义,因此能够轻松实现构建与测试。其接合方式类似于乐高积木——惟一的区别在于乐高积木是现成的,但operator需要我们自行创建。
Malhar就像是一个巨大的乐高积木桶,其中旋转有大量标准的2 x 4基本件供大家使用。无论是读取Splunk,在FTP站点上合并文本文件信息还是将结果存储在HBase当中,Malhar都能帮助我们实现。
有了Malhar提供的丰富operator组件,Apex就变得***吸引力,这意味着我们只需要设计业务逻辑即可。有时候Malhar operator的说明文档比较粗糙,但该库中的一切都配备有测试机制,因此我们可以轻松查看不同组件间的协作效果。
Apex还提供其它一些出色的设计成果。除了常见的指标与报告方案外,dtCli应用允许我们以动态方式变更运行时中的已提交应用。大家是否希望向HDFS当中添加一些负责写入日志条目的operator,但又不希望影响到应用的整体运行?Apex能够轻松完成这项任务。
开源数据流处理引擎已经相当丰富,但要在其中脱颖而出则绝非易事。随着Malhar库提供的庞大opeartor选项以及Apex自身所具备的出色容错能力、低延迟以及可扩展性,Apex已经成为一款速度出色且可用于生产环境的理想框架。
在这里,我建议DataTorrent为Apache Beam开发一套Apex运行器,从而帮助开发者们更轻松地将自己的应用从现有框架中移植出来。当然,Apex目前已经相当优秀,足以成为值得大家认真考量的数据流处理引擎。
原文链接:Look out, Spark and Storm, here comes Apache Apex