【51CTO.com快译】Apache的流数据处理系统携手Spark,旨在进一步提升性能水平并改进调试功能。
大数据专家们在讨论Apache Spark与Apache Storm之间的流数据处理能力时,往往给出共识性的结论:Storm确实拥有更好的规模化能力与速度表现,但使用难度较高。另外,其正在逐渐被Spark所取代——因此选择更新且更为热门的Spark往往成为主流观点。
有鉴于此,Apache Storm 1.0版本希望重新扳回一城——其不仅进一步提升了速度表现,还大幅降低了使用难度。
Apache于4月公布了Apache Storm 1.0版本,并表示新版本较上代方案“***提速16倍”,且延迟水平降低60%。“对于大多数用例而言,用户都能够享受达到前代版本3倍的性能表现。”
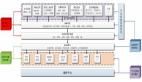
此次新版本进行了一系列战略修复以实现上述性能改进,具体包括将数据与特定Storm方案相关联的新型分布式缓存API,或者所谓“拓扑”——其规模可达数GB,并在不同节点之间实现共享且利用命令行进行更新。换言之,管理员不再需要以手动方式对各个节点进行重新部署。另外,该数据提取自本地文件系统,但亦可被存储在Hadoop HDFS当中。
新版本还引入了新的批量处理方法,其同样实现了可观的速度提升,但延迟却仅仅略微增加。
1.0版本中的大部分改动都使得Storm更易于使用。在Storm的早期版本中,调试机制通常要求用户编写定制化“bolts”(处理功能)以提取实时数据。而在1.0版本内,用户能够直接截取Storm全部流量中的1%作为样本,并通过UI进行查看或者保存在磁盘中以备后续查询。同样的,1.0版本还提供新的日志搜索功能,允许用户对Storm管理节点的完整拓扑进行日志搜索。
Storm面临的竞争压力并不单纯来自Spark,而且其性能与易用性指标也都遭受到挑战。Apex项目作为一套数据流框架——亦被称为DataTorrent RTS——号称能够实现“10到100倍”于Spark的数据流处理速度,且开发与部署难度低于Spark以及Storm。
原文标题:Apache Storm 1.0 packs a punch
【51CTO.com独家译文,合作站点转载请注明来源】