Apache HBase是一个面向线上服务的数据库,其原生支持Hadoop的特性,使其成为那些基于Hadoop的扩展性和灵活性进行数据处理的应用显而易见的选择,近几年在全球得到了快速发展。
对任何一款数据存储产品进行评价时,高可用性(HA)都是一个核心的考量指标,也是核心业务应用的先决条件。然而硬件故障、断网断电以及诸多不可预料的故障时刻都在挑战着HBase的高可用性。从2011年开始,阿里就开始了在HBase上的应用研究和探索之路,目前已拥有上万台HBase集群规模。经历过近五年时间的大量业务锤炼,阿里HBase在性能优化、功能完善、高可用性改进等方面,都积累了大量经验。
在WOT2016互联网运维与开发者大会现场,51CTO记者独家专访到阿里巴巴集团技术保障部系统工程师肖冰,探寻阿里HBase高可用性改善方面的技术细节。
嘉宾简介
肖冰,阿里巴巴集团技术保障部系统工程师,入职以来一直从事阿里HBase集群的一线运维工作,负责保障整个阿里集团HBase集群的稳定性和高可用。承担HBase大促核心业务单元化改造、MTTR落地、混合存储落地等重要工作。
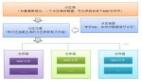
肖冰介绍,阿里HBase团队的职责分工主要为两个方向,一是运维团队,主要帮助阿里内部的各业务方制订存储方案,并负责后期的稳定护航;另外是HBase源码开发团队,主要是做代码层的HBase优化,提升HBase整体性能。这两支队伍紧密合作,基于阿里巴巴自身业务场景和特点,对社区HBase进行深度定制与改进,从解决方案、稳定护航、发展支撑方面为集团内部的各业务部门提供一整套完善NoSQL服务。
阿里HBase主要用于存放大量线上关键业务的数据,比如我们常用的支付宝钱包中用户帐单、消费记录、通讯录联系人、在淘宝购物时卖家向买家发送的物流详情等数据。总的来说,Hbase面向的都是大数据量、大吞吐,并且存储和读取相对简单的业务。它的优势在于服务能力能够快速水平扩展,并且单集群就可以支撑上百万甚至上千万的TPS、QPS。
阿里HBase集群高可用之路
阿里Hbase的运维监控集中在两个层面。一是监控报警系统,主要用来监控网络、CPU损耗等集群本身进程的健康状态。另外是对业务层面的监控,也就是根据业务需求在代码里面设置许多信息采集的锚点,来统计某一集群在一段时间的TPS、QPS、网络IO是多少。通过这两个层面监控的配合,来精准定位问题,解决问题。
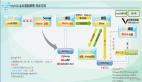
为了使集群可用率达到四个九的标准,阿里HBase主要通过单机故障的快速恢复机制、跨机房跨地域的集群部署以及快速透明的主备切换方式将这些问题攻破。
缩短节点宕机恢复速度
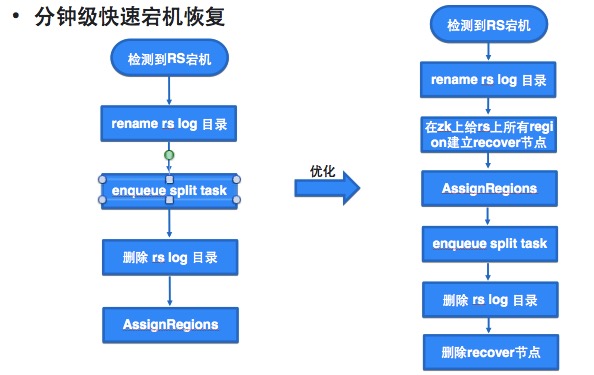
节点宕机、大请求等情况都会直接影响读写请求,威胁集群的可用率。肖冰讲到,他们主要是通过并发的数据恢复,来将整个集群的宕机速度从最初需要一个小时左右的时间,缩短至15、6分钟内,就可以完成200台以上集群从宕机到拉起的动作。
作何一个技术方案从设计到真正落地,都需要进行不断的试错和调优,肖冰他们也是如此。“我们这个业务刚上线的时候,理论上来讲恢复速度应该要比之前的方式要快。但是很多情况下,数据恢复的速度比我们预想的要慢很多,甚至在某些场景下的速度还不如以前。我们需要基于实际情况不断做优化。”
比如说在进行并发数据恢复时,如果对正常的用户请求和恢复数据都执行了写入操作,这两个写入请求就会互相争抢资源,从而导致整个集群的恢复速度被大大拖慢。为了解决这个问题,阿里HBase针对许多细节进行优化,比如设置限定开关,考虑到应该侧重恢复业务数据,所以先恢复写的部分。通过设置开关,外部流量就无法进入集群,从而避免资源争抢对数据恢复的影响;再如针对red buffer设置的优化。写red buffer时,如果red buffer设置过大也可能影响恢复速度。
调度优化解决大请求
大请求是指对系统资源消耗特别大的请求,典型的例子就是带有Filter的Scan,这个Filter过滤掉了大量的数据,导致一个Next操作会访问成百上千个Block。当Block大部分都在内存时,这种Scan就会消耗大量CPU资源。在解决大请求方面,肖冰也给出了两点优化建议:
- 限制大请求的资源消耗,让正常的请求可以获取资源。通过sleep达到目的;
- 中断掉对客户端来说已经超时的请求,这种请求继续运行没有意义。中断请求释放资源。
灾备部署
Hbase现在的集群容灾主要通过两种方式。第一是同城的主备切换的容灾。客户端通过配置ZK集群地址以及Parent Znode访问HBase,为了实现客户端在主备集群之间的无缝切换使用了虚拟Parent Znode(VZnode)代替了物理Parent Znode,VZnode存储的内容就是实际指向的物理Parent Znode,通过VZnode指向不同的物理Node实现客户端在主备集群之间的无缝切换。
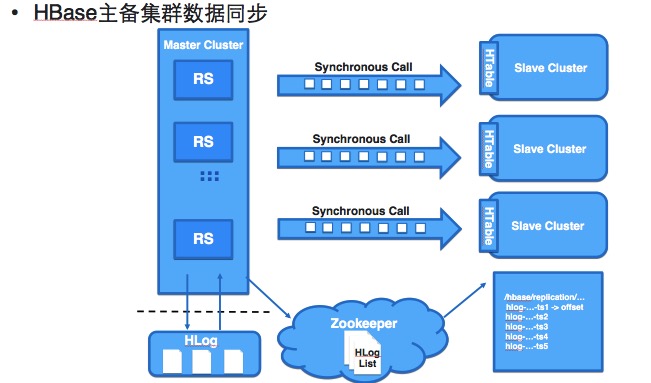
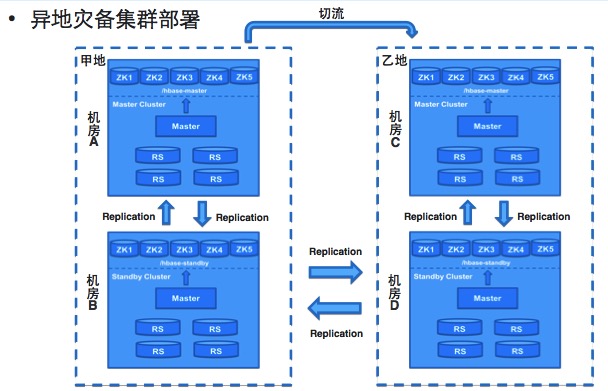
第二是异地的容灾。通过多地的集群部署,多地同时完成数据同步去提供存储服务。
未来的优化方向
采访最后,肖冰与记者分享了未来阿里HBase的优化方向,主要会集中在推动运维自动化及虚拟化部署两个方面。
具体来说,一是将运维变更、资源申请、性能评估等这些日常的运维工作实现完全的自动化动化,提高运维效率。另一方面是把HBase现在由物理机的部署改成虚拟节点的部署,通过虚拟化更好地提高资源利用率,提高资源调动速度。