大数据作为趋势是任何一个企业都逃脱不了的宿命。大数据架构和传统架构有着天壤之别。对于运维人员来说,大数据时代的运维应该从传统运维转变到业务运维中去。然而对业务指标的监控也区别于对机器的监控,对业务的监控和告警方式也千差万别。企业运维人员该如何应对呢?
在WOT2016互联网运维与开发者大会现场,51CTO记者独家专访到极光推送高级Hadoop工程师许俊。让我们通过本文一起了解,他是如何基于业务运维的思维导向,构建极光推送大数据架构下的运维监控告警系统的;在许俊眼中,业务运维与传统运维的理念和实现上又存在着哪些差异。
嘉宾简介
许俊,高级Hadoop工程师,大数据平台负责人。极光推送首位大数据工程师,见证并负责整个极光推送大数据平台的演进,目前负责Hadoop平台,流计算系统、图数据库服务、spark算法平台等基础数据平台。在Hadoop运维开发,大规模分布式计算平台领域有着丰富经验。
可视化的智能运维监控系统
极光推送的大数据平台基于Hadoop集群实现。开始时由于部署在集群上的业务少、数据少,只采用了Zabbix对机器的基本指标进行监控,往往要到第二天接到业务部门的反馈才知道集群出现了问题。
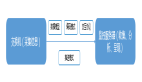
随着业务程序越来越多,越来越复杂,对于指标的监控要求也越来越高。发展到现在,简单的指标监控已经不能满足要求,出现了越来越多的类似 “平均值”、“***值”、“求和” 等更灵活多样的需求。目前,极光推送采用的Grafana+Graphite+Statsd+Cabot这四个组件,构建一套更通用并且功能更丰富的监控系统。Graphite作为整个架构的核心,提供源数据的接收、数据的存储和数据展示功能;Statsd是作为数据的收集和数据的聚合,以及部分的数据负载均衡的操作;Cabot是作为整个系统的告警部分,来对接到极光推送自己的告警系统;Grafana是作为监控系统UI这一层的方案。
问题的监控告警及风险预估
日志收集方面,极光推送主要是用Flume。许俊谈到,Flume除了能把原始的日志收集到ES外,还能将一些不是原始文件的日志对接到Kafka数据中心。另外,通过与Elasticsearch的配合,Flume能非常容易地把数据拉到想要的目的地,而不需要像使用ES时那样,做一些具体的分析和挖掘,非常便于问题的发现。
对于如何进一步挖掘这些日志数据的价值,许俊谈到,他们希望通过对业务指标的监控,及时地发现并处理问题,甚至是对风险进行预盼,这也是做监控和告警的目的。实现这项工作,就需要更加详尽地获取或提供这些业务方面的指标,并将其对接到监控系统里,并通过一些基本功能,让业务方更加直观、方便地掌据自身业务各方面的具体情况,从而有针对性地进行一些优化和改进,比如及时进行扩容、负载均衡等。
以Redis内存为例。传统运维可能更加关注Redis使用内存有没有达到预设值,但通过现在这样的系统,业务方就能够非常轻松地观察到在整个历史时间内,Redis实际占用内存的增长速度和比例。这样系统就能在它达到设置的预值之前发出预警,提前进行扩容方面的工作,而不是等到问题发生的那个时间点,为业务发展起到有力的支撑。
谈及结合业务发展的需求对极光推送大数据架构运维的优化方向,许俊分享到,要整合大数据各组件的通用监控告警系统,实现与调度等系统的结合,从监控、警告的阶段演进为回复和预警。通用监控告警系统就像JVM对于Java一样,可以让业务方基于一些通用的标准或者协议,把资料统一写好,定制好,然后直接与监控系统对接,来减少对各组件运维的重复劳动。
业务运维是对传统运维的有效补充
在采访***,许俊再次强调,对大数据业务的监控与传统的机器和集群监控一个显著的区别是,运维关注的层面更高,关注点更超前,强调在问题出现之前,就去根据一些变化趋势去发现问题,某种意义上来讲,也是对传统运维的一个有效的补充。
建议大家选用一些常见的、通用的运维监控方案,比如基于运维人员非常熟悉的Python语言设计出的一些方案。因为Python的生态圈非常发达,这样一方面可以以非常低的成本去维护和定制我们需要的组件,另外一方面也能够让我们非常容易的找到相应的组件,来满足我们的需求。