2016年4月14-15日,由51CTO传媒主办的WOT2016互联网运维与开发者大会在北京珠三角JW万豪酒店召开。秉承专注技术、服务技术 人员的理念,自2012年以来,WOT品牌大会已经成功举办了八届,积累了大量的技术专家资源,获得了广大IT从业者和技术爱好者的一致认可,成为了业界重要 的技术分享交流平台以及人脉拓展平台。
本次会议分为11个技术主题,分别是:数据库技术与应用,大数据与运维,云计算与运维,运维安全,移动运维,容器体系构建与实践,运维自动化,行业运维、监控与性能优化、高可用架构和分布式存储技术。51CTO作为本次大会的主办方,将以快速报道、现场专访与后期视频等形式展示这场盛宴。
下面是来自Google工程团队带头人李聪先生给大家带来的是主题为《运维理念与实践》的精彩演讲。

李聪,在Google从业七年多,带领开发和维护过多个项目,包括前端、后端、线下作业等。
【以下为现场演讲实录】
大家好,我叫李聪。我自我介绍一下,我工作大概七八年了,主要以开发为主。运维也做过一些,跟最前面的几位不是特别像,但是我今天给大家带来的内容,大家会发现为什么我做以开发为主的,也可以给大家带来一些分享?等一下给大家介绍。
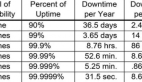
我的内容跟前面有些不一样,这里面基本上不需要大家花钱,所以尽情的听下去。我带来的主题就是运维的理念与实践,主要是比较适合于内部使用。只有一个目标,就是99.9999%。我相信在座大部分都是运维方面的专家,对这个比较熟悉了,我们在做服务的稳定性的时候,最主要谈服务级别协议叫SLA。如果说最重要的一个互联网指标,就是它的可用性有多少,我们把它划为6个级别,第一个级别最低是1个9,它的意思概念化可服务时间是在90%以上,不可服务时间是在10%以下,如果说这个服务能达到1个9以上,它就意味着说你宕机时间保持在36.5天以下,这是很差的服务了,不过事实证明,即使到今天还是有。比如说有一些买火车票的网站,页面一般都用不了,我觉得可能到不了一个9。
每增加一个9,就相当于它的可用性,宕机时间缩到上一级的10%。一般比较重要一点的服务都要到4个9、5个9、6个9,对于重要的服务,我们都是要到6个9的指标,年宕机时间在31.5秒以下。在线时间比较容易理解,用户可以正常使用的时间,宕机时间可能就比较复杂一点,并不是说用户发个请求,发现服务端有错误了,这才叫宕机,这不一定的。比如说我要去打开我的一个Email,本身是几秒钟事情,如果搞到10分钟,这样就可以把它裁定为宕机了。
我现在给大家回顾一下历史,我们的目标很简单,就是要达到6个9。我们是怎么实现的?如果运维不能让我重新来一次,我应该怎么做?我就要回顾一下历史。首先看一下我们软件发展起来是在80年代的时候,那个时候,我们开发流程都还是用瀑布模型,从需求、分析到设计,到开发测试,最后到发布这样一个过程,比较老的一种开发流程了。这里面有一个比较明显的地方,在开发流程里面,前面设计一直到测试完成,在发布之前都是在一个团体,或者说一个公司内完成的,但是当到发布的时候,还是通过比如说光盘这种形式来发布给客户,这种客户包括客户公司,甚至说个人之类的,在这种情况下,产品的开发整个流程到后面的运营是完全分开的,整个开发测试设计的过程,在软件开发公司,运营运维就是在客户公司部分,这两个是完全脱节的。在80年代早期,还没有漏洞这样的一种说法。举个例子,以前有顾客向软件开发公司反映说他们的产品有问题,结果反过来被软件开发公司给告了,说他们这是诽谤,告他们诽谤罪,在今天看来,这是一件很可笑的事情。发布周期一般少则几个月,多则一两年,甚至三年,那时候没有特别激烈的竞争。在那个年代做的开发是一件很爽的事情,今天的开发者不可以想象那时候有多爽。
那个时候软件大部分是在2个9以下,一般都是达到1个9。这里面有一个例子Windows,90年代的时候,Web软件开始出现了,Web软件出现,开发流程依然没有很大的变化,还是以瀑布开发的流程为主的,但是因为它是一个Web软件,开发与运维不是完全脱节的。我本来说是在同一个公司内部的,我做软件开发,我做维护给客户来使用,那时候出现了很多软件。在软件开发公司,一般出现了Ops这样一个组来提供这样一个支持,不过这个时候,他仍然是两个独立的小团体在公司内部,这时候发布周期加快了,一般可以几个月发布一次,到一年的样子。即使到这个时候,做软件开发还是一件比较舒服的事情,因为很多的工作压力,很多的运营的压力都是在运维,开发者相对来说还是比较轻松。在这个时候,很多服务是可以达到2个9的样子。
即使到这个时候,我不知道大家有没有印象,如果说你在办公室里面用一台Windows电脑,有另外一个人走进来开了一下灯,或者关了一下灯,你这个机器可能就宕掉了。到了00年代的时候,软件行业发生了翻天覆地的变化,包括从90年代后期浏览器的竞争,非服务的节点更加稳定。就像路由器更加稳定,如果说服务出了问题,在这之前,往往大家可能会检查一下网络有没有连接,到这个时候,大家比如说上不了网,他可能会到另外一个社群网站看一下这个服务到底有没有问题。
发布更加重要。因为竞争过于激烈,导致了所有的软件公司压力都非常大,他们就要不停的去发布,生产一些新的产品来吸引用户,让用户满意度更强。同时可靠性也增加了,后面我会解释一下为什么。到00年代的时候,竞争加剧了,产品发布周期变短,产品发布压力变大,这个时候开发与运维的矛盾也凸显。你不停发布新的产品,往往就导致了这个产品不稳定性增加,这肯定不是运营商希望的样子,它希望这个产品更加稳定,开发者希望发布发布、再发布,我要一直发布下去,运营商就希望一直稳定下去,所以说这两个角色之间是一种格斗的场景。这时候就出现DevOps这样一个概念,DevOps是一种概念、理论与手段,来促进开发与运营之间更好的合作。
鱼与熊掌是不是可以兼得?我们怎么样去做?我们看一下怎么做的。
首先有人说堆人可以做到,我只要有钱,招更多的工程师,招更多的包括开发运营的工程师,这是绝对不可能的。如果你靠堆人,最多也就做到3个9到4个9,基本上就不大可能了。成套技术也是不可能的,无论这个公司技术有多强,都不可能达到6个9的级别,5个9都很难。这时候就出现了这两个团队之间的矛盾,运营就说想尽各种各样的办法来拖慢发布的速度,开发者就想尽各种办法来加快发布速度。比如说运营的人说我下个月要休假,这个月就开始不要发布了,你就等一等好不好,如果你要发布的时候,我要增加你审查的流程和审查的深度,但是另外一方面开发者就会想各种办法,比如说我这个只是波及到5%的用户没有关系的,或者我只改一个UI,做一个很小的改动,双方就扯皮起来。我们怎么样彻底的解决这种问题?我们引入了一个概念叫做SRE,这样一个角色,跟传统的运维,甚至说今天很多公司运维的概念完全不一样。SRE的工作要来保证产品稳定性,这个并不完全是他的责任。他跟开发者有一个共同目标,开发者也要有责任保证产品稳定性。
怎么做到?大概从四个方面做到,我敢说是缺一不可,只要有一个环节出了问题,都不可能做到。
第一个就是工程方法,做软件开发与发布、运营的工程方法;第二个就是组织架构,可能听起来有点奇怪,组织架构为什么会影响到产品的稳定性,或者说高可用性;再就是管理理念,最后是技术支持,当然技术支持并不是说它是最不重要的,这四个都非常重要,都是关键的因素。
我们先看一下工程方法。我们把服务划为两类,一类是自运营的服务,这个服务只有开发者去开发,再加上开发者去运行,没有SRE的直接参与。当然还是可以得到SRE的间接支持的,但是没有SRE的直接支持,这种服务不是我们讲的重点,这种服务一般达不了6个9,5个9就已经不错了。得到SRE运营直接支持的服务,这种服务我们是有要求的,不是说所有的服务,想达到6个9,你就跟我SRE一起配套工作。
我们这个服务的要求有几个方面,比如说对SRE的负担要小,不能让SRE花很多精力在运营上面,基本上可以解释为这个产品要足够好,才会得到SRE的直接支持。
另外这个服务是要非常重要,比如说6个9还好,如果到5个9,这个产品一年比如说可以损失10亿美元,类似于这样的情况。还有一个有一种法律的要求,这个就没有办法了,如果有法律要求一定要配备SRE的。最后就是说有没有SRE可以供池使用,SRE的资源池有限,我们SRE的数量非常少,相比开发者来说。我们通过错误预算来做,即使是SRE直接支持运营的服务,前期也是至少有6个月开发者自运营的过程,就是说前面6个月,SRE不会直接参与来支持这样一个项目。这个服务自运营6个月以上以后,通过SRE的审查以后,SRE就可以去做直接的支持,当然这支持以后,就会产生一个很快的迭代的过程。比如说每一天发布,比较快的是每天发布,如果说在发布过程中出现了很大的问题,SRE有可能会退出这个团队,说你这个服务不行,我们要把你交回去,仍然由开发者自己去负责。错误预算,刚才简单提了一下。我们首先要有一个概念,就是说影响产品不稳定的最重要的因素是什么?我相信大家可能都知道,影响产品不稳定性最重要的因素就是一个产品发布的过程,如果这个产品没有新的迭代,可能运行了几周、几个月,甚至于说一年、两年,根本不会出现很紧急的问题,一旦迭代发布,问题往往就出现了。我们引入的概念叫做错误预算,什么概念?概念化1减去SLA。
我们实际应用过程中,是按季度结算的,一个季度的预算没有用完,是不能到下一个季度的,如果用完了,这个季度,我们不会允许你再做一次新的发布,是这样的。如果你这个预算用完了就要冻结,冻结的话,就是说你就不可以再做新的发布,到下一个季度可以继续开支。因为我们通过数字来说话,完全有一个简单目标SLA,简单的一个数字,这里面不涉及到政治斗争的过程,不是说老板说了这个东西太重要了,还要发布,但是你的预算如果用完了,你不能发布,就跟社会现实中的法律是一样的。这样看起来就是一个共同的目标,我们一个季度比如说只有0.001%的错误预算,从SRE角度来说,肯定希望这个产品越多越好。开发者角度来说,希望这个季度结束以前,一定不能用完0.001%的错误预算,一旦用完了,后面在这个季度之内,再也没有办法发布新的产品了。
比如说我们的SLA是4个9,可用错误预算是0.01,如果说一个季度过去两个月了,已经用了0.003,还剩下0.007,这个还没有什么担心,因为距离错误预算用完还有很长距离。但是如果说已经用了0.008,只剩下0.002了,如果没有这样一个很好的机制,放到一般的开发与运营的两种角色关系来说,开发者肯定说我这个产品很重要,我一定要发布,但是这个时候,在我们的研发完全不一样了,因为开发者会衡量一下,我只剩下0.002%了,如果这个发布再出现了问题,我可能下面剩下的这一个月,我再也没有机会发布新的产品了,责任就是从传统的运营的角度,就转化到了开发者的角度。
作为一个运营人员,他没有办法证明你这个新的产品到底有多危险、到底有多安全,但是作为开发者,你有责任去衡量这个东西来使用。下一个工程方法。我这是从一个新的产品发布开始的,第一步比如说产品需求出来了、开发出来了,正在开发测试,开始内部上线了,内部上线一段时间以后,要做可不可以上线的审查,这个审查纯粹是SRE在帮产品团队做的一个审查,这不算是SRE直接的一个参与,他们在审查过程中,因为他们的运营经验比较丰富,审查过程中发现有什么问题,他会让你改正提高。纵坐标是稳定性,横坐标是时间轴,当通过了以后,到T0时间,就会开始发布,发布时间开始,外部用户就已经可以看到产品了。这个时候我想说一下,比如说我们的目标是6个9,这个时候只能达到5个9或者4个9,虽然外面用户已经看到了,但是处于自运营的状态,开发者自己去维护。这个过程中,开发者会不断的增加产品的稳定性,这个时候新的产品不是最重要的,要增加稳定性,因为他们要把这个产品在现实生产环境中做得更好,可以通过SRE的审查,然后可以把运营这一部分交接到SRE那边去。比如说到6个月的时候,这个产品的主要目的是说要把这个产品交到SRE去运营,主要就是有什么紧急状况,就会寻呼SRE。这个时候如果达到6个9,一切审查内容都过了,这个时候SRE就会正式介入,来支持这样一个日常的运营工作。
我后面讲一下这个审查的例子有哪些内容,这是一个反交接的过程。比如说前面那部分一直是SRE在支持运营,结果突然有一段时间,出现问题太多了,稳定性急剧下降,也很难以改善,SRE就有权利提出来反交接,反交接就是说产品回归到开发者去运营,我们就不管了,就是这样的意思。刚才讲的审查内容有哪些。比较重要的就是监视系统,监测你产品的健康程度,比如说你的内存、用量,什么CPU,像什么延迟之类的一系列的东西。还有仪表盘,不是用来发寻呼的,大家肉眼主动监测去观看的,比如说可以看到过去6个月或者8个月这个延迟的变化是多少。比如说上个月延迟0.001秒,现在变成0.002秒这是怎么回事,类似这样。SRE审查事件发生频率与类型,过去6个月自运营过程中,出现了哪些事故,这些事故有多严重,属于哪些类型的,过后是怎样修复的。有两方面作用,一方面帮助SRE了解这个产品的健康程度,为他们以后运营做一个铺垫。另外一方面也是考核这个产品在过去6个月当中,到底有没有什么重要的问题,你是怎么样修复的,最后是怎么样解决的。
还有一个审查叫做系统架构,他们会衡量一下这个系统架构是不是合理。还有一个就是发布的过程,过去6个月,你这个发布是怎样发布的,发布的频率是多少类似于这种,同时还会有一些Bug,比如说测试Bug、用户反馈Bug这样一种。
再下面讲的是组织架构。刚才讲的是工程方法,前面一系列工程方法是保证6个9的条件。组织架构也是一个,它比较简单,就只有一页PPT。一种是左边这种,开发与SRE,同时给一个产品主条上去,另外一个就是到上面经理,再到上面经理,最后到总经理。SRE给他的经理,再到上面的经理,再到总经理,我们选择哪个总呢?很显然应该选择第二种。第一个给最底层的经理,他的权限太大了。比如说他会认为这个新的产品非常重要,我要把它给发布出去,SRE基本上就没有什么办法了。但是第二种组织架构下面,经理1和经理2说话都不算,他们会坚守方法论,如果你错误预算到达了,你就不能发布了,这个是可以保证的。组织架构同时涉及到管理理念,最高级别就是刚才那个经理3,他一定要支持我们所做的这样一种错误预算的方法论,如果错误预算用完了,你一定不能发布,他必须支持这个东西。包括到下面的经理、工程师或者SRE都必须要理解,也要去执行,我们做得比较好的最终是数字为王,一定按数字说话,这样也不会伤同事之间的和气。
我总结一下前面讲的非技术方面的知识,通过非技术的手段,怎么样打造很高的SRE的。SRE与运营商之间要有共同的目标,他们都是希望产品稳定,有共同利益和共同的手段,大家一起做。根据经验就是说每个产品越早与SRE合作,整个后面的过程就会越顺利,我的经验就是说在我们需求分析有了以后,在做产品架构的时候,就去跟SRE合作,这样会比较好。
下面讲的就是技术支持这一块,光有这些非技术的功能方法、管理理念、组织架构还是不够的,我们要有足够的技术支持。从SRE的角度来说,他们不是特别熟悉产品的代码,因为像产品开发,他们每天好多小时,每周好几天都泡在代码里面,但是SRE是从另外一个角度来考虑这个问题,他并没有很熟悉,但是他们要有很强的技术能力,他不熟悉产品本身没有关系,但是他有很强的技术能力。
我们的SRE基本上都有一定的开发背景,大概一半一半,要有运营的能力,即使之前没有进来以后,我们也是做一个类似于50%、50%的细分,50%的时间在做跟开发相关的事情,让你具备这个能力;另外50%的时间做其他的事情。工具角度来说,我们内部是要有一系列的工具来支持这样一个高可用性的服务的。从底硬件来说,机器、存储、带宽,这个存储当然包括软件方面,然后到更高一点的软件层技术架构来说,我们要有错误处理,比如说某一个点出了问题,怎么样处理,这样一系列的东西。包括自动化的配置安装、监控、仪表盘,这里面工具几乎所有都是自动化的。作为一个开发者来说,他可能所有的东西对他来说都是黑盒的。
我们的SRE做得比较好的,还给工程师开发者提供了一系列的支持,比如说邮件系统的咨询,有关问题通过邮件方式咨询,有公开的视频培训,还有一些面对面的咨询,还有一些公布了审查的列表,同时还有一个发布委员会,如果你有什么需求,提前去咨询,发布委员会也会帮助你解决问题。 测试方面也是很重要的一块,也算是一个技术测试。我们的自动化测试,从最底层的最微观的单元测试,一直到宏观的系统测试,中间组件测试,这是对每个产品发布的硬性要求。组件到单元测试往往是通过开发者自己来写的,到系统测试往往就会有一些测试专员来做这个东西。我们还会做压力测试,地球上发生过很多次本身小测试没有问题,但是上线以后,压力变大以后可能就出现问题了。这四种测试是必须的,对于每个产品来说都是必须的。
手工测试,对于所有用户可见的分析都有手工测试的设计。
下面讲工具。刚才我大概讲了一下,这里面有一些比较稍微细一点的。最重要的就是监测,一旦有问题,那边马上会发这样一个寻呼,我们监测有黑盒、白盒,白盒的就是说你通过services本身来暴露出来的状态,比如说你的延迟程度。还有黑盒监测,跟刚才有点像,比如说我不管你这个服务是干吗的,我就是简单发一个过去,不管你这里面有什么,发现你用了多长时间,反馈结果对不对。
第二点就是仪表盘,如果想得到SRE的支持这也是必须的,SRE要有能力在任何时间、任何地点,在他想要看的时候,就可以看到你这个服务的状态。
再下面就是基础架构的支持,这个也非常重要。我们做一个复杂的系统,不是说做一个简单的services,还要依赖很多其他的东西。比如说你的数据库、你的网络、你的存储,对于每一块来说,都要有很强的革命性才能够使得你这个服务达到目标。比如说这个服务做得非常好,结果数据库不行,你这个服务也是不行的。
最后一点,如果说上面某一个技术,万一哪个地方出了问题怎么办?我们做oncall。第一个级别5分钟必须响应,如果你的产品出了问题,我们马上发一个Page,oncall人员在5分钟之内必须响应,我知道这个问题,我马上会出现。oncall人员分几个级别,第一个级别,一般来说希望你在5分钟之内马上反映,第二个级别就是说如果第一级别有什么意外情况,比如说你在这个地区没有网络,没有收到,或者说你在洗澡之类的没有收到,二级就会响应。三级往往就是技术人员,三级往往是开发团队的一个人,因为他对这个产品非常熟悉,在一级、二级遇到问题5分钟之内响应了,办了一段时间之后,发现不能解决这个问题,就要找第三级oncall,找他们协助解决。
我就这样总结了一下,大概四个方面来使我们达到这样一个6个9的目标,希望给大家带来一种帮助,谢谢大家!
以上是51CTO.com记者从一线为您带来的精彩报道。后续我们还有更加精彩的独家报道,敬请关注。