2016年4月14-15日,由51CTO传媒主办的WOT2016互联网运维与开发者大会在北京珠三角JW万豪酒店召开。秉承专注技术、服务技术 人员的理念,自2012年以来,WOT品牌大会已经成功举办了八届,积累了大量的技术专家资源,获得了广大IT从业者和技术爱好者的一致认可,成为了业界重要的技术分享交流平台以及人脉拓展平台。
本次会议分为11个技术主题,分别是:数据库技术与应用,大数据与运维,云计算与运维,运维安全,移动运维,容器体系构建与实践,运维自动化,行业运维、监控与性能优化、高可用架构和分布式存储技术。51CTO作为本次大会的主办方,将以快速报道、现场专访与后期视频等形式展示这场盛宴。
下面是来自腾讯社交网络运营部助理总经理、技术运营通道会长赵建春先生给大家带来的是主题为《如果运维可以重来一次》的精彩演讲。

赵建春,腾讯社交网络运营部助理总经理、技术运营通道会长、专家工程师。04年加入腾讯,先后从事过研发、运维、数据方面的建设和管理工作,在海量技术运营方面积累了丰富的实战经验。
【以下为现场演讲实录】
大家上午好!非常荣幸今天有这个机会在这里给大家做分享。我分享的题目是如果运维可以重来一次。我04年加入腾讯,加入之后做过贺卡的开发,05年的时候,非常荣幸加入QQ空间的开发团队,负责留言版模块的开发。06年底开始随着公司组织架构变化,开始接触运维这块的工作,到现在有10年时间,是一个10年的运维老兵,现在在社交网络负责大数据和运维工作。
介绍一下我们的运维团队,主要是负责以QQ延伸出来的各种社群的运维和维护,包括QQ空间、QQ音乐、QQ会员、QQ秀等一系列的QQ产品。我看了一下,真实员工89个人,加起来外包同事,我们维护了10万家服务器,维护的能力和谷歌比起来还是有差距,但是对很多传统企业来讲,已经是非常不错了。
团队也经历了非常多事件和活动的洗礼,比如说对空间的红米首发,让红米在我们的QQ空间上90秒卖出10万台设备,获得1亿点赞。去年8月份天津大爆炸事件,我们也是把我们天津2亿多活跃用户,从天津快速调到深圳以及上海,可能在中国互联网史上,可能是一个从来没有发生过的这么大规模的调动。
第三是支持了两次春节红包准备工作,尤其是今年比去年的红包访问量增加了10倍以上,快速的扩充了5000台设备,前段统一机构部署,最高访问量达到477万次每秒。还是一个比较值得信赖和可靠的团队。
今天为什么是这个题目?我自己和我的团队在运维这一块的工作已经经历了10年时间,在这10年之内,我们在想回顾一下,如果回顾过去10年工作,如果我们有一次重来的机会,什么才是对我们最重要的?什么是我们团队优先做好的一件事情?然后思考,然后再去深思,支撑我们更好的前行。
作为运维团队来讲,最最重要的事,首先让自己做的系统可靠、要不容易出错,不要让自己变成一个救火队员。可靠之后,才会有更多时间解决我们的效率,让自己的工作变得更加高效,再追求喝咖啡这样的事情。
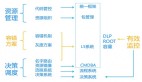
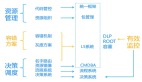
什么对我们的工作帮助最大?从这个图上来讲。我们写出来的程序和代码,包括现在运行的实例都是我们管理的资源,这个资源能不能进行一个清晰的划分和分类,对每个资源能不能有一个形状,然后进行搭建。我们维护海量服务,在运维过程中出现故障能不能影响项目服务,让我们服务器及时处理,所以容错方案是非常重要的,我甚至觉得是第一步的。
我们管理的资源清晰的分分类,同时有不同的形状,我们要进行各种各样的摆放,搬迁或者是调度的时候,有一个比较流畅的系统去做这个事情。
我们通过什么东西来做的?用统一框架,CMDBA,把一个业务模块上所有依赖资源全部登记进去。同时如果做快速决策和调度,还需要有效的监控,今天时间关系,监控这块不展开讲了。DLP就是我们内部定义的一个非常关键的监控,这个点发生了以后,就知道哪里出故障了。第二个是入口监控,到底是什么根源导致了这次故障。再就是容量管理的帮助,后期如果有同事分享,大家可以再关注。我们的容错方案的L5是帮我们解决了容错、灰度,名字路由的功能。
世界管理服务器最多的系统是什么?是运营管理系统,大家可能不会有太多意见,因为它管理了上亿服务器,脉络非常清晰,根本不会出现混乱。我们L5系统也类似于DNS系统,底下有一排能提供的服务模块,从而解决的单点问题。
它怎么做容错?L5有两部分,一个是L5和DNS,另外一个是L5和agent。CGI通过给这个模块提供一个ID,然后根据模块以下设备的成功率和延迟情况,给我们一个回馈,访问完之后,通过成功率和延迟情况,把数据上报给了L5 agent,然后有一个统计数据。当发现失败率特别低的时候,就踢掉。如果发现成功率和失败率有一定下降,会把访问权重降低,从而达到容错和负载均衡的作用。
我们可以注册一个模块,加多台设备,形成容错效果。如果发现一台机器失败率很高,就把它踢掉。它的成功率恢复过来,我们还可以再加回来。
我们新加一台服务器设计它的权重为1,假如之前的是100,我们可以逐渐上线。我们还可以给它一个得分,得分下降的时候,快速把它踢掉。
L5对运维团队的帮助是最大的事情,帮我们解决了日常工作中大量单点故障,早期做开发的同事都知道,非常习惯用一个ip+Port处理故障,它也解决了这个问题。
同过名字便利的服务上下线,可通过权重灰度上线。模块访问关系可帮助定位根源故障,接口的延迟和失败率可用来监控,它是集容错、负债均衡、路由、灰度监控能力于一身的,所以对运维的帮助非常大。
统一框架和架构。我们团队里面有上千号开发同事,每年有大量毕业生加入,也会有社交同事。他们进来以后,都希望在我们平台上做很多代码的贡献,或者展现一些技术实力,或者提高自己。问题是我们的开发里面,我们有管道、消息队列、信息文件锁、记录锁、文件影射内存,还有迭代服务器Select poll Io等,我们用各种各样技术组合生产出来的代码,交给团队维护,数以万计不同性格的服务器,要掌握得非常好,能了解它的工作机制和原理,更好的维护它基本上是不可能的事情,所以我要求把这个框架的部分,也就是网络通讯的部分,列成一个标准框架,提高它的通讯效率,统一维护。业务逻辑部分以SO动态库方式编写,与框架分离部署,类似WEB服务器上的CGI。接入层用QZHTTP,逻辑层是SPP和SF的框架。
我们社区类服务,用户的热点并不是很集中,数据量、访问量还是很大的,我们大量的是用CKV存储,同时还有一个访问量非常大的,比如说一个用户没有开通空间,甚至是一个游戏用户,他甚至是会员等等的标记,有一个定位就可以了,形成一个高访问量的模块。
这样一个架构体系,接入层是TGW,流量从它进、从它出。对于中间层,我们L5进行一个这样的调度,在存储层,因为每一个存储模块要分耗段,我们加了Access,从上到下把技术架构进行了统一规范,同时在组织上也通过接入逻辑运维层,进行标准化的维护。框架的统一大大减少了运维成员学习的成本。框架不断的提高,不会说大量的服务器交给我们出现各种不同故障的可能性,可以极大的提高我们的工作效率。
对我们开发出的程序包进行了一个标准打包操作,一个程序开发出来有不同特征,有的需要加银行参数,有的需要依赖目录,有的需要前面的准备工作和后续的善后工作,我们把它全部放在一个类似于包里面,装进一个盒子里,我们提供标准的操作接口,比如说安装、卸载、启动、停止这样的操作,让它变成一个关联的操作。
再也不会担心说,你不会操作这个接口。早期的时候程序开发出来,目录都不知道放在哪里,故障的时候都找不见,类似这样的问题再不会发生。还可以帮我们做很多善后和准备工作。进程级运转的所有资源都在盒子里面了,不用担心跑不起来。因为一个进程要运行起来,还不足以提供整体服务,我们要提供整体服务应该是同一个模块提供,这个模块需要几个整体服务来进行组合,还要依赖其他的资源,我们会把这些资源形成一个虚拟的镜像。
比如说这个业务包,有可能有一些基础包,有一些配置,还有一些目录文件,还有权限。权限是腾讯独有的,有些公司有,有些公司不会有。腾讯的业务,比如QQ关系链是非常敏感的,所以我们内部采用互不信任的机制。机器不能随便标记这个用户是会员用户,或者说是一个特权用户,一般都是采用互不信任的机制,所以在发展过程中,逐渐出现了要授权的模块,而这个模块需要我们去线下发邮件走流程申请,或者在线上走一个电子流审批,这时候就有人介入了。我就不展开讲了,因为它对我们很重要,但是可能在小公司或者一些传统企业并不会存在。完成这样一件事情以后,我们就相当于把这个模块运行的完整资源依赖全部装箱操作,进行整体完整的部署,这样会导致我们不再需要类似以前老是要提供什么模块的使用文档、说明书这样的事情,就非常容易操作了。
之后做变更就会非常容易。我们有一个内部的织云自动化部署平台,第一步申请设备获取资源,发布部署,然后检测,检测完之后进行测试,测试之后就可以上线。每一步里面,还有一些细节的步骤,比如说这么多步。比如说申请设备的时候要屏蔽告警事件,发布的时候要同步传输文件,发布之后要检测程序的包进程是不是启动了,启动之后进行业务测试,然后进行慢慢上线。
这就是我们织云内部自动化部署的平台,我们相当于把这个进程开发出来以后,依赖的资源全部打包放在盒子里,把盒子里的东西放在我们的资源仓库中,有一些模块全部登记在CMDB。如果我们要部署一个模块A,或者说进行扩容,可能是人工触发,或者自动系统触发,控制人工系统进行操作,把模块边上三个资源,由资源仓储部署在模块1上,通过L5系统进行一个注册,这个模块就自动上线了。我们还有一个容量监控的监控体系的介入,今天就不展开了。
我们会把一个模块登记回来,可以对它进行自动化的操作,每一个方块是一个步骤,这个步骤执行过去之后就是绿色的,执行失败就是红色,或者没有执行的就是灰色的。执行成功之后,可以看到,我们可以做自动化的扩容,可以做一些日常的演习,还有一些回收等等这样的工作。
走在这一步的时候,我们看到整体的过程,看起来还是比较自然而然的过来。但是实际上这个事并没有这么容易做,它是这样的发展历程,我们的打包规范在06到08年进行推广,那时候开发代码必须要打包,我们会做专职打包。08年到2010年组件标准化,只能选择一种服务,当然也有其他,你选择其他就会非常麻烦,你需要写为什么,还需要一些审核,当然一定会有特例,所以这个特例就会尽量避免和减少。我们现在有一个业务团队就是维护特例的服务性,维护能力非常低,一个人可能只能维护几百台设备,但是标准模块可以维护上万台设备。2010到2013我们一直在进行L5容错和名字服务。2013年到现在在做资源登记权限中心和智能化自动化。我们能不能把08年到2010年,2010年到2013年,2013年到现在的事情,全部放在05到08年的时间?08年到现在就有8年时间做智能化、自动化的工作,处在什么样的自动化的水平,这是非常让人振奋的,所以才会有这样的感触。
运维最难解决的问题是什么?就是历史问题。每个团队都会遇到自己的历史问题,我挖了一个坑,又出来一个坑。讲一个案例,这个事情,看起来和我们讲的内容没有什么关系。美国有一个西南航空公司,1971年成立,现在是美国第二大航空公司,大概有600架飞机,国航是590多架,它的市值是280多亿美金。最大成绩是连续33年持续盈利,包括911恐怖袭击之后,美国大批航空公司倒闭,它还可以盈利,非常的平稳。它在创始之初就做了一个决策,只购买播音737-700型飞机,用网状去枢纽化的营运策略,目的就是高效运营起来,不去中心枢纽型的地方排队,飞机也是中小型飞机,这样就可以看出来,它最初的顶层设计,就是比较高效的运作方式,也是未来过程中产生立于不败之地的情况。
虽然我们的团队不能重来一次,现在有很多创业团队,有很多新项目,我们能不能在最初的时候,就有运维和开发共同参与制订这样一些,对未来运维工作有预见性的规范规则,最后再由开发把它根基打好,开发对用户的帮助非常大,一定是运维和开发深度配合合作,才能打造高效运维基础,达到一个高效的效果。
云计算是这几年发展最快的一个产品,而且我们相信它也一定会是我们在IT领域未来的一个大趋势,同时再一个标准这样的东西,一定程度上和高效、可靠一定是同义词。我相信云计算未来一定会成为超级标准,它是把IT领域里面的各种问题的解决方案逐渐的通过整个行业的智慧,把它最终形成一个统一的解决方案。
腾讯也有腾讯云的服务,我们腾讯云现在也是业界领先的公有云的服务商,经过过去几年发展,尤其是去年翻倍式增长,目前全球有50家数据中心,有500家数据加速节点,超过10T整体带宽,4T防DDOS攻击能力,700万+域名提供解析。我们也希望各位同事可以关注腾讯云,支持腾讯云,谢谢大家!
以上是51CTO.com记者从一线为您带来的精彩报道。后续我们还有更加精彩的独家报道,敬请关注。