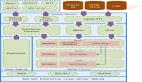
开源大数据技术是一种新一代技术和构架,它以成本较低、以快速的采集、处理和分析技术,从各种超大规模的数据中提取价值。大数据技术不断涌现和发展,让我们处理海量数据更加容易、更加便宜和迅速,成为分析和挖掘海量数据价值的一个利器,甚至可以改变许多行业的商业模式。
庞大的开源大数据技术体系,使得大数据平台在实施和使用的过程中遇到很多难点,Think Big团队总结了在开源大数据平台设施的整个过程及花费的时间,如下图所示:
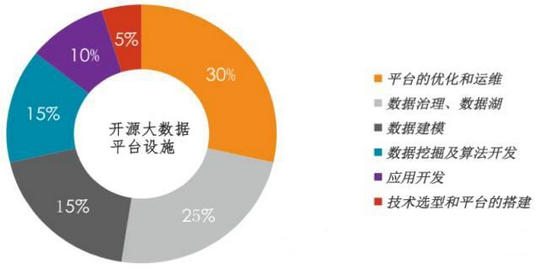
大数据平台的优化和运维
大数据平台的优化和运维应该是开源大数据平台实施的难点、也是构建大数据平台对人员的技术和经验要求***的阶段,贯穿整个大数据平台实施过程。
大数据平台的数据整合、数据治理和数据湖
对于传统的企业使用大数据平台,数据整合、数据治理和数据湖也是非常重要和比较困难的阶段,全公司不同数据源之间的数据整合面临:数据的一致性、数据的完整性、数据的准确性、数据的安全等问题如何解决,当然还有不同数据(如:冷数据、温数据和热数据)怎么来存放,进而实现高效的数据存储和分析。这些都是我们在大数据实施过程中需要花很多时间和经验来实现的,很多的公司基本上都在直接或间接的使用大数据技术,有可能感觉大数据整合、治理、数据湖没有那么重要,把功能实现了,就觉得把大数据平台用的非常好了,其实不然,就像我上面提到的那张图,功能的实现只占大数据平台实施的一小部分。
大数据平台上面的数据建模
由于大数据平台面临数据的一致性、数据的完整性、数据的准确性等问题所以导致大数据平台上面的建模变得比较困难,此外还有不同行业面临的大数据平台建模问题各不相同。传统行业在大数据上面的建模面临的挑战还是非常多的,有的模型甚至不适合在开源大数据平台上面建模,不要一味的去和互联行业大数据平台上面的应用做比较,因为,互联网的业务比传统的业务模型简单很多。
数据挖掘和算法的实现
大数据平台的数据挖掘技术有Hadoop的Mahout、Spark的Mllib、SparkR等,这个现有的挖掘库存在很多问题,如:分布式计算。对整个团队的人员要求非常的高。
应用开发(类似于传统EDW的BI功能)
类似于在Hadoop上面实现一个传统的EDW的功能,常见用的比较多的就是SQL on Hadoop技术,如:Hive、Impala、Tez、Presto、Kylin、SparkSQL等。
大数据平台的选择和搭建
主要是Apache Hadoop、Hortonworks HDP和Cloudera CDH的选择,Apache Hadoop是纯开源的,Hortonworks HDP是开源Hadoop生态系统的管理,Cloudera CDH是开源Hadoop生态系统的增强。