【讲师简介】
王传鹏,新浪微博推荐及广告技术总监。2006年从北航毕业,然后加入霍尼韦尔北京研中心做工程,之后同合伙人一起创办云存储网络硬盘(99盘)。在公司被收购后,加入当当网负责推荐和广告工作。于2011年加入新浪微博商业产品部,负责推荐和广告,直至现在。
冯扬,微博推荐开发技术专家。目前,负责新浪微博搭建微博推荐平台与建立针对推荐的用户模型两方面工作。前者是 指在微博现有的技术基础和分层架构上,设计微博的标准化推荐架构,搭建推荐平台,解决推荐业务中物料和特征数据接入、推荐计算、模型训练、横向对比等方面 的问题;后者是针对微博推荐业务中所需的基础数据,尤其是用户相关的基础数据挖掘,为推荐服务。
【演讲干货】
王传鹏在演讲一开始,就像大家说明由于微博推荐开发技术专家冯扬家里有私事不能参加,由他来进行此次的演讲。此次演讲的主题由微博用户模型的维度划分、建模目标和方法、用户模型在微博推荐中的应用三部分组成。
微博用户模型的维度划分如下图:
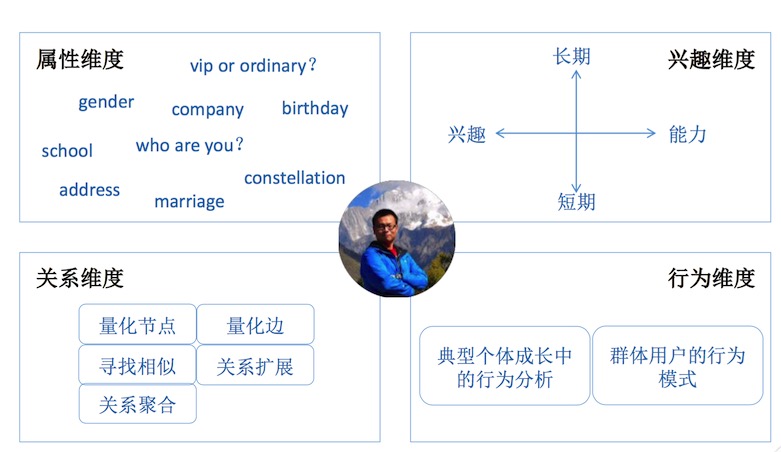
用户属性&用户兴趣(用户画像)
用户画像
属性和兴趣维度的用户模型都可以归入用户画像(User Profile)的范畴,即对用户的信息进行标签化。一方面,标签化是对用户信息进行结构化,方便计算机的识别和处理;另一方面,标签本身也具有准确性和非二义性,也有利于人工的整理、分析和统计。
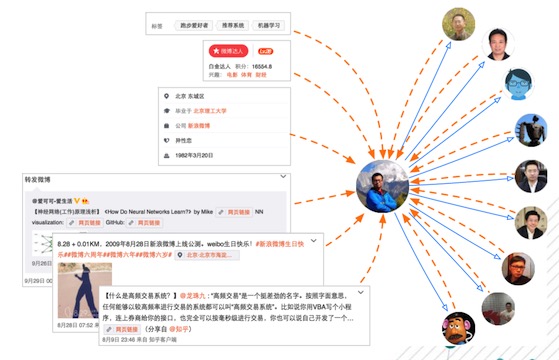
兴趣维度
用户属性指相对静态和稳定的人口属性,例如:性别、年龄区间、地域、受教育程度、学校、公司……这些信息的收集和建立主要依靠产品本身的引导、调查、第三方提供等,在此基础上需要进行补充和交叉验证。
用户兴趣则是更加动态和易变化的特征,首先兴趣受到人群、环境、热点事件、行业……等方面的影响,一旦这些因素发生变化,用户的兴趣容易产生迁移;其次,用户的行为(特指在互联网上的行为)多样且碎片化,不同行为反映出来的兴趣差异较大,在用户兴趣分析的过程中,主要考虑如下几个方面:
(1) 标签来源:不是所有的词都适合充当用户标签,这些词本身应该具有区分性和非二义性;此外,还需要考虑来源的全面性,除了用户主动提供的兴趣标签外,用户在使用微博的过程中的行为,构建的用户关系等也能够反应用户的兴趣,因此也要将其考虑在内。
(2) 权重计算:得到了用户的兴趣标签,还需要针对用户给这些标签进行权重赋值,用来区分不同标签对于该用户的重要程度。
(3) 时效性:随着时间的变化,用户的兴趣会发生转移,有些兴趣会贯穿用户使用社交媒体的全过程,而有些兴趣则是受热点时间、环境因素等的影响。
(4) 兴趣和能力的区分:用户具有某方面的兴趣,只代表了他愿意接受这方面的信息,并不能代表他具有产生相关内容的能力。区分兴趣和能力,能有助于预测兴趣相关内容潜在的生产者和传播者。
社交关系模型
关系维度
如果将微博中的用户视作节点,用户之间的关系视作节点之间的边,那么这些节点和边将构成一个社交的网络拓扑结构,或称作社交图谱。微博中的信息就是在这个图谱上进行传播。
从社交的维度建立用户模型,需要从不同的角度细致和全面地描述这个社交图谱的特征,反应影响信息传播的各层面上的因素,寻找节点之间的关联想,以及刻画图谱本身的结构特征。其中包括:
(1) 用户个体对信息传播的影响:不同用户在信息传播过程中的重要性不一样,影响大的用户对于信息的传播较影响小的用户更具有促进作用。
(2) 量化用户关系的远近:衡量存在直接关联(关注、被关注、互粉……)用户之间的关系远近,关系越近的用户之间越容易产生信息传播行为。
(3) 延伸用户之间的关系:通过用户之间的直接关系(关注、被关注、互粉……),让本身并不存在直接关系的用户产生关联。
(4) 寻找相似的用户:微博中非对等的关系本身可以认为是一种认证,用户基于兴趣、线下关系、或某种其它原因反应到线上的一种关联。那么在关系维度上的相似用户至少能反应他们在某种因素上的一致性。
(5) 识别关系圈:从关系图谱的本身的结构出发,从中发掘关联紧密的群体,有助于信息的精准投放和推广。
以上关于关系建模的任务可以看作是逐步深入的,从“个体”-->“关联”-->“相似”-->“群体”的逐渐深入。
用户行为模型
行为维度
分析用户的行为,建立行为模式有两个任务:针对典型个体行为进行时序分片,分析用户成长的相关因素;针对典型群体的行为进行统计,构建其行为模型。
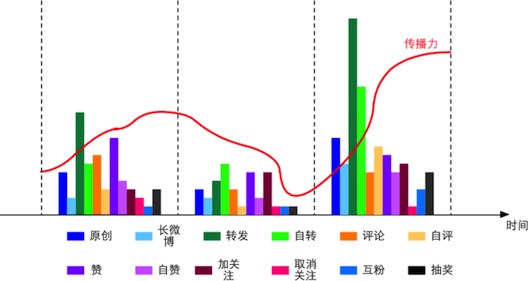
(1) 典型个体的行为时序分析
所谓典型个体是指某段时间内,成长比较突出的微博用户。例如从一个新用户从新注册到粉丝过百、过千需要有一个积累过程,有些用户积累较快,有些较慢,而这些积累较快的用户可以作为典型个体;或者某些用户在某一阶段传播力有限,但在某时刻传播力激增,无论是互动还是内容传播覆盖面都变化很大,这种也可以作为典型个体。
针对典型个体,需要挖掘与其用户成长相关的行为因素。基本方法是对时间进行分片,获取用户在不同时间片上的行为统计,以及在各个时间分片上的用户成长指标(粉丝数、互动率、传播力等),如图2所示。在此基础上针对用户行为的统计量的变化,利用关联性分析或回归来分析用户成长与哪些因素有关。
(2) 典型群体行为模式分析
针对典型个体,从用户的基本信息、人口信息、兴趣维度,可以将相似的典型用户划分为同一的群体,称作典型群体,针对典型群体中的用户按照成长程度进行划分,按不同的成长阶段统计用户行为,即建立了该典型群体的行为模型。
例如,对于“北京,年龄在20~30岁,女性,电商领域,普通账号”这样的典型群体,从粉丝数、传播力、互动率等维度将其划分到初创、成长、快速提升、成熟……等阶段,针对不同成长阶段内的行为组合进行统计,结果构成该群体的行为模式。
用户模型在微博推荐中的应用
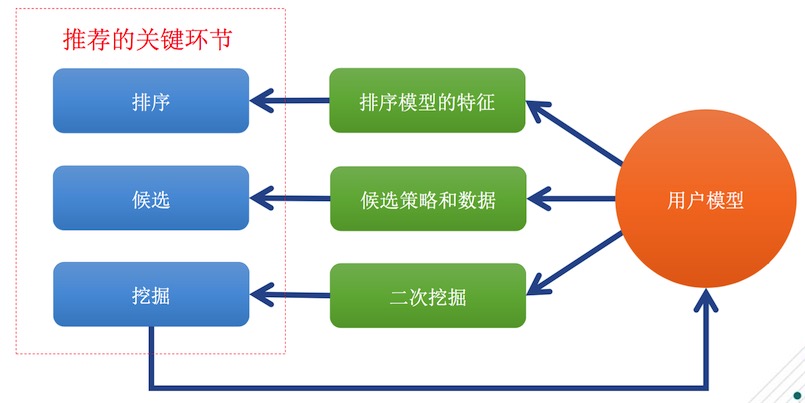
推荐主要由排序、候选、挖掘三部分构成,在这三个阶段过程中排序时会用到排序模型、候选的策略和数据、挖掘这里比较重要的是二次挖掘。当用户模型产生之后,可以更加深入的统计出有用的信息,这样一来,用户模型就得到了相应的应用。在排序时候,我们会用到用户模型的各种特征。在候选时候,你有可能感兴趣的人,好友关注都是通过候选方法通过关系圈扩展得来的。还有内容推荐,好友赞微博也是通过候选实现的。
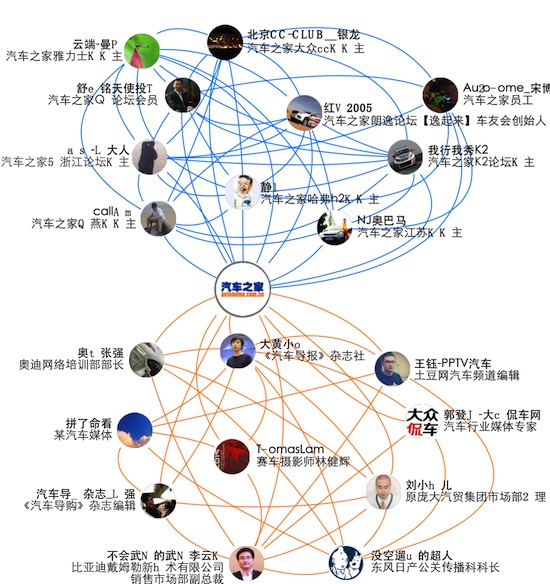
二次挖掘应用举例
在挖掘的时候,所有的数据都将派上用场。比如说领域关系圈的二次挖掘,在这里是先有能力标签、之后通过标签把相应的用户找到,设立为种子用户。之后再利用一度和二度的关系及相似用户的扩充,这样就会得到一个领域关系圈。