这篇博客是关于大型机群任务调度系列的***篇,资源调度在Amazon、Google、Facebook、微软或者Yahoo已经有很好实现,在其 它地方的需求也在增长。调度是很重要的课题,因为它直接跟运行集群的投入有关:一个不好的调度器会造成低利用率,昂贵投入的硬件资源被白白浪费。而光靠它 自己也无法实现高利用率,因为资源利用相抵触的负载必须要仔细配置,正确调度。
架构演进
这篇博客讨论了最近几年调度架构如何演进,为什么会这样。图一演示了不同的方法:灰色方块对应一个设备,不同颜色圈对应一个任务,有“S”的方形代表一个调度器。箭头代表调度器的调度决定;三种颜色代表不同工作负载(例如,网站服务,批量分析,和机器学习)
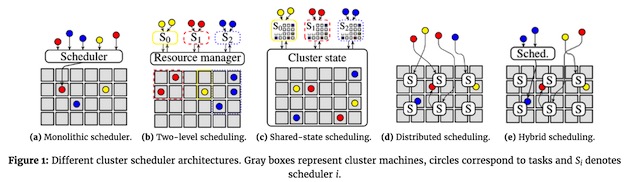
图一:不同调度架构,灰色框代表集群设备,圆圈代表任务,Si代表调度器。
(a)单体式调度器(b)二级调度 (c)共享状态调度 (d)分布式调度 (e) 混合式调度
许多集群架构,例如大量高性能计算(HPC),使用的是Borg调度器,它跟Hadoop调度器和Kubernetes调度器完全不同,是单体式调度。
单体式调度
单一调度进程运行在一台物理机内(例如Hadoop V1中JobTacker,Kubernetes中的kube-scheduler),将任务指派给集群内其它物理机。所有负载都服从于一个调度器,所有 任务都通过这一个调度逻辑运行(参见图一a)。这种架构最简单格式唯一,在此基础上发展起了很多负载的调度器,例如Paragon和Quasar调度器, 采用机器学习方法来避免不同负载之间资源竞争。
今天集群都运行着不同类型的应用(与之相对应的是MapReduce早期作业场景),然而,采用单一调度器来处理这么复杂异构负载会很棘手,有几个原因:
-
调度器必须区分对待长期运行服务作业和批量分析作业,这是合理的需求。
-
因为不同应用有不同的需求,催生调度器内加入更多功能,增加业务逻辑和部署方式。
-
调度器处理任务顺序变成一个问题:如果调度器不仔细设计,队列效果(例如线头阻塞head-of-line blocking)和回滚会成为问题。
总之,这听起来像是给工程师带来噩梦,调度器维护者面对的没完没了的功能请求证实了这点。
二级调度
二级调度通过将资源调度和任务调度分离解决了这个问题,这使得任务调度逻辑不仅可以根据不同应用要求而进行裁剪,而且保留了在集群之间共享资源的可 能性。尽管侧重点不同,Mesos和 YARN集群管理都使用了这种方法:Mesos中,资源是主动提供(offer)给应用层调度,而YARN则允许应用层调度请求(request)资源 (,并且随后接受被分配资源)。图一b展示了这一概念,作业负责调度(S0-S2)跟资源管理器交互,资源管理器则给每个作业分配动态资源。这一方案赋予 客户灵活调度作业策略的可能性。
然而,通过二级调度解决问题也有问题:应用层调度将资源全局调度隐藏起来,也就是说,不再能看到全局性的可选资源配置。相反,只能看到资源管理器主 动提供(offer,对应于Mesos)或者请求/分配(request/allocate,对应于YARN)给应用的资源。由此带来一些问题:
-
重入优先权(也就是高优先权会将低优先权任务剔除)实现变的很困难。在基于offer模式,被运行中任务占用的资源对高一级调度器不可见;在基于request模式,底层资源管理器必须理解重入策略(跟应用相关)。
-
调度器不能介入运行中业务,有可能减低资源使用效率(例如,“饥饿邻居”占据了IO带宽),因为调度器看不见他们。
-
应用相关调度器更关注底层资源使用的不同情况,但是他们唯一选择资源的方法就是资源管理器提供的Offer/request接口,这个接口很容易变的很复杂。
共享状态架构
共享状态架构通过采用半分布式模式来解决这个问题,这种架构下集群状态多副本会被应用层次调度器独立更新,如图一C中所示。一旦本地有更新,调度器发布一个并发交易更新所有共享集群状态。有时候因为另外一个调度器发出了一个冲突交易,交易更新有可能失败。
最重要的共享状态架构实例是Google的Omega系统,以及微软的Apollo和Hashicorp的Nomad容器调度。这些例子中,共享集 群状态架构都是通过一个模块实现,也就是Omega中的“cell state”,Apollo中的“resource monitor”,以及Nomad中的“plan queue”。Apollo跟其他两个不同之处在于共享状态是只读的,调度交易直接提交到集群设备;设备自身会检查冲突,来决定接受或者拒绝更新,使得 Apollo即使在共享状态暂时不可用情况下也可以继续执行。
逻辑上来说,共享状态设计不一定必需将全状态分布在其它地方,这种方式(有点像Apollo)每个物理设备维护自己的状态,将更新发送到其它感兴趣 的代理,例如调度器,设备健康监控,和资源监控系统。每个物理设备本地状态就成为一个全局共享状态的“沟通片”(shard)。
然而,共享状态架构也有一些缺点,必须作用在稳定的(过时的,stale)信息(这点跟中心化调度器不同),有可能在高竞争情况下造成调度器性能下降(尽管对其它架构也有这种可能)。
全分布式架构
看起来这种架构更加去中心化:调度器之间没有任何协调,使用很多各自独立调度器响应不同负载,如图一d所示。每个调度器都作用于自己本地(部分或者 经常过时的【stale】)集群状态信息。典型的,作业可以提交到任何调度器,调度器可以将作业发布到任何集群节点上执行。跟二级调度器不同的是,每个调 度器并没有负责的分区,全局调度和资源分区是服从统计意义和随机分布的,这有点像共享状态架构,但是没有中央控制。
尽管说去中心化底层概念(去中心化随机选择)是从1996年出现,现代意义上分布式调度应该是从Sparrow论文开始的,当时有一个讨论是:合适 粒度(fine-grained)任务有很多优势,Sparrow论文的关键假设是集群上任务周期可以变得很短;接下来,作者假定大量任务意味着调度器必 须支持很高通量的决策,而单一调度器并不能支持如此高的决策量(假定每秒上百万任务量),Sparrow将这些负载分散到许多调度器上。
这个实现意义重大:去中心化理论上意味着更多的仲裁,但是这非常适合某类负载,我们会在后面的连载中讨论。现在,足够理由证明,由于分布式调度是无协调的,因此相对于复杂单体式调度,二级调度或者分布状态时调度,更适合于简单逻辑。例如:
-
分布式调度是基于简单的“时间槽(slot)”概念,将每台设备分成n个标准时间槽,同时运行n个并发任务,尽管这种简化忽略了任务资源需求是各自不同的事实。
-
在任务端(worker side)使用服从简单服务规则的队列方式(例如Sparrow中FIFO),这样调度器的灵活性受到限制,调度器只需决定在哪台设备上将任务入队。
-
因为没有中央控制,分布式调度器对于全局变量设置(例如,fairness policies或者strict priority precedence等)有一定难度。
-
因为分布式调度是为基于最少知识做出快速决策而设计,因此无法支持或承担复杂应用相关调度策略,因此避免任务之间干扰,对于全分布式调度来说很困难。
混合式架构
混合式架构是为了解决全分布式架构缺陷,最近(发端于学院派)提出的解决方式,它综合了单体式或者共享状态的设计。这种方式,例如 Tarcil,Mercury和Hawk,一般有两条调度路径:一条是为部分负载设计的分布式路径(例如,短时间任务或者低优先级批量负载),另外一条集 中式调度,处理剩下负载,如图一e所示。对于所描述的负载来说,混合架构中发生作用的调度器都是唯一的。实际上,据我所知,目前还没有真正的混合架构部署 于生产系统中。
实际意义
不同调度架构相对价值,除了有很多研究论文外,其讨论不仅仅局限在学院内,从行业角度对于Borg,Mesos和Omega论文的深入讨论,可以参 见Andrew Wang的专业博客。然而,很多以上讨论的系统都已经部署在大型企业生产系统中(例如,微软的Apollo,Google的Borg,Apple的 Mesos),反过来这些系统激励了其它可用开源项目。
如今,很多集群系统运行容器化负载,因此有一系列面向容器的“调度框架”(Orchestration Framworks)出现,他们跟Google以及其它被称为“集群管理系统”类似。然而,很少关于这些调度框架和设计原则的讨论,更多是集中于面向用户 调度的API(例如,这篇Armand Grillet的报道,比较了Docker Swarm,Mesos/Marathon和Kubernetes的默认调度器)。然而,很多客户既不懂不同调度架构的不同,也不知道哪个更适合自己的应 用。
图二展示了一部分开源编排框架的架构和调度器支持的功能。图表底部,也包括google和微软闭源系统作比较。资源粒度一列展示调度器分配任务给固定大小时间槽,还是按照多维需求(例如CPU,memory,磁盘IO,网络带宽等)分配资源。
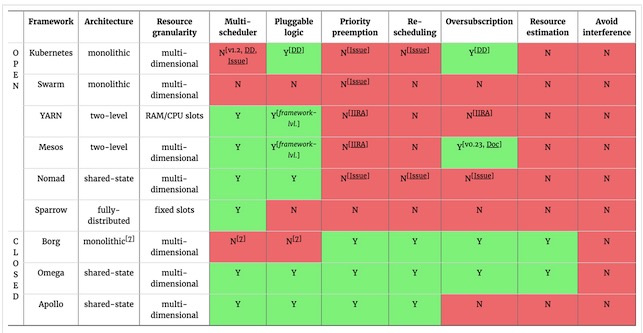
图二:常用开源编排框架分类和功能比较,以及与闭源系统比较。
决定一个合适调度架构主要因素在于你的集群是否运行一个异构(或者说混合的)负载。例如,前端服务(例如,负载均衡web 服务和memcached)和批量数据分析(例如,MapReduce或者Spark)混合在一起,这种组合对于提高系统利用率是有意义的,但是不同应用 需要不同调度方式。在混合设定下,单体式调度很可能导致次优任务分配,因为基于应用需求,单体调度逻辑不能多样化,而此时二级或者共享状态调度可能更加适 合一些。
许多面向用户服务负载运行的资源一般是满足容器的峰值需求,但是实际上资源都是过分配的。这种情况下,能够有机会降低给低优先级负载过分配资源对高 效集群来说是关键。尽管Kubernetes拥有相对成熟方案,Mesos是目前唯一支持这种过分配策略的开源系统。这个功能未来应该有更大改善空间,因 为根据Google borg集群来看很多集群利用率任然小于60-70%。后续博客我们将就资源预估,过分配和有效设备利用等方面展开讨论。
***,特殊分析和OLAP应用(例如,Dremel或者SparkSQL)非常适合全分布式调度。然而,全分布式调度(例如Sparrow)内置相 对严格功能设置,因此当负载是同构(也就是,所有任务同时运行)、配置时间(set-up times)很短(也就是,任务调度后长时间运行,如同MapReduce应用任务运行于YARN)、任务通量(churn)很高(也就是,许多调度决定 必须很短时间内做出)时非常合适。我们将在下一个博客中详细讨论这些条件,以及为什么全分布式调度(以及混合架构中分布模块)只对这种应用场景有效。
现在,我们可以证明分布式调度比其他调度架构更加简单,而且不支持其他资源维度,过分配或者重新调度。
总之,图二中表格表明,相对于更高级但是闭源的系统来说,开源框架仍然有很大提升空间。可以从如下几方面采取行动:功能缺失,使用率不佳,任务性能不可预测,邻居干扰(noisy neighbours)降低效率,调度器精细调整以支持某些客户忒别需求。
然而,也有很多好消息:尽管今天还有很多集群仍然使用单体式调度,但是也已经有很多开始迁移到更加灵活架构。Kubernetes今天已经可以支持 可插入式调度器(kube-scheduler pod可以被其它API兼容调度pod替代),更多调度器从1.2版本开始会支持“扩展器”提供客户化策略。Docker Swarm,据我理解,在未来也会支持可插入式调度器。
下一步
下一篇博客将会讨论全分布式架构对于可扩展式集群调度是否关键技术创新(反对声音说:不是必须的)。然后,我们会讨论资源适配策略(提高利用率),***讨论我们Firmament调度平台如何组合和共享状态架构和单体式调度质量,以及全分布调度器性能问题。