云智慧全栈应用性能管理解决方案是一套面向企业实际业务的端到端整体解决方案,其中IT数据的端到端采集和展现是云智慧领先于国内其他APM产品的重要特性之一,那么我们是如何进行数据采样的,又是如何在“端到端”应用性能管理中满足用户对业务数据性能衡量呢?本文将为您一一道来。
首先理解一下我们对“端到端”的定义,“端到端”就是很多年前业内就在提的End2End,现在业内几个APM厂商在云智慧提出端到端概念之后,也在这么吆喝。端到端有很多种理解,我们的理解是:从终端用户出发,将从Request到Response整个链路中涉及到的所有数据,有效地串接起来,这样的数据才是真正的端到端,而不是将数据按照时间序列进行简单地罗列展现。
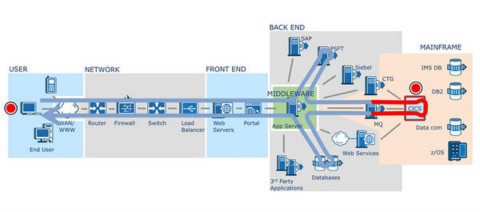
我们从上面的软硬件模型中可以看到,一个用户请求从前到后,经过了N多的节点才最终返回数据并展现在用户面前,相信很多有经验的开发和运维都曾经想,怎样有效地将从用户请求开始,将请求链路中的数据都采集到,并且有效地关联起来。
下面就为您剖析一下“采样”对于“端到端”应用性能管理的意义和实现。
为什么要采样?
采样这个事说起来是最有意思的,有数学基础或做过计算机研发的都会非常熟悉。基本上,所有有关数据统计或分析的场景,都离开采样。
采样最直接的目的有两个:减少计算量和降低描述难度。
采样方法有非常多种,最简单的,无论哪一种语言,肯定有一个random函数,对其施以随机种子,然后综合时间 / CPU即时频率 / 内存地址等等信息,那么出来的即是一个采样值。像一些profile工具,开始执行的开关就是用这种方式,比如facebook开源的xhprof就非常典型。
采样还可以人为指定样本,这也是一种常见的做法。比如,直接指定某一个特定标识,如时间,ip,或进程id,等有非常明确特指意义的属性。如程序猿们在开发过程中,对一次具体请求的debug过程,非常典型。
在APM厂商中,普遍采用这样一种采样算法来计算Apdex。(注:云智慧并未采用这个采样算法,后文会解释原因。)先看看什么是Apdex,它是Application Performance Index 应用性能指数的缩写,这个指数被其他的APM厂商奉为衡量应用性能的核心指标。它为用户对应用性能满意度进行量化,提供了一个测量标准。

以后提到Apdex,大家用这个图来解释:Apdex值是0 - 1的区间值,每个区间对应一个评价:1~0.94是优秀,0.94~0.85是良好,0.85~0.70是尚可,0.70~0.50是差评,低于0.50的Apdex值是用户无法接受的。
这个值,怎么计算呢?
Apdex算法起源于对一个传统数据方法的质疑,这个传统方法就是正态分布,也叫高斯分布。正态分布的定义:

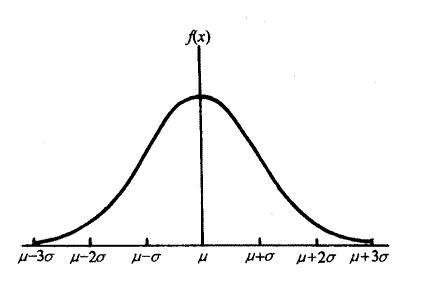
正态分布应用非常广泛,比如用来对比班级之间的成绩,或用来对比某两组数据的属性差异时,会用它来作为衡量标准。正态分布非常的标准和简单,但它有三个明显的问题:
l 衡量时,使用的是平均值,因此,它假定了 “占主导地位的值是最重要的”。
l 计算时,进一步取向平均的值是不重要的,因为,它假定了那些值 “偏离了规范”。
l 计算时,它过分夸大了曲线两端的极限值,因为,它假定了 “分布在两端的数据会被平均,而影响其他值”。
这三个问题是正态分布在数据统计时存在的明显缺陷。而Apdex的算法针对以上三个问题,作了一个演进。Apdex的计算首先定义一个标准量T,进而将待计算的样本以T为标准量划为三个区间。分别是:
l 小于等于 1T, 为 Satisfactory (满意)
l 大于1T,小于4T,为 Tolerating ( 容忍 )
l 大于等于4T,为 Frustrated ( 失望 )
此时,Apdex = ( 1 x 满意 + 0.5 x 容忍 + 0 x 失望 ) / 样本数
有没有注意到一点,失望样本被忽略了。而满意样本,即钟曲线最左侧的极限值,也未被绝对平均。从计算公式中我们可以看到,Apdex假定你的样本就是属于标准正态分布的,并且减轻曲线两端对衡量值的影响。
首先声明标量T = 2s
假定样本为:
l 小于2s的请求次数为10次,满意;
l 大于2s,小于8s的请求次数为20次,容忍;
l 大于等于8s的请求次数为10次,失望。
那么得到 Apdex = ( 1 x 10 + 0.5 x 20 + 0 x 10 ) / 40 = 0.5
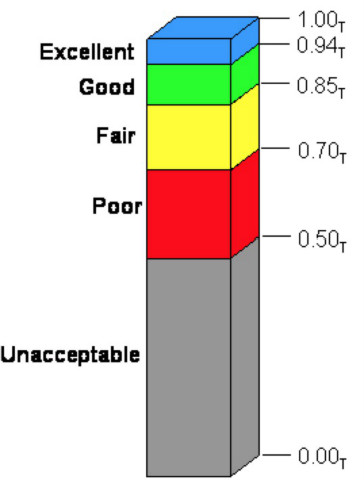
拿这个标尺看一下0.5在哪里,已经接近“无法接受”了。所以,如果用Apdex来衡量刚才这组样本,则认为,这个应用已经要挂了。
这个被广大APM厂商奉为金典的标准,合理吗?
我再举一个例子以说明是否合理。假如上面计算的不是响应时间,而是一群人的血压。如果样本数据是一样的,即:血压满意的为10, 血压可容忍的为20, 血压超高令人失望的为10。那么得出的这个0.5的结果,则意味着:这群人已经接近了“无法接受”状态,快挂了,需要集体用药。
是的,这个值只能说明一个概况,而并不能反映真实的现状。因为它做到了简单的整体衡量,而忽略了病患。不能说Apdex不合理,只是在具象的衡量上,标准并不能代表真实状态。
接下来看看云智慧APM产品透视宝对数据采样的方案,大家对比一下其优劣。
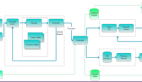
首先可以确定的是,云智慧的数据采样算法并非统计方法。这个方法的设计思路是:充分覆盖所有的URI请求的前提下,关注超出响应阈值的请求。 步骤一、全部或部分请求通过hash算法,取得当前URI的hash key;
步骤二、判断请求是否为***访问,若是否,则执行步骤三,若否是,则执行步骤四;
步骤三、开始追踪本次请求,采集本次请求的哈希值,并将此次采集的哈希值记录在散列图中;
步骤四、判断是否允许追踪,若否,则执行步骤五,若是,则执行步骤六;
步骤五、不追踪,并于本次请求结束后,判断是否将本次请求采集的哈希值记录在Trace队列中;
步骤六、判断是否已经实施过追踪,若是,则不追踪,若否,则执行步骤七;
步骤七、启动追踪,并将被追踪的次数记录于Trace队列中。
这样做的优势是什么呢?
首先,我们没有漏掉任何一个请求,无论快或慢,在出现问题的一刹那,马上开始关注这组请求,当它再次发生,则立刻进行全栈的追踪。
其次,天然地将数据请求进行分组,不依据时间分组,而是依据请求事务进行分组;
***,在不影响全栈追踪的前提下,很好地解决了性能问题。
这个算法默认是关闭的,在用户需要的时候,做细微的参数配置,就可以打开这个算法。也就是说,默认我们连这个算法都没有开启。
为什么不采样呢?
因为我们信奉的金典是,基于业务的端到端。只要想做到端到端的业务追踪,任何形式的采样,都可能直接导致某一个关键请求的缺失。或者换句话说,我们也在采样,只不过样本覆盖率是100%。这其实直接给我们带来了两个极大的挑战:
1. 如何保持性能,包括数据采集性能,和数据处理性能
我们确实为性能付诸了极大的努力,比如数据格式,数据结构,传输协议,数据压缩,等等,自豪地告诉大家,我们基本可以保证对用户低于5%的性能损耗。如果打开了上面所述的算法开关,则可以将性能损耗有效降低到1%以下。
2. 取得了大量的数据,如何对这海量数据进行分析
请求的事务数据:一个应用中的事务基本是不可枚举的,因为有各种参数的存在;那么在各种参数存在的前提上,怎么对响应时间进行分析?这方面各厂商的做法是对这段时间内请求时间最慢的事务进行排序,列出***0,这是相当不负责任的做法。
为什么不负责任,客户的原话是这样的:我知道这就是我的***0,然后呢?天天说这个***0,周周说,月月说,这并不能反映我的应用健康状态。我们需要关注的是,某段时间内,请求次数又多,响应时间又相对较慢的这些事务。
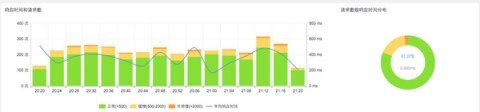
于是我们提出了三个维度的交叉:单位时间,请求次数,响应时间。首先构思这样一幅矩阵图,X轴是时间,左Y轴是请求次数,右Y轴是平均响应时间。这些事务以向量散落在这个象限内,那么我们可以得出,距离XY的左原点,距离最远的,即是我们所关注的。
演化之后,我们得到了这个柱状的散点图。