【51CTO.com快译】本文评析了现代数据架构所需要的几个部分。
为了让大数据在大范围内实际可用,许多企业组织正竭力采用易于使用的数据分析技术。也许他们应考虑将部分功能外包到云端。如果选择一种大数据即服务解决方案,可以处理像Hadoop、Spark和Hive等这些大数据技术很耗费资源、很耗费时间的操作方面,企业就能专注于大数据的好处,少关注枯燥乏味的工作。
大数据的出现带来了以下几方面的基本问题:
- 企业组织如何发挥其潜力
- 如何将其价值引入到企业组织的更广泛部门
- 如何将该数据与之前就有的企业数据仓库结合起来,比如企业数据仓库(EDW)和数据集市
如今商业化应用的主流大数据技术是Apache Hadoop。它经常与Hadoop庞大的生态系统中其它技术结合使用,比如Apache Spark内存处理引擎、Apache Hive数据仓库基础设施和Apache HBase NoSQL存储系统。
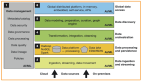
企业要将大数据纳入到其核心企业数据架构,势必需要改动或购置大数据即服务技术。适合如今需求的现代数据架构应当包括以下这几个部分:
Hadoop上的高性能、分析就绪的数据仓库
大数据如何才能做到速度快、随时可供分析?构建便于分析的大数据环境的一个***实践就是,可以Hadoop数据湖创建分析型数据仓库,并封装进最常用的数据集,然后建立维度模型。有了在Hadoop上便于分析的数据仓库,企业组织就能获得最快的查询响应。这种模型便于业务用户了解,它们便于探究业务环境逐渐发生了怎样的变化。
这个分析数据仓库不但要支持报告已知用例,还要支持探究分析非计划场景。然而整个过程对用户来说是无缝的,不需要知道是否需要直接查询Hadoop上的分析型数据仓库。
便于“业务语言”数据分析的语义层
大数据如何才能更加易于实际业务中的用户访问?为了隐藏原始数据中的复杂性,并以通俗易懂的业务术语将数据展示给业务用户,就需要语义覆盖层(semantic overlay)。这个语义层是数据的逻辑表示,可以在其中运用业务规则。
比如说,语义层可以将“高价值客户”定义为“时间在三年以上,经常购买新产品或续约的那些客户”。“高价值客户”方面的数据可以从不同的表格获取,经过不同层次的计算和转换,***进入到语义层,这一切都是查询“高价值客户”的业务用户所看不见的。
之前,业务用户不得不直接查询Hadoop,这不切实际,或者要求IT部门提供信息,这意味着在报告请求排队中等待。语义层让业务用户能够使用熟悉的业务术语,分析和探究数据――不需要等待IT部门优先处理请求。这还便于针对不同的用户,可以重复使用数据、报表和分析,保持一致性,并且让IT部门不需要逐个情况地应对每个请求。
多租户大数据环境
如何在整个企业组织访问大数据,不管人们位于何处?由于广泛需要数据分析,企业组织需要采用一种混合的集中式和分散式数据方法。这让不同的术语可以兼顾本地数据集和语义定义,同时又访问IT部门创建的企业数据资源。
这种混合方法可以用多租户数据架构来实现。在这种架构中,IT部门收集和清理数据后,放入到共享的Hadoop数据湖,并利用该数据,准备好集中式语义层和分析型数据仓库。
随后,IT部门为不同的业务小组(比如财务、销售、营销和客户支持),创建集中式数据环境的虚拟拷贝。这样一来,IT部门保留了数据治理和语义规则方面的统一权限,同时业务小组和部门又可以对照存储在Hadoop中的历史或企业数据,真正看到其日常业务活动的影响。
用户界面友好的消费分析
怎样才使用户容易掌握大数据分析?就最终用户处理大数据而言,***要考虑的一个问题是,数据将以哪种形式来表示。这些数据界面将满足每个用户的独特、个别的要求。这一需求包括:为业务用户提供高度交互和响应的仪表板,为分析员提供界面直观的可视化发现机制,以及为信息消费者提供计划报表。
虽然每一种方式都很独特,但***实践是确保每个界面都不是单独的工具,那样在创建、协作和发布信息时可以确保一致性和准确性。只有通过确保数据价值仍然一致的语义层,才能做到这一点,而数据表示可能因用户界面而异。
大数据对企业来说越来越重要,它是企业数据架构的一个基本部分。想充分发掘大数据的潜力,企业就要加快购置可高效地分析和存储数据的技术。面向大数据和分析的云解决方案让这成为了可能。有了这种解决方案,企业就能为未来的数据增长作好充分准备,反过来在日益发展的大数据生态系统中有出色的表现。
原文标题:Big Data as a Service delivers the analytics benefits without the grunt work
【51CTO译稿,合作站点转载请注明原文译者和出处为51CTO.com】