之前有说过要设计一个工作流调度器。开发一个完善的工作流调度器应该并不是一件简单的事情。但是通过Spark Streaming(基于Transfomer架构的理念),我们可能能简化这些工作。我在这块并没有什么经验,这只是一个存在于脑海中的东西。
下面是Azkaban的架构图:
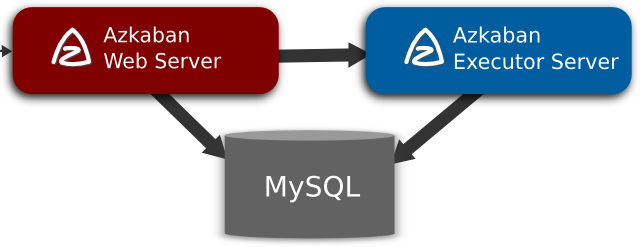
也就是说要搭建一个稳定可靠的Azkaban的工作流调度器,你可能需要
- 两台 互为主备MySQL
- 两台Executor Server
- 一台Web Server
你需要做架构设计,考虑WebServer 和 Executor Server的通讯问题
扩展性问题。Executor 能够动态调整?
稳定性问题。毕竟24小时运行的
然而,我们其实是不需要关注这么多东西的。我们真正关注的是:
- Web UI
- 工作流的生成,解析,运行和存储
其他的都是基础设施。按照Transfomer架构的设计理念,我们应该可以找到一个Estimator ,作为我们的基础设施,我们只要关注上面两点即可,不需要为部署,高可用,稳定等发愁。同时我们也希望譬如WebUI等工作不是从头开始,而是按部就班添加新功即可。所以有了Estimator,我们只要做三点:
- 实现业务逻辑,也就是工作流的生成,解析,运行和存储等操作。
- 实现管理页面逻辑
- 指定需要的资源cpu/内存,就能Run起来这个Transformer
我搜罗了一圈,发现Spark Streaming 是能够满足该需求的一个Estimator。
这得益于,Spark Streaming 从某个角度而言就是个定时任务调度系统,也就是我们说的微批处理。对于工作流调度器而言,无非就是每个周期(duration)在Driver端启动线程扫描MySQL,实现任务的分发和执行。
那如果实现一个类似Azkaban 能够的做的事情,前面我们提到,要做三件事情,分别对应为:
1.实现业务逻辑,也就是工作流的生成,解析,运行和存储等操作。其中生成,解析,存储 三个环节可以放在Driver端,也可以都放在Executor 端。也就是说:Driver的设计可重可轻。重的设计可由Driver读取MySQL 并且解析成工作流任务,然后发送给Executor 去执行。轻的设计Driver仅仅是读取MySQL,然后就简单将id分发给各个Executor,各个Executor 负责解析执行和反馈结果。
2.增强 Spark Streaming UI,添加管理页面,实现Azkaban Web Server类似界面。
3.按标准的Spark Streaming 程序提交该实现到集群即可完成部署。
我们看到,我们真正做到了只关注核心业务逻辑的实现,所谓部署,安装,运行等环节都实现了平台化(其实Estimator完成了)。 而且实现了资源的细粒度(CPU/内存)划分,而不再是以服务器为基本单元。
事实上,我们也可以将一个Spark Streaming当做一个crontab 任务,这样就自然具有了一个分布式的crontab系统,并且提供更友好的管理,甚至能将任务本身融入到crontab中。
后话
Spark Streaming 不一定是最合适的Estimator,你可以自己实现一套类似的Estimator,最终形成所谓的 Azkaban On Yarn的程序。