一、冲突的根源
开发团队的目标:满足产品的功能需求,把用户的需求实现,发布到现网,交付到用户手里。
从之前的敏捷过程来看,其实开发/测试甚至是QA团队的目标是一致的。
运维团队的目标:质量永远是第一位的。这导致一个有意思的现象:
变更是主要的故障之源,你同意么?
之前在一篇论文中给出数据,无论是硬件的维护还是网站的维护,人为变更是引入故障的主要原因(如图1)。在没有找到有效的手段之前,特别是手工时代,运维一定是抗拒变更的,你同意么?
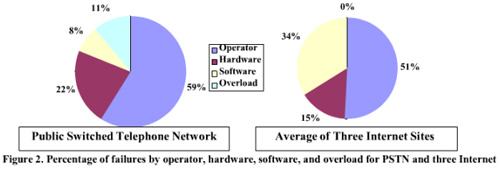
图1:由人主导的变化是故障主要的原因
但现实不是运维所设想的那样,特别是对于一些持续迭代的2C产品来说,”变化是唯一不变的规律“,那就意味着变更是常态。
此时,我们可以得出一个非常有用的结论,开发和运维的冲突在某些情况下会被放大,比如说运维能力很弱,部门墙的出现。图2进一步归纳和阐述了这种冲突的原因。
两个不同的团队把各自的目标和要求形成一定的推力推向对方团队,然而部门墙的存在,让这种推力存在阻隔。
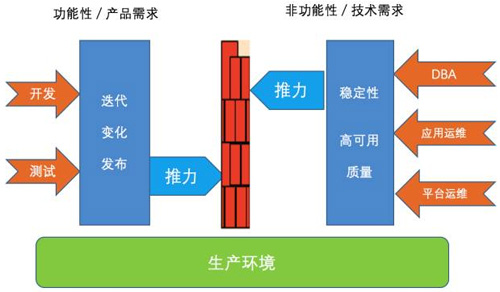
图2:Dev/Ops的冲突之源
甚至,我有时候把这幅图比喻成一个舞台(生产环境)上两个击剑手,在进行一场对抗比赛。
二、冲突的表现形式
在一个企业内冲突的最直接表现形式就是抱怨,抱怨的最直接感受就是从自己的角度总是觉得对方不够好。
因此,我就从整个软件或者特性交付的角度来分析,把过程分解成几个典型阶段,来看这个抱怨是如何产生的。
大家也可以根据自己的经验,也总结一下自己感受到的冲突表现及其抱怨来自何处(尽量明确而具体),然后我们一起走向后面的解决方案。
2.1.程序发布前
开发的抱怨:
◆找运维要个资源,怎么那么难呢?
◆找运维要几台设备,要填写这么复杂的表格?研发内部都没这么复杂。
◆运维的资源交付流程太长了,能不能再快一些?
◆运维的交付流程是否可以透明一些,不要让我经常来提醒运维,进度怎么样了?
◆运维的流程太多了,走OA,走领导审批,就不能简单一点么?
◆运维对技术架构把握能力不够,架构评审给不出有用的建议!
◆感觉运维的第一要求永远盯着我们服务器是不是用多了?
运维的抱怨:
◆开发永远都是程序要发布了,才来告诉运维要怎么做怎么做?!
◆开发老拍脑袋告诉我要给多少资源,为什么不合理评估呢?!
◆开发的技术架构评审为什么不邀请运维参加?
◆开发的技术架构考虑运维的需求太少,很多研发是真正的程序研发。
◆开发把运维当作资源提供者/事务执行着,倒不如让他们自己做运维好了。
2.2.程序发布中
开发的抱怨:
◆运维的发布流程好复杂好暴力,不区分业务和发布类型,都必须走很多领导审批,并且是深夜发布。
◆我明明写了详细的部署文档,但每次部署为什么还需要研发深度参与?
◆运维的发布好慢,一个发布要搞半天,感觉比我们研发过程还长。
◆运维的部署不能自动化么?为什么这么久还是要人工?我都想自己做个发布平台了。
◆有些不重要的发布,是不是可以让研发自己来做?不想每次都去触碰运维复杂的流程。
运维的抱怨:
◆这个部署文档好复杂,里面那么多坑要注意,每次部署都要耗费很多时间。
◆研发这个程序写得够呛,之前和他们反馈过,把配置不要搞成每台不一样,还是没改过来。
◆研发有没有遵守运维的规范,不和我沟通,按照自己的方便写出业务程序,让我运维。
2.3.程序发布后
开发的抱怨:
◆程序出问题,为什么运维不能自己定位问题?都需要我深度参与。
◆程序发布后出现bug,这个时候需要走紧急流程,必须经过领导,是否真的需要这么麻烦?
◆程序发布后的状态没法看到,我只能找他们要账户登录去看,能不能做成一个系统给我看相关信息。
◆运维的监控能力感觉真的很弱,出问题都是靠用户或者我们看日志发现的。
运维的抱怨:
◆开发的程序好烂,刚刚发布了,就出bug了。
◆程序bug了,又在催我快速解决,连研发自己找bug都没那么快,我哪有那么快呀!
◆开发程序异常log输出太少了,非常不利于快速定位问题。
2.4.持续运营阶段
开发的抱怨:
◆运维为什么不能给一个帐号给我,让我登录服务器去看服务状态。
◆运维内的平台一些权限应该给我,我想看看服务的运行状况。注:很多企业估计研发都没有登录过监控系统,更别谈CMDB了。
◆运维的日志分析能力很弱,我自己要写临时程序来做日志分析。
◆不出故障,我是感觉不到运维存在的。
运维的抱怨:
◆开发写的程序又出bug了,又出重大故障,我又要救火了!
◆开发的程序架构设计好烂,这点技术问题都没有提前考虑,导致这个问题必须要靠人来解决。
◆开发的KPI体系里面应该包含运维的质量和成本指标,需要他们一起来抗,否则压力永远都是在我们运维。
◆我们搞了一些数据报告,开发根本不关心,他们只关心需求实现,不关心运维的需求。
进一步深入技术分析的话,可以找到一些冲突的根源:
◆研发和测试部门是以敏捷方法论来驱动的。
◆而运维部门是构建在ITIL体系上的ITSM管理的思路。
前者有一些管理工具(持续集成,看板)/实践(站立会议/测试驱动/极限编程)/文化(价值观/团队融合)等等。
后者所依赖的ITSM的流程体系明显是滞后于前者敏捷体系的能力。
也就是说,两个团队不同的IT思维/能力的不同,造就彼此的输出的不同,这才是冲突的技术之源。
所以要想解决问题,核心的思路是:要找到一个统一的方法论(DevOps?)来融合两个IT团队个字的目标和方法论,当然冲击最大的还是运维团队,需要把自己的流程能力转化成自动化平台的能力。
从方法论上看,我自己觉得DevOps是Agile方法论的一次很自然的延伸。
其实从各自的角度能看到大家彼此的关注点,这些关注点有些是重叠的,有些是完全不对焦的。
三、冲突的解决方案
寻求解决方案比抱怨更重要,在抱怨的地方,才有改进的机会。但我这个地方避免用DevOps这个词来笼统的寻求解决方案。
我个人觉得需要做一些转变,核心的转变是两点:第一是拆墙;第二是换舞台,如下图:
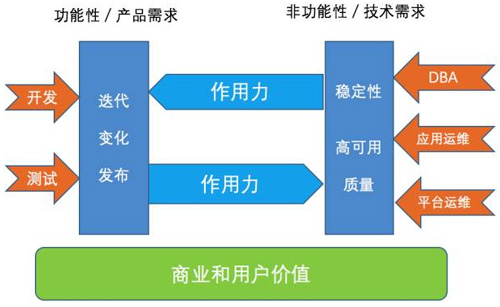
图3:拆墙和共同的价值支撑体系
拆墙,研发/运维团队把彼此的作用力触达到对方,感受到彼此的要求和能力。
换舞台,把底层的舞台给换了,“经济基础决定上层建筑”,底层换了,上面的思路也就随之变化。
措施1:共享一致的目标/价值/状态
对于研发/测试/运维团队来说,就需要把大家的目标/价值/状态做个对齐。之前写过IT运维的目标体系是质量/成本/效率/安全,其实这个可以传递到研发/测试团队,并且是和业务功能需求完全不冲突的。
从目标来说,分阶段性的目标和长远目标:
◆阶段性的目标其实可以看业务部门的短期需求和规划,从而反推IT能力的要求,比如说敏捷基础设施交付,持续发布。
◆长远的目标,其实是可以规划自己的IT能力主线,比如说容器化和架构服务化,然后分解到阶段性的目标上,这个目标是需要和研发对齐的。
我说的状态比较特殊。其实,我更希望运维把线上服务的运行状态进行透明化和可视化。然后交付给我们的研发/测试部门,不要让自己的能力成为黑盒子。这样:
◆一则,督促自己不断提升自己的能力。
◆二则,可以基于状态促进研测不断优化技术服务能力。所以更需要把这种思维传递给开发,让其去建设一个非黑盒子系统。
研发是有技术和责任辅助运维实现这一目标的。
状态的一致性,其实是具体的驱动措施了,俗称状态看板,它分业务价值看板BVD和服务状态看板,详细如交易看板,服务可用性看板,服务成本看板,服务性能看板,事件看板,问题看板等等。
措施2:IT能力的平台化驱动
在之前的篇幅中,我说过ITSM的运维体系能力是大大滞后的,明显不能满足当前业务快速迭代的需要,运维的问题还是必须要运维来挑头解决。
生产环境,运维是第一负责人,必须改变过去的流程思维,建立自动化和数据化的运维平台。
从环境管理的角度来看,需要以生产环境的平台管理能力覆盖为首先的灰度点,然后逐渐覆盖预发布/测试环境,最后才是开发环境。
有了平台化能力之后,运维的作用力才能顺利推进到研发和测试那边,否则就会出现制定了规范无法落地。
不信,你定义一个现网日志监控规范看看?
所以,我把图4中绿色部分的能力实现都认为是运维部的,有没有感觉到你在搭建一个舞台?的确如此!
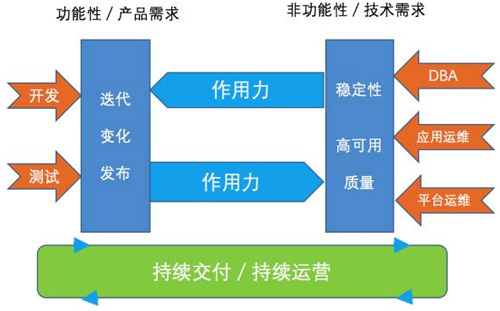
图4:平台化是运维能力延伸的最好方式
措施3:“把想法装进别人的脑袋”
每个团队不能孤立的去看或者解决问题,当我们把能力延伸到对方之后,其实就是在干“把想法装进别人的脑袋”的事情,对两个团队来说都是难事。
之前讲过研发团队的Ops-friendly和运维团队的Dev-friendly,也在讲一定有照顾到别人的诉求才能friendly。
2014年的puppet报告,也在讲团队内培养DevOps是多么的重要,其实就是在讲理念和实践刷新成一致状态。
图5:多元化的思维,事半功倍
任务冲突不可避免,冲突的形式也是各式各样,冲突的解决方案也不尽相同。
本文是自己对该问题的一个整体思考思路,希望能触发我们一起来思考。最后引申一个话题——“NoOps”(无运维),大家也一起思考一下,是否有可能?其实本文也有一些答案。