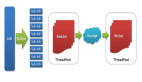
SQL处理二维表格数据,是一种最朴素的工具,NoSQL是Not Only SQL,即不仅仅是SQL。从MySQL导入数据到HDFS文件系统中,最简单的一种方式就是使用Sqoop,然后将HDFS中的数据和Hive建立映射。通过Sqoop作为数据桥梁,将传统的数据也存入到NoSQL中来了,有了数据,猴戏才刚刚开始。
猴年伊始
SQL处理二维表格数据,是一种最朴素的工具,查询、更新、修改、删除这四种对数据的基本操作,是处理数据的一个巨大进步。近些年,各种新的数据处理技术兴起了,都想革SQL的命,这些技术也被大家统称为NoSQL。
NoSQL最初的意思是No SQL,估计应该是想和SQL划清界线,就像GNU的递归缩写GNU is Not Unix一样。后来发现,虽然大量的NoSQL技术起来了,但SQL还是活得好好的,照样发挥着很多不可替代的作用。渐渐地,大家也发现,原来这些新技术,也只是在不同的应用场景下对SQL的补充,因此也慢慢为NoSQL正名了,原来是Not Only SQL,即不仅仅是SQL,还有很多其它的处理非结构化数据和应用于各种场景的技术。甚至很多技术,虽然是在NoSQL的框架下,但也慢慢的又往SQL方向发展。
NoSQL是一种技术或者框架的统称,包括以Mongodb,Hadoop,Hive,Cassandra,Hbase,Redis等为代表的框架技术,这些都在特定的领域有很多实际的应用。而SQL领域的开源代表自然是MySQL了。
很多企业中,业务数据都是存放在MySQL数据库中的,当数据量太大后,单机版本的MySQL很难满足业务分析的各种需求。此时,可能就需要将数据存入Hadoop集群环境中,那么本文的主角Sqoop便适时的出现了,用来架起SQL与NoSQL之间的数据桥梁。
MySQL导入HDFS
从MySQL导入到HDFS文件系统中,是最简单的一种方式了,相当于直接将表的内容,导出成文件,存放到HDFS中,以便后用。
Sqoop最简单的使用方式,就是一条命令,唯一需要的是配置相应的参数。sqoop可以将所有参数写在一行上,也可以写在配置文件里面。因为导入的选项过多,通常我们都把参数写在配置文件里面,以便更好的调试。在导入到HDFS的过程中,需要配置以下参数:
- 使用import指令
- 数据源配置:驱动程序,IP地址,库,表,用户名,密码
- 导入路径,以及是否删除存在的路径
- 并行进程数,以及使用哪个字段进行切分
- 字段选择,以及字段分隔符
- 查询语句:自定义查询,Limit可以在此处使用
- 查询条件:自定义条件
配置文件示例:
# 文件名:your_table.options
import
--connect
jdbc:mysql://1.2.3.4/db_name
--username
your_username
--password
your_passwd
--table
your_table
--null-string
NULL
--columns
id, name
# --query
# select id, name, concat(id,name) from your_table where $CONDITIONS limit 100
# --where
# "status != 'D'"
--delete-target-dir
--target-dir
/pingjia/open_model_detail
--fields-terminated-by
'\001'
--split-by
id
--num-mappers
1- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
示例参数说明:
- import指令,说明是导入,这儿的“入”是相对于hdfs来说的,即从MySQL导入到hdfs文件系统中。
- 以双横线开头的是参数,其中connect配置数据库驱动及来源,此处配置了mysql及ip地址和数据库名。
- username, password配置用户名密码。table配置来源表名,此处需要注意,如果后面使用了query的方式,即指定了查询语句,此处table需要注释。
- columns配置了从表中读取的字段,可以是全部,也可以是部分。同上所求,如果指定了query则不需要配置columns
- query是自己指定导出的sql语句,如果需要自定义导出,则使用。注意,这儿有一个where条件,无论是否使用条件,都需要带上where $CONDITIONS,$CONDITIONS是后面配置的条件。
- where用于单独设置查询条件
- target-dir用于指定导入的目录,从mysql中导入到hdfs中的数据是直接导入到目录,而不是直接指定文件,文件名会自动生成。另外,如果需要在hive中使用分区,此处应该用子分区的名字。比如,增加一个year=2015的分区,那么,建立目录的时候,把数据存入子目录 year=2015中去,这样后面在hive中直接增加分区映射即可。delete-target-dir是如果目录存在便删除,否则会报错。
- fields-terminated-by用于配置导出的各字段之间,使用的分隔符,为防止数据内容里面包括空格,通常不推荐用空格,'\001'也是Hive中推荐的字段分隔符,当然,我们也是为了更好的在Hive中使用数据才这样设置。
- num-mappers是指定并行的mapper(进程数),这也是使用sqoop的一大优势,并行可以加快速度,默认使用4个进程并行。同时,split-by需要设置为一个字段名,通常是id主键,即在这个字段上进行切分成4个部分,每个进程导入一部分。另外,配置几个进程数,最后目录中生成的文件便是几个,因此对于小表,建立设置num-mappers为1,最后只生成一个文件。
上面使用了配置文件的方式,在配置文件中,可以使用#注释,也可以使用空行,这样方便做调试。配置好上面的参数文件,即可调用测试:
sqoop --options-file your_table.options- 1.
如果不报错,最后会显示导入的文件大小与文件行数。
这是一个导入速度的记录,供参考:
|
增量导入
HDFS文件系统是不允许对记录进行修改的,只能对文件进行删除,或者追加新文件到目录中。但Mysql数据中的增、删、改是最基本的操作,因此导入的数据,可能一会儿就过期了。
从这儿也可以看出,并非所有数据都适合导入到HDFS,通常是日志数据或者非常大的需要统计分析的数据。通常不太大的表,也建议直接完整导入,因为本身导入速度已经够快了,千万级别的数据,也只是几分钟而已。
如果不考虑数据的修改问题,只考虑数据的增加问题,可以使用append模式导入。如果需要考虑数据修改,则使用lastmodified的模式。
增量的方式,需要指定以下几个参数:
--check-column
filed_name
--incremental
append|lastmodified
--last-value
value- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- check_colume:配置检查增量的字段,通常是id字段,或者时间字段
- incremental: 增量的方式,追加或者最后修改,追加从上一次id开始,只追加大于这个id的数据,通常用于日志数据,或者数据不常更新的数据。最后修改,需要本身在 Mysql里面,数据每次更新,都更新维护一个时间字段。在此,表示从指定的时间开始,大于这个时间的数据都是更新过的,都要导入
- last-value: 指定了上一次的id值或者上一次的时间
映射到hive
导入到HDFS中的数据,要进行统计分析,甚至会需要对多个文档进行关联分析,还是有不便之处,此时可以再使用Hive来进行数据关联。
首先,需要在Hive中建立表结构,只选择性的建立导入的数据字段,比如导入了id和name两个字段,则Hive表也只建立这两个字段。
另外,最好通过external关键字指定建立外部表,这样Hive只管理表的元数据,真实的数据还是由HDFS来存储和手工进行更新。即使删除了Hive中的表,数据依然会存在于HDFS中,还可以另做它用。
建表,要指定字段的数据格式,通常只需要用四数据来替换Mysql的数据:
| string ==> 替换char,varchar int ==> 替换int float ==> 替换float timestamp ==> 替换datetime |
另外,还需要指定存储格式,字符分隔符和分区等,常用的一个建表语句如:
CREATE external TABLE your_table (
id int,
name string
)
PARTITIONED BY (pdyear string)
ROW FORMAT DELIMITED fields terminated by '\001'
STORED AS TEXTFILE- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
上面指定了一个分区pdyear,字段分隔符为'\001',存储成TEXTFILE格式,数据文件的目录为/path/your_table(从MySQL导入到HDFS的目录)。
如果导入的数据,配置了分区,即如下目录结构:
/path/your_table/pdyear=2015
/path/your_table/pdyear=2016
则建立表后,表里面没有对应上数据,需要添加分区到hive表中,在hive中执行以下语句:
alter table your_table add partition (pdyear='2015') location '/path/your_table/pdyear=2015';
alter table your_table add partition (pdyear='2016') location '/path/your_table/pdyear=2016';- 1.
- 2.
完成上面的操作后,即可以在Hive中进行查询和测试,查看是否有数据。Hive的hql语法,源于mysql的语法,只是对部分细节支持不一样,因此可能需要调试一下。
HDFS导出到MySQL
在Hive中进行了一系列的复杂统计分析后,最后的结论可能还是需要存储到Mysql中,那么可以在Hive语句中,将分析结果导出到HDFS中存储起来,最后再使用Sqoop将HDFS的文件导入到MySQL表中,方便业务使用。
导出的配置示例:
export
--connect
jdbc:mysql://1.2.3.4/db_name
--username
your_username
--password
your_passwd
--table
your_table
--input-null-string
'\\N'
--update-mode
allowinsert
--update-key
id
--export-dir
/path/your_table/
--columns
id,name
--input-fields-terminated-by
'\001'- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
参数说明:
- export:指令说明是导出
- update-mode:allowinsert,配置了,使用更新模式,即如果Mysql中已经有数据了,则进行更新,如果没有,则插入。判断的字段使用update-key参数配置,需要这个字段是唯一索引的字段。
- input-null-string:Hive中,导出的NULL为字符\N,要还原到Mysql中,依然为MyQL的Null的话,需要使用这个配置,指定NULL的字符串为'\N'
- 另外,导出的时候,如果Mysql表中有自动增长的主键字段,可以留空,生成数据的时候会自动填充。
猴戏开始
将MySQL中的数据导入到HDFS中,又将HDFS中的数据建立了到Hive表的映射。至此,通过Sqoop工具作为SQL与NoSQL的数据桥梁,将传统的数据也存入到NoSQL中来了,有了数据,便是开始。