令人惊讶的是,Hadoop在短短一年的时间里被重新定义。让我们看看这个火爆生态圈的所有主要部分,以及它们各自具有的意义。
对于Hadoop你需要了解的最重要的事情就是,它不再是原来的Hadoop。
这边厢,Cloudera有时换掉HDFS改用Kudu,同时宣布Spark是其圈子的核心(因而一概取代发现的MapReduce);那边厢,Hortonworks加入了Spark阵营。在Cloudera和Hortonworks之间,“Hadoop”集群中唯一可以确信的项目就是 YARN。但是Databricks(又叫Spark人)偏爱Mesos而不是YARN;顺便说一句,Spark不需要HDFS。
不过,分布式文件系统依然有用。对Cloudera的Impala来说,商业智能是一种理想的使用场合;而分布式列式存储系统Kudu针对商业智能进行了优化。Spark很适合处理许多任务,但有时候你需要像Impala这样的大规模并行处理(MPP)解决方案来达到目的,而Hive仍是一种有用的文件到表管理系统。即使你因为专注于Spark的内存中实时分析技术而没有使用Hadoop,到头来仍可能到处使用Hadoop的部分。
Hadoop绝对没有消亡,不过我确信,知名研究机构Gartner的下一篇文章会这么认为。但Hadoop绝不再是原来的Hadoop。
现在你需要知道这个新的Hadoop/Spark生态圈里面有什么?我在去年探讨过这个话题,但出现了许多新气象,这回我几乎从头开始来介绍。
Spark
Spark的运行速度正如其名;更重要的是,API用起来容易得多,所需的代码比之前的分布式计算模式来得少。IBM承诺会培训100万名新的 Spark开发人员,为这个项目备好了庞大资金,Cloudera宣布Spark是我们知道与其一个平台(One Platform)计划配套的所有项目的核心,加上Hortonworks全力支持Spark,鉴于这种形势,我们可以肯定地说,业界已将“技术环球小姐”(Tech Miss Universe)这顶桂冠授予了Spark(但愿这回没有弄错)。
成本因素也在推动Spark迅猛崛起。过去在内存中分析数据成本高昂,但由了云计算和更高的计算弹性,无法装入到内存(至少在分布式计算集群上)中的工作负载的数量在日益减少。同样,我们谈论的不是你的所有数据,而是为了计算结果而需要的一小部分数据。
Spark仍然不尽如人意――如果在生产环境中使用它,我们确实看到了这一幕,但是缺点值得忍受。Spark其实速度快得多,而且完全有了改进。
具有讽刺意味的是,Spark方面动静最大的恰恰与流数据有关,而这是Spark的最大软肋。Cloudera宣布旨在让Spark流数据技术适用于80%的使用场合,就考虑到了这一缺陷。不过,你可能仍需要探究替代方案,以实现亚秒级或大容量的数据获取(而不是数据分析)。
Spark不仅避免了需要MapReduce和Tez,还可能避免了Pig之类的工具。此外,Spark的RDD/DataFrames API并不是进行抽取、转换和加载(ETL)及其他数据转换的糟糕方法。与此同时,Tableau及其他数据可视化厂商已宣布打算直接支持Spark。
2. Hive
Hive让你可以对文本文件或结构化文件执行SQL查询。那些文件通常驻留在HDFS上,这时你可以使用Hive,Hive可以将文件编入目录,并暴露文件,好像它们就是表。你常用的SQL工具可以通过JDBC或ODBC连接到Hive。
简而言之,Hive是一个乏味、缓慢但又有用的工具。默认情况下,它将SQL任务转换成MapReduce任务。你可以切换它,使用基于DAG的Tez,而Tez的速度快得多。还可以切换它,使用Spark,不过“alpha”这个词无法体现真正体验。
你需要知道Hive,因为许多Hadoop项目一开始“就让我们将数据转储到某个地方”,然后“顺便提一下,我们想在常用的SQL图表工具中看看数据。”Hive是最直观简单的办法。如果你想高效地查看数据,可能需要其他工具(比如Phoenix或Impala)。
3. Kerberos
我讨厌Kerberos,它也不是那么喜欢我。遗憾的是,它又是唯一为Hadoop全面实施的验证技术。你可以使用Ranger或Sentry等工具来减少麻烦,不过仍可能要通过Kerberos与活动目录进行集成。
4. Ranger/Sentry
如果你不使用Ranger或Sentry,那么大数据平台的每一个部分都将进行自己的验证和授权。不会有集中控制,每个部分都会以自己的独特方式看世界。
那么该选择哪一个:Ranger还是Sentry?这么说吧,眼下Ranger似乎有点领先,较为全面,不过它是Hortonworks的产物。 Sentry则是Cloudera的产物。各自支持Hadoop堆栈中相应厂商支持的那一部分。如果你没打算获得Cloudera或 Hortonworks的支持,那么我要说,Ranger是眼下更胜一筹的解决方案。然而,Cloudera走在Spark的前面,该公司还宣布了安全方面的重大计划,作为“一个平台”战略的一部分,这势必会让Sentry处于领先。(坦率地说,如果Apache运作正常,它会对这两家厂商施加压力,共同开发一款解决方案。)
5. HBase/Phoenix
HBase是一种完全可以接受的列式数据存储系统。它还内置到你常用的Hadoop发行版中,它得到Ambari的支持,与Hive可以顺畅地连接。如果你添加Phoenix,甚至可以使用常用的商业智能工具来查询HBase,好像它就是SQL数据库。如果你通过Kafka和Spark或 Storm获取流数据,那么HBase就是合理的着陆点,以便该数据持久化,至少保持到你对它进行别的操作。
使用Cassandra之类的替代方案有充分理由。但如果你使用Hadoop,那就已经有了HBase――如果你向Hadoop厂商购买支持服务,已经有了支持HBase的功能――所以这是个良好的起点。毕竟,它是一种低延迟、持久化的数据存储系统,为原子性、一致性、隔离性和持久性(ACID)提供了相当给力的支持。如果Hive和Impala的SQL性能没有引起你的兴趣,你会发现HBase和Phoenix处理一些数据集比较快。
6. Impala
Teradata和Netezza使用MPP来处理跨分布式存储的SQL查询。Impala实际上是基于HDFS的一种MPP解决方案。
Impala和Hive之间的最大区别在于,你连接常用的商业智能工具时,“平常事务”会在几秒钟内运行,而不是几分钟内运行。Impala在许多应用场合可以取代Teradata和Netezza。对不同类型的查询或分析而言,其他结构可能必不可少(针对这种情况,可着眼于Kylin和 Phoenix之类的技术)。但通常来说,Impala让你可以避开讨厌的专有MPP系统,使用单一平台来分析结构化数据和非结构化数据,甚至部署到云端。
这与使用正宗的Hive存在诸多重叠,但Impala和Hive的操作方式不一样,有着不同的最佳适用场合。Impala得到Cloudera的支持,但未得到Hortonworks的支持,Hortonworks改而支持Phoenix。虽然运行Impala不太复杂,但是你使用Phoenix可以实现同样的一些目标,Cloudera现正将注意力转向Phoenix。
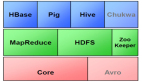
7. HDFS(Hadoop分布式文件系统)
由于Spark大行其道,所谓的大数据项目不断迁移到云端,HDFS不如去年来得重要。但是它仍然是默认技术,也是概念上比较简单的实现分布式文件系统的技术之一。
8. Kafka
分布式消息系统(如Kafka提供的系统)会完全淘汰像ActiveMQ这样的客户机/服务器工具。即便Kafka没有用在大多数流数据项目上,至少也用在许多流数据项目。它也很简单。如果你使用其他消息传递工具,会觉得它有点原始简陋,但在大多数情况下,你无论如何也不需要MQ类解决方案提供的细粒度路由选项。
9. Storm/Apex
Spark处理流数据不是很擅长,但是Storm如何呢?它速度更快,延迟更低,而且耗用更少的内存――大规模获取流数据时,这点很重要。另一方面,Storm的管理工具较为逊色,API也不如Spark的API一样好。Apex更新更好,但还没有得到广泛部署。我仍会在默认情况下选择Spark 处理不需要亚秒级的任何事务。
10. Ambari / Cloudera Manager
我见过有人不用Ambari或Cloudera Manager,试着监视和管理Hadoop集群。效果不好。这两种解决方案在比较短的时间里,让Hadoop环境的管理和监控功能取得了长足发展。不妨与NoSQL领域作个比较:NoSQL领域在这方面远远不如Hadoop一样先进,尽管用的是更简单的软件,组件数量少得多,你肯定很想知道那些 NoSQL人员把大量资金究竟花在了哪里。
11. Pig
我想这恐怕是Pig最后一年上我的名单。Spark的速度快得多,可以用于许多同样的ETL场合,而Pig Latin(没错,他们就是这么称呼这门语言的)有点怪异,而且常常令人沮丧。正如你想象,在Spark上运行Pig需要费老大的劲。
从理论上来说,在Hive上执行SQL的人可以改用Pig,就像他们过去由SQL改用PL/SQL那样,但事实上,Pig不如PL/SQL来得简单。介于普通SQL和正宗Spark之间的技术可能还有生存余地,但我认为Pig不是这种技术。来自另一个方向的是Apache Nifi,这让你可以做一些同样的ETL,但是少用或不用代码。我们已经使用Kettle减少了编写的ETL代码数量,这相当棒。
12. YARN/ Mesos
YARN和Mesos让你能够跨集群执行任务队列和调度操作。每个人都在尝试各种方法:Spark到YARN、Spark到Mesos、Spark 到YARN到Mesos,等等。但要知道,Spark的独立模式对于忙碌的多任务多用户集群来说不是很切实际。如果你不专门使用Spark,仍运行 Hadoop批处理任务,那么眼下就选择YARN。
13. Nifi /Kettle
Nifi将不得不竭力避免仅仅是Oozie的改进版。诸多厂商声称Nifi是物联网的解决之道,不过那是营销声势而已。实际上,Nifi好比为 Hadoop与Spring整合。你需要通过转换和队列来管道传输数据,然后按时间表将数据放在某个地方――或者基于触发器,处理来自诸多来源的数据。添加一个漂亮的图形用户界面(GUI),Nifi就成了。其魅力在于,有人为它编写了一大批的连接件。
如果今天你需要这个,但想要更成熟一点的技术,不妨使用Pentaho公司的Kettle(以及其他相关工具,比如Spoon)。这些工具在生产环境中颇有成效已有一段时间。我们用过它们。坦率地说,它们很不赖。
14. Knox
虽然Knox是很强大的边缘保护机制,但它的作用就是,为用Java编写的反向代理系统提供验证。它不是写得很好;举例说,它掩盖了错误。另外,尽管它使用了URL重写,但仅仅在后面添加一个新服务就需要完整的Java实现。
你需要知道Knox,因为如果有人想要边缘保护,这是提供这种保护的“钦定”方式。坦率地说,要是有小小的修改,或者面向HTTPD的mod_proxy的附件,它会更实用,并提供一系列更广泛的验证选项。
15. Scala/ Python
从技术上来说,你可以用Java 8处理Spark或Hadoop任务。但实际上,支持Java 8是事后添加的功能,那样销售人员可以告诉大公司它们仍可以利用原来的Java开发人员。事实上,Java 8是一门新语言,如果你使用得当的话――在在种情况下,我认为Java 8拙劣地模仿Scala。
尤其是对Spark而言,Java落后于Scala,可能甚至落后于Python。本人其实并不喜欢Python,但它得到了Spark及其他工具相当有力的支持。它还有成熟的代码库;就许多数据科学、机器学习和统计应用而言,它将是首选语言。Scala是Spark的第一选择,也越来越多是其他工具集的第一选择。对于“偏运算”的数据,你可能需要Python或R,因为它们的代码库很强大。
记住:如果你用Java 7编写任务,那太傻了。如果使用Java 8,那是由于有人对你老板撒了谎。
16. Zeppelin/ Databricks
大多数人在iPython Notebook中首次碰到的Notebook概念很流行。编写一些SQL或Spark代码以及描述代码的一些标记,添加一个图形,动态执行,然后保存起来,那样别人就能从你的结果获得一些东西。
最终,你的数据被记录并执行,图表很漂亮!
Databricks有良好的开端,自我上一次表示对它腻味以来,其解决方案已经成熟起来。另一方面,Zeppelin是开源的,没必要非得从Databricks购买云服务。你应该知道其中一款这样的工具。学会一款,学另一款不会太费劲。
值得关注的新技术
我还不会将这些技术应用到生产环境,但是一定要了解它们。
Kylin:一些查询需要更低的延迟,于是你一头有HBase;另一头,更庞大的分析查询可能不适合HBase――因此另一头使用 Hive。此外,一再合并几个表来计算结果速度缓慢,所以“预合并”(prejoining)和“预计算”( precalculating)这些数据处理成数据立方(Cube)对这类数据集来说是一大优势。这时候,Kylin有了用武之地。
Kylin是今年的后起之秀。我们已经看到有人将Kylin用于生产环境,不过我建议还是谨慎一点为好。因为Kylin并不适用于一切,其采用也不如Spark来得广泛,但是Kylin也受到同样热烈的追捧。眼下,你对它应该至少了解一点。
Atlas/Navigator:Atlas是Hortonworks新的数据治理工具。它甚至还谈不上完全成熟,不过正取得进展。我预计它可能会超过Cloudera的Navigator,但如果历史重演的话,它会有一个不太花哨的GUI。如果你需要知道某个表的世系,或者没必要逐列(tagging)地映射安全,那么Atlas或Navigator可能正是你需要的工具。如今治理是个热门话题。你应该知道这其中一项新技术的功能。
我宁愿遗忘的技术
下面是我会很高兴地扔到窗外的技术。我之所以这么任性,是因为已出现了更出色地执行同一功能的新技术。
Oozie:在去年的All Things Open大会上,来自Cloudera的Ricky Saltzer为Oozie辩护,说它适用于原本旨在处理的任务――也就是把几个MapReduce任务串连起来;人们对于Oozie颇为不满是要求过高。我仍要说,Oozie一无是处。
不妨举例说明:隐藏错误,功能不是失灵就是与文档描述的不一样、XML错误方面的说明文档完全不正确、支离破碎的验证器,不一而足。Oozie完全自吹自擂。它写得很差劲;要是哪里出了问题,连基本的任务都会变成需要一周才搞得定。由于Nifi及其他工具取而代之,我没指望会大量使用Oozie。
MapReduce:Hadoop的这个处理核心在渐行渐远。DAG算法可以更有效地利用资源。Spark使用更好的API在内存中处理数据。由于内存变得越来越便宜,向云计算迁移的步伐加快,支持继续使用MapReduce的成本原因渐渐站不住脚。
Tez:从某种程度上说,Tez是条没人走的路――或者说是分布式计算这棵进化树上早已过时的分支。与Spark一样,它也是一种DAG算法,不过有个开发人员称之为是汇编语言。
与MapReduce一样,使用Tez的成本原因(磁盘与内存)渐渐站不住脚。继续使用它的主要原因是:面向一些流行Hadoop工具的Spark 绑定不太成熟,或者根本就没有准备好。然而,由于Hortonworks加入了向Spark靠拢的阵营,Tez到年底之前似乎不太可能有一席之地。要是你现在不知道Tez,也不用心烦。
现在是大好时机
Hadoop/Spark领域在不断变化。尽管存在一些碎片化现象,不过随着围绕Spark的生态圈日益稳固,核心会变得稳定得多。
下一大增长点将来自治理和技术的应用,以及让云计算化(cloudification)和容器化更容易管理、更简单的工具。这类进步给错过第一波热潮的厂商带来了大好机会。
如果你还没有采用大数据技术,眼下正是趁机进入的大好时机。发展太快了,啥时行动永远不会太晚。同时,主攻遗留MPP立方数据分析平台的厂商应该作好被颠覆的准备。