戴尔Fuild Cache for SAN,在服务器闪存缓存与SAN阵列的集成方面可谓独树一帜。相信一些读者对该技术已经不陌生,除了那500万IOPS的Demo之外,网上也能找到相关资料和分析的文章,如:《性能与ILM的平衡:服务器闪存缓存的思考》。今天我们想回顾一下Fuild Cache for SAN的独特技术优势,以及在流动缓存背后的功臣——RDMA高速低延时网络。
如果说PCIe/ NVMe打通了主机内部CPU与闪存之间通道的话,那么RDMA over InfiniBand或者RoCE则能够有效改善跨节点的闪存访问性能。
Fuild Cache for SAN的独特优势
1 SAN整合尽管有多家厂商都宣称他们的服务器闪存缓存软件,可以配合后端SAN存储使用,但许多也标明了只是单机读缓存。除了戴尔Fuild Cache for SAN之外,具备分布式缓存一致性和RAC支持的寥寥无几。
这里要强调一下,早期的Server Flash Cache软件通常不支持像Oracle RAC这样的双活(Active/Active)集群访问,简单说就是当一台服务器向后端共享存储中写入数据时会锁定整个LUN。而Oracle RAC需要的是传统SCSI-3规范的细粒度锁机制,一个LUN上的不同LBA允许同时接受来自多个服务器的写操作。
分布式缓存一致性解决的就是协同,或者说数据一致性。如果由一台服务器改写了后端LUN内的数据,在另一台服务器上Flash Cache内也有对应的数据块,需要做过期处理,也就是说要维护一个同步的缓存元数据索引。
Server Cache Pool——戴尔将Fuild Cache for SAN称为缓存池,是因为一台服务器闪存缓存中的数据可以供集群中别的服务器加速存储访问,而后者并不是必须要作为这个闪存缓存池的贡献者。
2 Server Cache Pool戴尔将Fuild Cache for SAN称为缓存池,是因为一台服务器闪存缓存中的数据可以供集群中别的服务器加速存储访问,而后者并不是必须要作为这个闪存缓存池的贡献者。
3 异构服务器访问既然Fuild Cache for SAN网络中不是每个服务器节点都需要配置闪存缓存(最少2个贡献节点+1个仲裁节点),那么也就允许第三方服务器加入集群。
4 Write-back(写回)缓存支持尽管一家戴尔友商曾表示将支持write back写缓存,但直到去年我们也没有看到这一功能的发布。
闪存一旦用于读&写缓存,和自动分层存储已经有相似之处。只是数据是否最终要持久化到后端的问题,因为这时闪存中的待写入数据必须保证可靠性和高可用性。
这就涉及到本文的重点——RDMA网络。为了缓存池中的全局访问,还有把每台服务器的闪存写缓存镜像到其它节点以实现冗余,最好能有一个低延迟的专用高速网络。
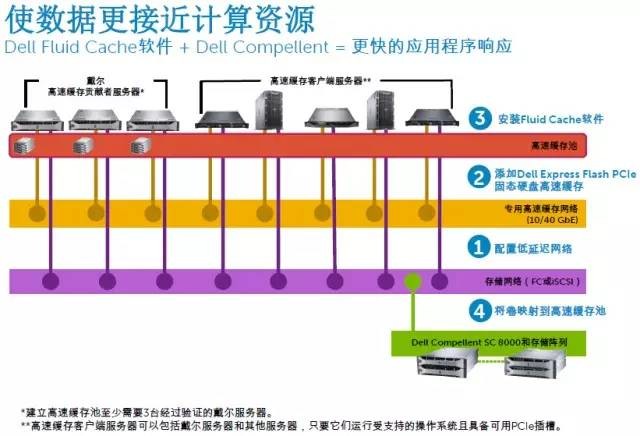
5 低延时专用互连网络戴尔Fuild Cache for SAN需要配置专用的40Gb或者10Gb RoCE(RDMA over Coverge Ethernet)缓存通信网络,RoCE在相同速率下的性能/延时表现可以媲美InfiniBand。我们看到部分多控制器的高端存储阵列,其节点间就是用IB网络互连,而戴尔Fuild Cache for SAN的闪存缓存池更加靠近服务器,取得更好的性能也在情理当中。
延时大跳水:绕开TCP/IP协议栈开销
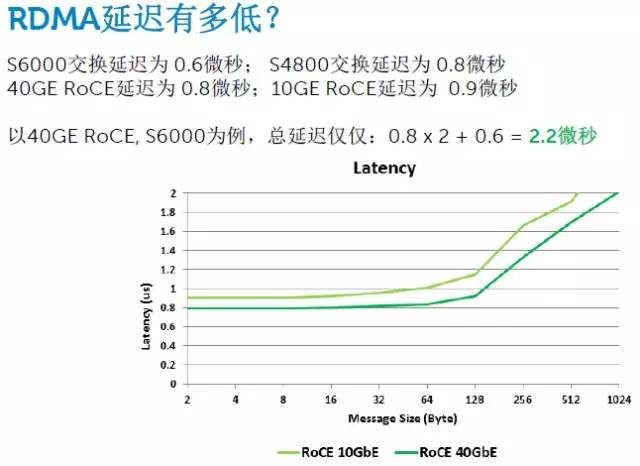
如上图,我们看到40GbE和10GbE交换网络的物理延迟(当然不包括TCP/IP)分别只有0.6和0.8微秒,RoCE(RDMA over Coverge Ethernet)的延迟也不到1微秒。这里我理解的应该是主机到交换机。
直行何必绕弯——看RDMA如何工作
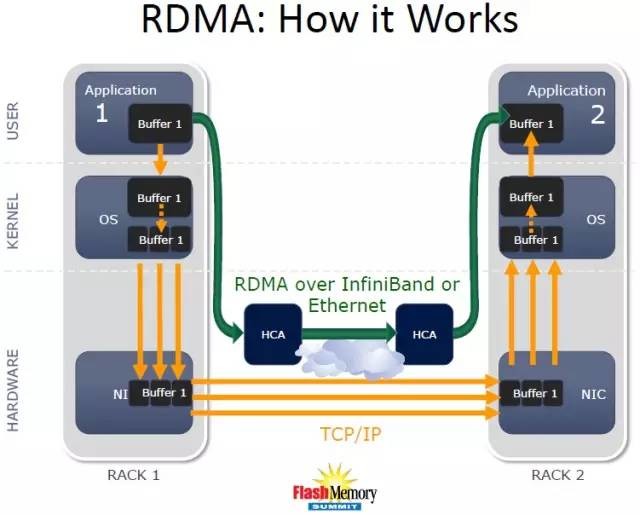
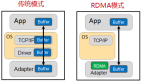
来自去年闪存峰会资料的这张图,简明的解释了RDMA over IB和RoCE的好处:从User层(用户态)绕过Kernel层(内核态),直接走InfiniBand HCA或者RoCE网卡从网络发送数据;即从应用的buffer缓冲,绕过了OS的接收和发送buffer,甚至网卡上都可以不再做buffer。当然,我们前面提到的另外一点——绕开TCP/IP也是改善性能的重要因素。
从RNA内存虚拟化到Fuild Cache for SAN
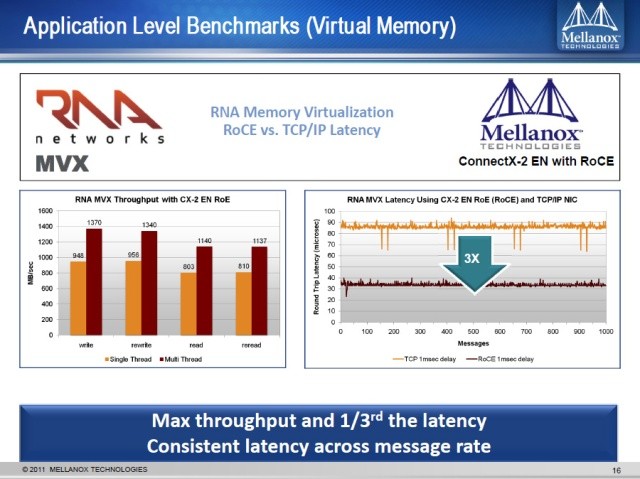
上图来自Mellanox 2011年的资料,Mellanox是最大的InfiniBand网络设备制造商,也是RoCE的主要发起者。戴尔与Mellanox在高性能计算和存储方面有着紧密的合作。
RNA这家公司已于同年被戴尔收购,上面的对比数字是他们之前的MVX内存虚拟化产品在RoCE和TCP/IP网络下的延时对比。注意这里是应用级Benchmark和Round Trip延时,当时使用的ConnectX-2是10Gb万兆网卡。从测试结果来看,RoCE延时只有TCP/IP网络的1/3多一点。
值得一提的是,Fuild Cache for SAN正是RNA的技术融入戴尔之后推出的产品,将RoCE高速网络与PowerEdge服务器上ExpressFlash NVMe PCIe SSD的优势结合起来,相得益彰。