作者介绍
萧田国,触控科技运维总监,高效运维技术社区创始人,互联网专栏《高效运维最佳实践》作者。
“高效运维”和老王(王津银)提倡的“精益运维”、智锦提倡的”白盒运维”并称为运维三大流派。
引言
2015年,业界已经连续出现了几起大的故障。究其根本原因,都是不应该的人为事故。本文从这些大故障说起,主要谈及运维管理相关的一些话题。本文的主要内容包括:
一、不太平的互联网
二、为什么这么多人为事故?
1.为什么运维更容易发生事故?
2.规范这么全,为什么还有事故?
3.都自动化了,为什么还有事故?
4.灰度这么好,为什么还有事故?
三、怎么规避人为事故?
1.选择合适的人
2.培养安全意识
3.让专业变成一种习惯
好吧!我们正式开始。
一、不太平的互联网
近期获悉的一些大故障,不仅来自于携程、阿里云,还有一些影响范围不是很大,但同样非常不应该的人为事故。
901阿里云故障
阿里云称因云盾升级触发bug,导致部分服务器的少量文件被系统误隔离。其已第一时间启动系统回滚,被误隔离的文件正在陆续恢复。

部分阿里云用户表示很受伤。
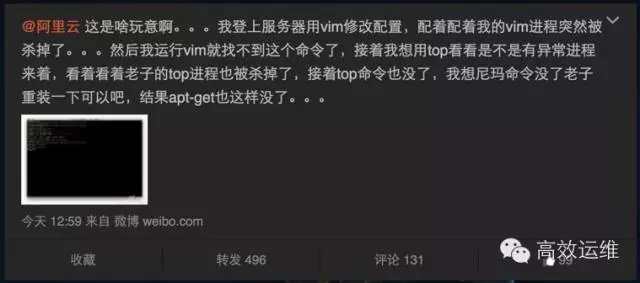
很多微信群朋友纷纷表示也已中招。从波及面及技术层分析来看(详见下文),应该是人为事故为主。
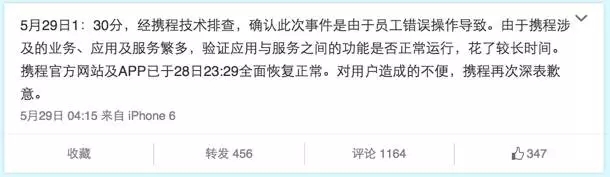
528携程故障
5月底的这次携程故障,在17小时后才恢复业务。官方更是直言为“员工错误操作导致”。
其他“令人发指”的故障
包括但不限于:
1.某公司技术人员大白天的给公司计费数据库服务器更换电源…
2.某银行总行大型机,关键线路接反了…
3.某银行关键交易系统,更新版本时SQL 脚本update 语句没写where 条件,然后所有网点信息都被重置…
根据笔者十多年的互联网从业经验,重大故障,究其根源,至少60%都是低级人为事故。真正因为复杂系统问题导致的严重故障,非常之少。
二、为什么这么多人为事故?
互联网发展至今,还没脱离草莽时代。技术上,从最开始的小米加步枪,到现在逐渐自助化、半自动化,或者利用开源产品修修补补形成自己的系统。
如果说技术上的发展尚可陈词、有些亮点,那么对人的管理和重视程度,就更加落后得太多。
可以佐证的是,微信技术社区里头,讨论技术热点的文章非常之受追捧;但技术管理类的文章,往往非常被冷落。
究其原因,还是在于广大互联网技术人员的“手艺人情结”。从我所在的运维行业来看,尤为突出:
大家都是从Linux、Shell 开始学起,非常享受那种敲几行命令一回车,自动部署多台服务器的快感及成就感。并误以为这就是自己的全部。
技术人员梦想着身怀“绝技”,对Linux系统的某些压箱底活儿或对某项编程技术的独门秘籍,自此笑傲人生,并“不为五斗米折腰”,如认为公司或领导有让自己不爽的地方,即刻”潇洒”遁去。
虽然,这往往验证了一句话“最有才能的人,往往是最无效的”。
技术人员不愿受束缚,更多非常相信自己,觉得我的技术杠杠的。为什么需要别人来检查我的工作?我就是完美。
技术负责人往往工作年龄更长,可能经历过更野蛮生长的时代。
而且很多人潜意识地认为,技术可以解决一切问题,但问题是:
当系统越来越大、自动化和智能化程度越来越高,开飞机的人,水平跟不上,怎么办?
机器再强大,也需要人来操作。你说是不?
1.为什么运维更容易发生事故?
其实相比运维,开发人员还是幸福的。开发更多关注功能、怎么快速交付项目需求即可。程序有Bug?还好啦!后面还有测试在兜底。甚至,Bug 多些也无妨,还能算做测试的绩效。
在这个时候,开发是操作人,测试实际上是检查人,两个岗位互补:
这就是为什么飞机驾驶舱会有两名飞行员的原因,即使副驾驶员看上去无所事事的样子。但,关键时候可是能救命的。
运维就没这么幸运了。运维往往苦逼地冲在第一线,手上掌握着的都是生产环境。而且一般情况下,问责自负,基本上没有谁来检查运维的工作。也少有人意识到这是个严重问题。
2.规范这么全,为什么还有事故?
规范是用来“制约”人的,技术是用来“简化”人的。But,系统再智能也得人来操作,不是么?
对于人本身,我们究竟做了哪些事情呢?这是值得扪心自问的。
规范再多,人也可以束之高阁。所以管理者一定不能觉得规范制度完善了,就已万事大吉。恰恰相反,放松警惕,放松对人的管理,放松贯彻执行,更大的悲剧可能将要来临。
规范制度不是技术管理的全部,规范可以理解为最低标准,用来杜绝不专业的人去会犯毁灭性错误。
规范更多是“术”,而不是“道”。虽然规范想体现“道”,但毕竟,“指向月亮的手不是月亮”。
重视选人、重视培养人的专业意识,才是王道。
3.都自动化了,为什么还有事故?
近期这几起严重故障定义为人为事故,我想应该没有多少人反对。
自动化可以减少人员例行的、重复的登录服务器的操作,从而减少人为事故的发生。那么这又是闹哪样呢?
其实刚好相反,人为事故因为运维自动化平台的出现,其恶劣影响更是被无限放大。
之前小米加步枪的时代,大家都登录服务器进行操作,千百台服务器各自为政,想一次性搞瘫整个系统,还真的很难。
运维自动化平台的出现,很好的“解决”了这个问题。毕竟,平台再智能,也需要人来操作。而过分依赖平台,反而削弱对人员专业性的培养。
人的关系没协调好,问题的根源就没解决。压死我们的往往是最后一根稻草。
4.灰度这么好,为什么还有事故?
有人会说了,我们公司灰度发布非常完善,理应能控制各种事故发生。即使有,影响范围也应该非常之小。
这其实有两个问题。一则有了灰度发布,就可以忽略测试环境了么?如果模拟环境并不足够仿真,或没有在模拟环境充分测试过、直接在生产系统上进行灰度,这个也是非常值得商榷的:
一个朋友说,电信内部做运营,动用了九个机柜100%模拟生产环境,专门做测试。包括网络设备版本,也都充分的稳定性测试。
可能根本原因在于,互联网行业草根出身,长期野蛮生长,从乱到治,习惯试错和快速迭代,因此容易乱象丛生。而电信、银行这些行业,这些从一开始就视安全为命脉,循规蹈矩,谨小慎微。
还有,重大事故发生时,灰度范围内的用户,对他们而言,总归是无妄之灾。凭什么他们就应该蒙受此等“待遇”呢?他们何罪之有?
他们就理应是”小白鼠“么?
二则灰度策略,是否合适?版本发布平台往往汇聚众人智慧结晶设计架构而成,但可能没有定义具体的灰度策略(这不属于技术范围,而是业务范围)。
也就是说,一次更新100台服务器,还是一次更新10000台服务器,是可以被操作人员手工指定的。
最怕的就是,工具做得很流弊,使用者综合能力很一般。
使用者如果图个省事,所谓的灰度发布,一次性的更新成千上万台服务器,那么工具就不仅没有产生效率,反而变成了帮凶(就像刀磨快了,反而变成杀人利器)。
究其本质而言,灰度其实就是一种制度和意识。是希望通过灰度,唤醒人的安全意识。如果操作人员,不能觉悟到这一点,就是死路一条。
三、怎么规避人为事故?
在生产系统上更新版本(特别是如果没有同等模拟环境的话),就像在高速公路上换轮胎,各中危险,不一而足,特别是服务了成千上万台物理机的大系统而言。
人为事故的出现往往不是个例,是长期积累的结果,单个人为事故往往也只是呈现了问题的冰山一角而已。人为事故,是必然而非偶然。
想要有机会彻底的解决人为事故,建议从如下几方面着手。
1.选择合适的人
选好人,往往能做到事半功倍,反之亦然。
管理学的重要原则之一是发挥人的优势,尽量不要尝试着去改变一个人。特别是对于一线生产系统的操作岗位(其实非常重要)而言,找到合适的人,比什么都重要。
运维的首要工作职责是稳定性。因此需要找性格老实、谨小慎微的人来做更加合适。性格毛糙,甚至容易“幻听”的人,明显不合适,毕竟,“常在河边走,哪能不湿鞋”。
为什么非得要让二把刀来开飞机呢?
德才兼备是正途。这里所谓的才就是技术,德是人的德行、行为和意识。道和德是相通的,运维人员的意识增强了,综合能力提高了,规范了,是可以避免一些问题的。
这里顺序很重要,直接从规范切入,往往是失败的开始。需要首先提高意识水平,然后顺势而为。而不是生猛切入。
2.培养安全意识
“对运维操作要有敬畏之心”。这句话应该作为警世恒言,挂在每一个运维人员的心头。
脑子里牢记安全意识,比死记硬背规章制度更重要(当然,首先需要有规章制度)。
运维制度及规范体系的最大意义在于,控制死角可能的影响。每一次事故,都是一个盲点、一个死角又被发现的过程。运维最难之处在于,不可能做到没死角。
规范制度肯定落后于问题。为了规范而规范不是目的,根据诉求控制风险的规范,才是有意义的。
诚然,“安全没有捷径,该踩的雷都会踩到。”但这不是借口,不是免死金牌。同理,用技术来保障技术,也是不可取的。
让每一个运维人员脑海里都紧绷着安全这根弦,比什么都重要。毕竟,死角永远都存在。只能用未知来解决已知,而不是反之。
3.让专业变成一种习惯
先哲亚里士多德曾说:“人的行为总是一再重复。因此,卓越不是单一的举动,而是习惯。”
单次的刺激无法形成习惯,单次过猛的刺激,只会形成恐惧,变得畏手畏脚。
专业是否变成一种习惯,往往更多取决于管理者。因为管理者更能分清楚,哪些是重要紧急,哪些是不重要不紧急。专业首先应该是管理者的一种习惯,然后时时传递不松懈。
管理者应该选对人,然后对于有重大操作权限的人员,经常性的温习各类故障、事故,采取各种办法,让员工时刻具备安全意识,真正认识到责任重大。
“警钟常鸣”,各种震撼人心的模拟演练、演习和培训,也必不可少。
需要树立检查人机制,建立一个好的团队工作习惯,“结对运维”:
没有检查岗,单枪匹马做事情,平时还好,在情况复杂时,个人情绪波动和精神压力都可能非常大,容易错误决策,或使出“昏招”。
另外补充说下:对于公有云而言,如果参与云保险,这对于终端用户而言也是幸事。毕竟云厂商的赔偿,即使100倍又能多少呢?业务的损失,如果由第三方保险公司来做些承当,应该更好。
路漫漫其修远兮,吾将上下而求索。谨以此句,和天下运维同仁共勉。一起加油。
如何一起愉快地发展
“高效运维”公众号(如下二维码)值得您的关注,作为高效运维系列微信群(国内领先的运维垂直社区)的唯一官方公众号,每周发表多篇干货满满的 原创好文:来自于系列群的讨论精华、运维讲坛精彩分享及群友原创等。“高效运维”也是互联网专栏《高效运维最佳实践》及运维2.0官方公众号。
重要提示:除非事先获得授权,请在本公众号发布2天后,才能转载本文。尊重知识,请必须全文转载,并包括本行及如下二维码。