












15年前,人们视其为里程碑式但高不可攀的成就;10年前,这是一个有趣但是昂贵的研究工具;现在,日渐低廉的价格,迅猛提升的精确度以及正在稳定进步基础科学体系将基因组测序带入常规临床护理的实践前沿。
越来越多的机构正在开展基因组研究以鉴别出导致稀有疾病的基因突变。“我们正在寻找的基因突变的发生概率正在提高”,Russ Altman说道,他是斯坦福医药学院的一名生物信息教授。“在一些医疗中心,百分之50的案例都是我们研究的这些病种”。
越来越多的机构正在开展基因组研究以鉴别出导致稀有疾病的基因突变。“我们正在寻找的“基因突变”,它发生概率正在提高”,Russ Altman说道,他是斯坦福医药学院的一名生物信息教授。“在一些医疗中心,百分之50的案例都是我们研究的这些病种”。基因突变可以揭露诱发这些疾病 的原因以及肿瘤治疗的漏洞,以及提供合理的关于一个病人个体是否会对某种药品的反应程度-也就是我们说的遗传药理学。
仅仅需要1000美元的基因组测序,这个价格点,是科学家们设想的能够应用到实践中的价格阈值,现如今已经达到。 “我们的性价比在科学史上是绝无仅有的,在此前几年几乎只有6个订单。”Paul Flicek说道,他是一位计算基因组学的专家,现供职于英国剑桥郡的欧洲分子生物学实验室欧洲生物信息学研究所。如今San Diego等人领导的HiSeq X Ten基因测序系统,每年可以为超过18000人提供基因测序服务。
生物医药研究社区正在竭尽全力探索基因组分析的临床能力。就在2014年,英国开展了“100,000基因组项目”,同时美国和中国已经有公开计划——致力于分析超过100万个个体的基因组。
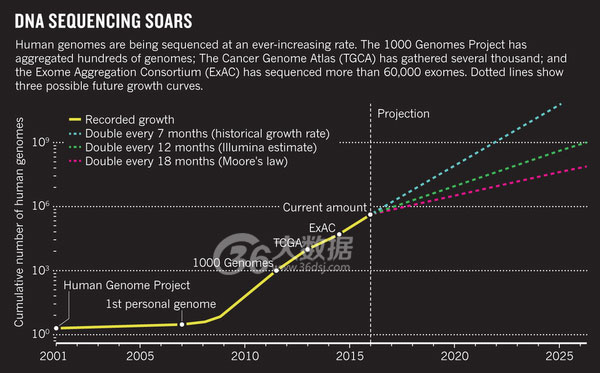
Stephens, Z. D. et al. PLoS Biol.13, e1002195 (2015)/CC by 4.0 http://creativecommons.org/licenses/by/4.0
尽管许多项目都关注于该领域中不同的部分,但它们都不约而同地将眼光放到了“大数据”上。例如,位于宾夕法尼亚州丹维尔市的Geisinger健康 系统和位于纽约的Regeneron制药生物技术公司的一个合作项目,就致力于研究超过250,000个个体的基因序列。同时,世界范围上的许多医院和医 疗服务中心正在分析患有癌症或者稀有疾病的患者的基因组
一些研究者提出了这样的担忧:这样的数据洪流,其分析以及对于存储空间的极大要求,会对计算机能力造成极大挑战。一篇文章指出,基因组分析生成的大 数据,会让诸如YouTube这样的数据巨兽都自认侏儒。许多人也担忧目前的大数据并没有足够分析能力去提供临床知识。“我不知道百万级别的基因组数目是 否足够临床应用,但是我清晰地知道,我们得到的数据越多,效果越好。”Marc Williams说道,他是Geisinger生物制药公司的领导者。
基因突变的意义
现如今的临床基因组检测着力关注于鉴别个体的单核苷酸变异(基因中的可以造成基因破坏的最小单位)。相对于检测全部基因组,许多研究中心着力于外显 子组-基因组中负责蛋白质编译的子集。这种分析思路将需要分析的数据量降低到了原来的百分之一,但是平均下来,外显子组还是包含了超过13,000个单核 苷酸,其中,大约2%被认为能够影响蛋白质的编码组合,因此找到导致某种疾病的单核苷酸变异仍然是一个巨大挑战。
几十年来,生物医学研究人员尽职尽责地沉浸在他们对于单核苷酸变异的新发现,这些发现大多来自公共数据库,例如人类基因突变数据库,由医学遗传研究 所的英国卡迪夫大学运营,又例如dbSNP数据库,其由美国国家生物技术中心维护。然而,这些突变的影响往往是从细胞培养物或动物模型中,或者理论预测确 定的,对于临床诊断工具来说,它未能提供足够的指导。 “在许多情况下,协会分别与证据相对较低的水平制造的,”威廉姆斯说。
几十年来,生物医药研究者们尽职尽责地投入在对于公共资源数据中的单核苷酸变异的发掘中,这些公共资源包括Human Gene Mutation Database(人类基因突变数据库),现在是卡蒂夫大学医学遗传学研究所在运营着,又例如dbSNP数据库,由美国国家生物技术信息中心负责其维护工 作。然而,这些突变带来的生物学影响,通常是由细胞培养物或者动物模型所决定的,甚至是理论预测的,这些指导是不足以使用在临床应用上的。“在许多案例 中,支持这种关联(疾病与基因突变的关联)的证据仍然不足”。
“You’re shooting yourself in the foot if you’re collecting data you don’t know how to interpret.”
”如果你不知道如何解释你收集而来的数据,那么这无异于用枪指着自己的脚然后按动扳机。“
对于结构性的变异来说,情况将会更加复杂。例如,成块重复或者成块缺失的基因组,相比起单个核苷酸的突变,是更加难以检测的。在完全基因组序列中,每个人 都可能有上百万个基因突变,尽管它们中的大部分都不负责编译蛋白质,但它们多多少少有参与到普通的基因行为中,所以它们仍然可以导致疾病。然而,我们对于 这些基因的特性以及功能,知之甚少。尽管我们感觉到了了解这些突变的紧迫性,但在临床应用上,它不能给我们最好的短期回报。
You’re shooting yourself in the foot if you’re collecting data you don’t know how to interpret,”
如果你不知道如何解释你收集而来的数据,那么这无异于用枪指着自己的脚然后按动扳机。Altman说道。
人们已经做出了一些努力去纠正以上这个问题。由美国国家人类基因组研究所
设立的临床基因组资源,是一个描述“疾病-变异”关系的数据库,它包含了药物对某些变异的病理反应以及支持这种关联的证据。Genomics England(一个组织),运营着“100,000基因组项目”,设立了“临床解释伙伴”,旨在推动这个领域的进步,我们可以看到,医生和研究者会通力 合作来构建健壮的模型以建立疾病与特定基因变异之间的关系。
然而,数量和质量一样重要。能带来巨大影响的基因突变通常是有害的,因此它们会十分稀少以及需要大量的的病理样本以分析。建立有统计意义的“疾病-变异”关联,尤其是对于影响效果比较不明显的这种关联,也需要大量的人类个体数据。
在冰岛,deCODE Genetics(一个组织)调研了超过150,000个个体的家谱以及病理历史记录,结合15,000份全基因组序列,其调研结果已经向人们展示了基于 大规模人类个体的基因组学的力量。这些发现使得deCODE能够推断地区人口级别的疾病风险因素,包括与乳腺癌,糖尿病和阿尔茨海默氏病有关的基因变异。
他们也允许一些往日只能在创造转基因动物上才能做的研究。“我们已经建立了10000名患有功能性缺失的冰岛人的基因数据”。Kari Stefansson说道,他是该公司的首席执行官。“我们正在投入巨大资源以研究某些基因的敲除对这些个体的影响”。
这些工作的成功,很大程度上得益于冰岛人口基因型的同质性,但其他项目需要更为广泛的基因频谱。一些工作例如国际千人基因组计划已经编录了一些世界范围的多样化基因,但绝大部分数据仍然偏向于高加索人群,这使得其对于临床医学用处不大。“因为它们都来自与一个基因组祖先,可以这么说,非洲祖先携带的基因变异比非非洲祖先多。”Isaac Kohane说道,他是位于马萨诸塞州波士顿的哈佛药学院的生物信息学家。“在高加索人种上稀有的基因突变,在非洲人种身上可能是很常见的,而且还可能不会造成任何疾病”。
部分问题源于参考基因组,也就是准绳基因序列,科学家们通过它来确认异常基因,该序列由multinational Genome Reference Consortium维护。其首个版本是由世界各地的多个种族的随机捐赠者拼凑而成,但最新的版本,我们称为GRCh38,结合了更多的关于人种基因多样 性的信息。
置身于云
在人口规模上收集基因组乃至于外显子组将会产生极其巨大的数据量,每年可能高达40PB。尽管如此,原始数据的存储并不是主要的计算问题。“基因组学家只是普通人群中对硬盘容量有更大需求的一群人。”Flicek说道,“我不认为存储会是一个关键的问题”。
人们更为关注的是如此巨量的数据将如何被分析研究。“计算需求和人口数是线性相关的”,Marylyn Ritchie说道,他是宾夕法尼亚州立大学的基因组学家。“但当你加入了更多变量,关注更多的组合可能的时候,其对计算能力的要求就成指数相关。”如果 有相关的临床症状或者额外的基因数据(更多变量),那么分析就会变得尤为困难。处理如此数以千计的个体基因数据可以彻底瘫痪实验室中的统计分析工具。
扩大数据规模需要我们在思路上进行创新,但是我们也没有必要从零开始。“像气象,金融和天文学领域都已经在整合各种数据这条路上走了很 久。”Ritchie说道,“我和Google以及FaceBook的人们交流过,我们的大数据,尽管和他们的大数据有不同之处,但我们应该和他们交流, 找出他们是如何做的,并且将其合适的方法整合到我们的领域中。
不幸的是,许多才华横溢,具有大数据开发经验的程序员都被硅谷企业所吸引。Philip Bourne,现任美国国家卫生研究院的数据科学副主任,他认为,造成这种情况的一部分原因是,对于这么一个公共资源推动的科学项目,人们还缺乏认知上的 提升和重视,从而使得该领域许多软件开发员和数据经营者仍然处于寒冬之中。”例如,这群人中的一部分希望能够成为一名学者,但是他们不能得到教师的地位, 这是不合理的。”
计算机的处理能力是另外一个关键因素。“这不是一个桌面游戏——真正的从业者都精通基于成百上千个CPU以及大内存的大规模并行计算。Kohane 说道,许多分析大规模数据的研究组都正在转向基于云计算的架构,其中数据被放置于一个巨大的数据池中并供给任何一个有需要的计算单元进行分析。
人们渐渐地产生了这种想法:你将你的算法带到数据中去。Tim Hubbard说道,这是Genomics England组织的首席生物信息学家。对于Genomics England组织来说,它们的架构被放置在一个安全的政府设施中,严格控制外部访问。而其他小组则渐渐转向了商用云系统,例如Amazon或者 Google提供的云服务。
隐私保护
原则上,基于云计算的托管服务可以鼓励数据集共享和协作. 但患者的知情同意权以及隐私权利会因为这高度敏感的临床信息而变得棘手和敏感,同时伴随着伦理和法律问题。
在欧盟,具有不同法律条令的成员国更是成为这种合作的阻碍。除此之外,与非欧盟国家的共享还依赖于笨重的体制以建立安全的数据保护,或者是个别组织之间限 制性双边协议的完备性。为了解决这个问题,一个跨国组织——全球基因组学与健康联盟,制定了有关基因组责任分担以及健康方面数据资源的框架,其包括了隐私 权和知情同意权的指导方针,同样也框定了成员责任以及违规行为的法律后果。
技术上的高速发展正在改变基因组学研究。
在数据传输协议上,“在出资人同意的前提下,你可以保存自己的数据以及获取的结果规则页面”。Bartha Knoppers说道,他是蒙特利尔麦克吉尔大学的生物伦理学家,主管联盟监督工作以及伦理工作组。该框架还要求“安全区域”,即在去除个人数据保证了隐 私安全的同时,也保留其数据的可研究能力,在此前提下,允许研究机构获取并分析中央数据仓库的信息数据。“我们还希望把它链接到临床数据和医疗记录,若不 这样做,我们永远也得不到精密医学诊断。
对许多欧洲国家来说,将基因组信息整合为电子健康信息正变得越发重要。“我们的目标是将这个作为标准的国家健康服务”Hubbard说道。英国的 “100000基因组项目”将在这条路上前进,但同时其他国家正在紧追不舍。例如,比利时最近就公布了一项计划,以探索医学基因组学等。
所有国家受益于集中式的,政府运营的健康中心。在美国,情况就比较分散,不同的健康服务中心依赖于不同的健康信息系统,由不同的信息供应商提供,这些数据,往往不是设计来处理复杂的基因组的。而在这方面,美国国立卫生研究院的电子医疗记录和基因组学网络设立了一个标杆。
从数据到诊断
当前,我们收集并维护这些丰富的基因组信息,是为了解释基因突变对于个体生理健康的影响,而这其中,最早实现的是病理学。临床药理学联盟已经将药物 -基因关联(来自PharmGKB数据库)投入实施并用于临床使用。例如,带有某种基因突变的个体将会对特定的抗凝剂产生很差的反应效果,从而导致心脏病 发作的的可能性增加。“问题在于,我们如何让一名忙碌到只有12分钟来诊断一位病人并且用45秒以对症下药的医生,采纳我们这种更加有意义的做法?”
将健康护理与基因发现更好地结合起来,仍然是人类面对的一个问题,完成这个过程需要我们投入更多的时间和精力。从研究的角度看,结合基因型与表现型信息给 我们带来累累硕果。大部分疾病相关基因变异是通过全基因组关联研究而鉴别得来的,在这个研究过程中,大量的患有某种疾病的个体参与了我们的检测,以确定遗 传特征识别。研究人员现在可以从健康记录反向工作,以确定什么临床表现是与给定的基因变异密切相关的。
基因组只是故事的一部分,其他“组”也有作为健康晴雨表的可能性。今年七月,Jun Wang辞去了他BGI主席的工作,创办了一个机构,致力于分析BGI的百万人群计划的基因组信息,其中包括蛋白质组,转录组以及代谢组等等。“我将设立 一个全新的机构,使用人工智能来探索这个领域的大数据。他说道。
来日方长
随着研究人员努力整合来自健康档案、基因组和其他生理数据的临床试验数据,患者本身也可以作出贡献。“当我们专注于病人的日常行为,包括营养,运动,吸烟和饮酒等,没有比这更好的数据了”里奇说道。
可穿戴设备,如智能手机和FitBits,正在收集有关运动与心脏速率数据,而这样的数据量不断攀升,因为收集这种数据不费吹灰之力。
每个患者都可能成为一个大数据生产者。“我们在家里或者公共场所收集的数据将会大大超过我们所积累的临床数据。Kohane说道。”我们正在努力收 集不同数据模式的这些大模块——从基因组到临床医学环境——然后将其链接到具体的病人身上。“随着这些进展具体化,他们可以利用碎片化的计算方式,使得今 日我们的大数据计算就像袖珍计算机问题一样。随着科学家想方设法碎片化数据,病人们将是最终的获益者。
原文标题:Big data: The power of petabytes















