数据库的横向扩展已经成为各个企业用户的基本需求,一方面随着企业前端业务系统的膨胀,后端数据库系统的负载也在不断增长,企业进行纵向扩展技术难度较大,另一方面,数据库系统的关键性不断提高,横向扩展不仅提高处理性能,也极大的提高了数据库系统的容错能力。
目前,数据库横向扩展有多种实现方式,较为主流的是共享存储(Shared Disk)技术,不久前,浪潮发布的K-DB数据库,这款产品就基于共享存储技术,实现了双机高可用(HA)、多机集群(KRAC)等数据库横向扩展。
浪潮K-DB采用基于共享存储(SharedDisk)的双机或多机集群(KRAC)架构。
KRAC具有两大特点:故障转移和负载均衡。一方面,KRAC集群技术提供高可用解决方案,为用户提供统一数据服务的同时提供故障切换与恢复能力(Fail Over集群功能),避免单点故障,减少停机时间,确保系统全年7*24稳定运行。另一方面,后端数据库系统的负荷随着应用系统压力的上升也在不断的增加,集群技术能够实现数据库系统的横向扩展,将数据库的压力平均分配在多台数据库服务器上。
【KRAC演示视频】
http://v.qq.com/boke/page/x/k/1/x0174dycbk1.html
而在介绍这两大特点前,我们先通过下图了解KRAC的体系结构。
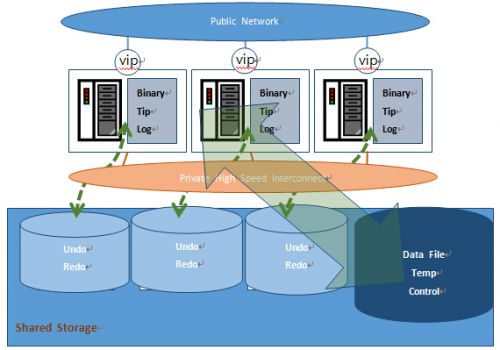
KRAC体系结构
KRAC由多个节点的数据库服务器和共享存储组成。共享存储上主要存放的是数据库必需的文件,包括数据文件、日志文件及控制文件等。数据库服务器上运行着数据库对应的实例,多实例之间通过内网进行数据的传输。KRAC的各个节点可以同时对磁盘进行读写,实现了多读多写的真正集群技术。
KRAC具有两大特点:故障转移和负载均衡。
特点一:故障转移
KRAC数据库可以对数据库系统中出现的任何单点故障节点的session 转移到其他正常的节点上,如磁盘、网络、服务器等,保障应用系统的不间断,最大程度的减少用户的损失。
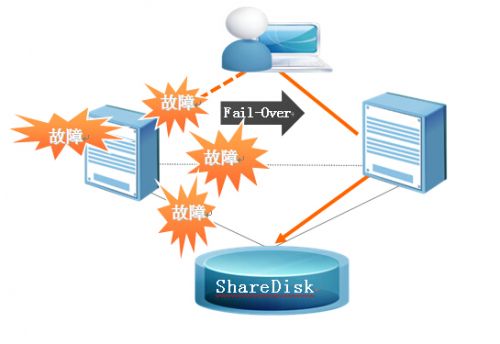
KRAC故障转移
特点二:负载均衡
KRAC会将所有的用户session平均分配到各个节点上,集群中的各个节点均能对磁盘进行读写,达到应用系统的线性扩展,从整体上提高数据库的吞吐量。
数据库各个节点的实例之间通过高速的内网传送数据,避免了节点间访问数据而产生的不必要的IO,而影响到性能。而在KRAC集群中,由于有多个节点都具有block buffer,这就需要节点间的blockbuffer可以互相传输访问,才能达到一致性的状态。
要具备以上2大特点,就不得不提内存融合技术,他是实现KRAC功能的核心。
KRAC核心技术:内存融合
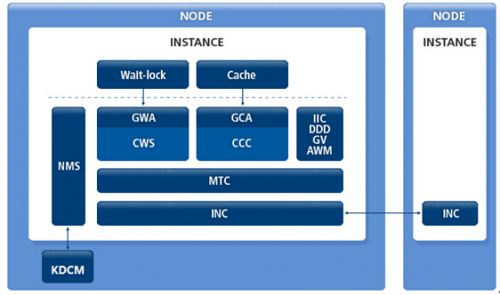
KRAC集群内部组件
KRAC的集群中由CCC(Cluster CacheControl)模块和GCA(Global CacheAdapter)模块实现集群间数据库的融合。传输的数据块类型根据不同场景的需要而不一样,主要包括CR block、Global dirty block、current block。节点间数据传输的功能由模块INC(Inter-NodeCommunication)服务。在节点间请求的block buffer由 CCC 和CGA 构造完毕后,INC 负责将对应的数据块传输到目的节点。
KRAC内存融合主要体现在4大核心技术上:锁机制、角色、PIBLOCK和GLOBAL LOCK DIRETROY。
下面,我们将为大家详细介绍这4个核心技术点的运行机制。
锁机制
在数据库中,对于数据块的block buffer的并发读写使用锁机制进行保护。每一个数据块的锁包括三种模式,分别为NULL、SHARED和EXCLUSIVE 。三种模式的兼容列表如下:

当某一个用户持有block buffer的锁时,如果其他用户以兼容模式的锁方式进行访问,那么这2个用户可以同时访问该数据块。
而一旦2个用户以不兼容方式访问同一个数据块时,后面的用户必须等到前一用户释放锁之后才能开始操作。这种解决方案是单实例K-DB数据库的解决方案。而在KRAC中,K-DB数据库在此基础上,增加了额外了管理方式-角色和Past image Block数据块。
角色
K-DB 对于数据块的分配了2种角色,分别是LOCAL 和GLOBAL,当数据blockbuffer只在一个节点与磁盘上的数据不一样(脏数据),该block buffer的角色为LOCAL状态。当在多个节点上存在“脏数据”时,block buffer的角色为GLOBAL.
PI BLOCK
如果一个block 在某一个节点中被修改后,然后该block传输到了其他节点,那么本节点存储的block块为PI(Past Image)block。PI BLOCK 块在以下2个方面具有一定的优化作用:
- 提升CR 块构建的速度。当本地构建的CR块的SCN 小于PI BLOCK 的SCN时,无需从其他节点传输最新的current数据库,直接在本地使用PI BLOCK可以构造。
- 节点宕机后,提升系统恢复的性能。当某一个节点宕机后,整个集群会暂时停止服务,进行内部恢复。恢复的原理就是将宕掉节点的redo日志在其他节点进行恢复。在恢复时,对于redo日志中小于PI BLOCK的SCN无需重做,从大于等于PI BLOCK的SCN处开始恢复,从整体上减少了恢复的工作量。
GLOBAL LOCKDIRETROY
在K-DB数据库中,所有各个节点对于bufferblock的锁信息,都会记录在GlobalLock Directory(GLD)。各个节点在share pool 内存中分配出一部分内存,共同组成整个的GLD。那么一个节点会记录哪一个数据块的锁和角色的相关信息呢?
在这里,KRAC又提出了一个新的机制,就是master机制。
所有的buffer block在当前的正在运行状态的集群中,只会对应到一个master节点,该master节点会记录相对应的buffer block在各个节点中锁状态和角色的相关信息。任何节点在访问某一个buffer block时,都需要向他的master节点进行申请。Master节点在收到buffer block访问的请求后,会确定该buffer block块的当前位置,然后将该buffer block块传送给请求用户。所有的master中的信息,共同组成了GLR(Global Lock Directory)。
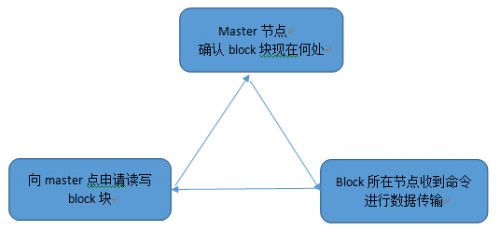
数据块访问流程
为了便于大家更直观理解内存融合,下面通过三个场景举例说明:
场景示例——内存融合
测试参数说明:测试Block 的master 节点是C。Master节点中关于bufferblock一共记录了4个参数,第一个代表的锁模式,如S(Shared),E(Exclusive),N(Null)。第二个参数是定义的是角色,如L(Local),G(Global)。第三个参数定义的是是否为PI, 0代表否,1代表是。第四个参数是该锁对应的instance 节点。
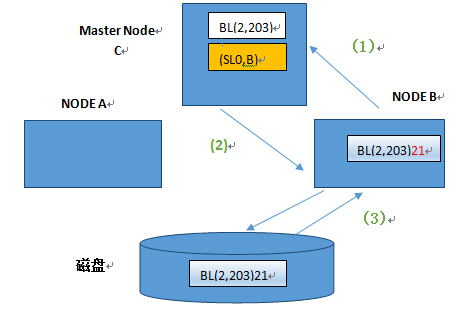
场景一节点B读取磁盘中的BLOCK块
(1)B节点向master C节点申请读取block(2,203),BLOCK 中的数据为21
(2)主节点master C 向B节点赋予block(2,203)的 local 角色shared 模式lock
(3)B节点从磁盘读取block块(2,203)
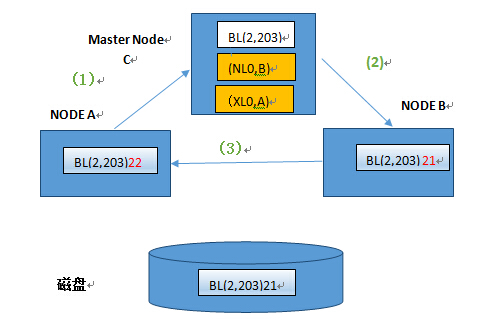
场景二节点A更新节点B中缓存的buffer block
(1) A节点向Master Node C申请写BL(2,203),将21修改为22.
(2) Master节发现B节点以Shared 模式持有BL(2,203).master主节点要求B节点将当前的锁由Shared降为Null模式。
(3) 节点B将本地的锁降为Null模式后,将BL(2,203)发送给A节点。A节点获取local 角色的exclusive 模式的锁,修改BL(2,2003)中的数据为22.
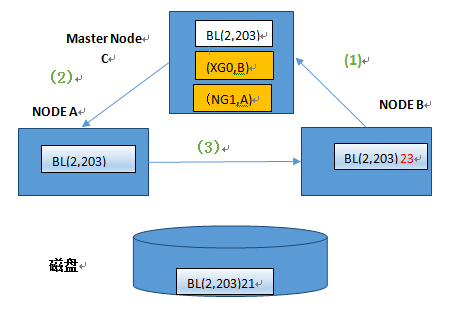
场景三B节点再次更新同一个Block
- B节点向Master 申请X锁,写BlockBL(2,203).将数据修改为23
- Master 节点发现最新版本的数据块在A节点上,并且A 以X锁占有该数据块。Master节点要求A节点的锁降为NULL模式,同时由于此后2个节点中都存在与磁盘中的数据不一致的数据,A节点的角色升级为GLOBAL,A中当前的数据库记为PI块。
- A节点锁降级后,将数据块BL(2,203)传送到B 节点,节点B将数据修改为23.
好了,通过上文介绍,想必大家对浪潮K-DB数据库的KRAC功能和运行原理有了全面认识。
总结来讲,浪潮K-DB数据库是除了Oracle以外,第二个能够实现共享存储的集群技术的产品,采用KRAC多机集群架构,具有故障自动转移、高伸缩能力和自动负载均衡特性,保障系统可用性的同时,大幅提升可用性和性能,还能实现系统性能平滑升级且接近线性的扩展。