网络的转发是通信的基本功能,其完成信息在网络中传递,实现有序的数据交换。通过SDN控制器的集中控制,可以轻松实现基础的转发算法有二层MAC学习转发和基于跳数的最短路径算法。然而,网络跳数并不是决定路径优劣的唯一状态。除了跳数以外,还有带宽,时延等标准。本文将介绍如何通过SDN控制器Ryu开发基于流量的最短路径转发应用。
Forwarding Algorithm
目前基于流量的路由算法基本的解决思路有两种:
(1) 首先基于跳数计算***K条路径,然后在这些路径中选择可用带宽***的路径。
(2) 首先基于跳数计算***路径,归一化路径的评价分数,然后基于流量计算***路径,归一化基于带宽的评价;设置跳数和带宽的权重,对基于跳数和带宽的评分求其加权总和;按照加权求和值降序排序,取前K条作为***评价路径。
本文以***种算法为例,介绍基于网络流量的最短路径转发应用开发。第二种算法基于前者的基础修改即可完成。
Network Awareness
首先我们需要编写一个网络感知应用,用于发现网络的资源,包括节点,链路,终端主机等。并根据拓扑信息计算基于条数的最短路径。开发此应用基本步骤如下:
创建继承app_manager.RyuApp的应用network_awareness
从topology.switches获取拓扑信息,包括交换机节点信息,链路信息
使用Networkx 创建拓扑图的对象,用于存储网络拓扑
使用Networkx的函数all_simple_paths(G, source, target, cutoff=None)计算K条***路径并存储,该函数实现了Yen's algorithm
示例代码可由muzixing/ryu/network_awareness获取。
Note that: 以上的示例代码中,拓扑信息的存储并没有使用networkx,所以读者需要独立完成基于networkx的存储和算法调用部分。
Network Monitor
第二个应用是网络流量监控应用。网络流量监控应用完成网络流量的实时监控,计算出实时的流量统计数据。基于本应用的数据,可以完成转发算法的第二部分内容。示例代码可由muzixing/ryu/network_monitor获取。
为了让其他模块获取到***的流量信息,可在Ryu中自定义事件,具体教程请查看《基于Ryu打造自定义控制器》的自定义事件部分内容。不定义事件的情况下,需要将此模块作为新模块的CONTEXT。详情可阅读《Ryu:模块间通信机制分析》的相关内容。
Forwarding Application
基于以上两个模块的数据,转发应用模块需要完成如下几个步骤,从而完成基于流量的***路径转发。
获取network awareness和network monitor的数据
将network monitor的数据整合到networkx存储的网络拓扑信息中
比较最短K条路径中各路径的剩余带宽,选择***路径,剩余路径为备份路径和逃生路径
基于路径信息,安装流表项
整合流量信息代码示例代码如下, 其中,link2port为链路信息,bw_dict为network monitor模块的流量数据。
- def create_bw_graph(self, graph, link2port, bw_dict):
- for link in link2port:
- (src_dpid, dst_dpid) = link
- (src_port, dst_port) = link2port[link]
- if src_dpid in bw_dict and dst_dpid in bw_dict:
- bw_src = bw_dict[src_dpid][src_port]
- bw_dst = bw_dict[dst_dpid][dst_port]
- graph[src_dpid][dst_dpid]['bandwidth'] = min(bw_src, bw_dst)
- else:
- graph[src_dpid][dst_dpid]['bandwidth'] = 0
- return graph
获取最短K条路径函数示例代码如下所示。
- def k_shortest_paths(graph, src, dst):
- path_generator = nx.shortest_simple_paths(graph, source=src,
- target=dst, weight='weight')
- return path_generator
基于流量的***路径比较算法示例代码如下所示:
- def band_width_compare(graph, paths, best_paths):
- capabilities = {}
- MAX_CAPACITY = 100000
- for src in paths:
- for dst in paths[src]:
- if src == dst:
- best_paths[src][src] = [src]
- capabilities.setdefault(src, {src: MAX_CAPACITY})
- capabilities[src][src] = MAX_CAPACITY
- continue
- max_bw_of_paths = 0
- best_path = paths[src][dst][0]
- for path in paths[src][dst]:
- min_bw = MAX_CAPACITY
- min_bw = get_min_bw_of_links(graph, path, min_bw)
- if min_bw > max_bw_of_paths:
- max_bw_of_paths = min_bw
- best_path = path</p>
- best_paths[src][dst] = best_path
- capabilities.setdefault(src, {dst: max_bw_of_paths})
- capabilities[src][dst] = max_bw_of_paths
- return capabilities, best_paths
- def best_paths_by_bw(graph, src=None, topo=None):
- _graph = copy.deepcopy(graph)
- paths = {}
- best_paths = {}
- # find ksp in graph.
- for src in _graph.nodes():
- paths.setdefault(src, {src: [src]})
- best_paths.setdefault(src, {src: [src]})
- for dst in _graph.nodes():
- if src == dst:
- continue
- paths[src].setdefault(dst, [])
- best_paths[src].setdefault(dst, [])
- path_generator = k_shortest_paths(_graph, src, dst)
- <pre><code> k = 2
- for path in path_generator:
- if k <= 0:
- break
- paths[src][dst].append(path)
- k -= 1
- # find best path by comparing bandwidth.
- capabilities, best_paths = band_width_compare(_graph, paths, best_paths)
- return capabilities, best_paths, paths
安装流表项函数示例代码如下:
- def install_flow(datapaths, link2port, access_table, path, flow_info, buffer_id, data):
- ''' path=[dpid1, dpid2, dpid3...]
- flow_info=(eth_type, src_ip, dst_ip, in_port)
- '''
- if path is None or len(path) == 0:
- LOG.info("PATH ERROR")
- return
- in_port = flow_info[3]
- first_dp = datapaths[path[0]]
- out_port = first_dp.ofproto.OFPP_LOCAL
- reverse_flow_info = (flow_info[0], flow_info[2], flow_info[1])
- <pre><code>if len(path) > 2:
- for i in xrange(1, len(path) - 1):
- port = get_link2port(link2port, path[i-1], path[i])
- port_next = get_link2port(link2port, path[i], path[i + 1])
- if port and port_next:
- src_port, dst_port = port[1], port_next[0]
- datapath = datapaths[path[i]]
- send_flow_mod(datapath, flow_info, src_port, dst_port)
- send_flow_mod(datapath, reverse_flow_info, dst_port, src_port)
- if len(path) > 1:
- # the last flow entry: tor -> host
- last_dp = datapaths[path[-1]]
- port_pair = get_link2port(link2port, path[-2], path[-1])
- if port_pair:
- src_port = port_pair[1]
- else:
- return
- dst_port = get_port(flow_info[2], access_table)
- send_flow_mod(last_dp, flow_info, src_port, dst_port)
- send_flow_mod(last_dp, reverse_flow_info, dst_port, src_port)
- # the first flow entry
- port_pair = get_link2port(link2port, path[0], path[1])
- if port_pair:
- out_port = port_pair[0]
- else:
- return
- send_flow_mod(first_dp, flow_info, in_port, out_port)
- send_flow_mod(first_dp, reverse_flow_info, out_port, in_port)
- send_packet_out(first_dp, buffer_id, in_port, out_port, data)
- # ensure the first ping success.
- # send_packet_out(last_dp, buffer_id, src_port, dst_port, data)
- # src and dst on the same datapath
- else:
- out_port = get_port(flow_info[2], access_table)
- send_flow_mod(first_dp, flow_info, in_port, out_port)
- send_flow_mod(first_dp, reverse_flow_info, out_port, in_port)
- send_packet_out(first_dp, buffer_id, in_port, out_port, data)
读者可以基于muzixing/ryu/shortest_route的代码进行修改。该代码是初始版本,质量欠佳,但是可以成功运行。
Note that: 以上的代码均为示例代码,不可直接运行,完整版代码后续将发布。
Implementation and Test
启动network_awareness, network_monitor,和写好的forwarding模块,再启动一个简单拓扑连接到控制器Ryu。拓扑中,h1, h2到h39有两条路径:[1,2,4]和[1,3,4]。每条链路的***带宽为500Mbits/s。然后xterm到h1, h2 和还h39,并在h39之上启动iperf服务端程序。先启动h1上的iperf客户端程序,向h39打流,等一个Monitor模块的周期之后,启动h2的iperf客户端程序,向h39打流。此操作的原因在于需要等待控制器获取流量信息和计算出***路径。测试截图如下图所示。
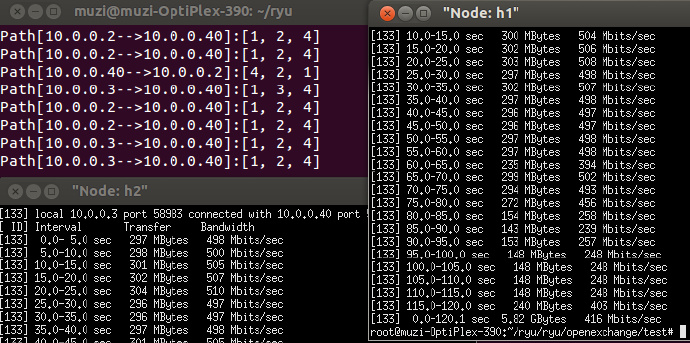
上图左上为控制器的显示,路径选择了[1,2,4]和[1,3,4]。右侧的数据为h1的流量信息,左下为h2的流量信息,可以发现h1和h2各自独占一条路径,都打满了500Mbits。实验成功。
Conclusion
本文介绍了在Ryu控制器中开发基于流量的***转发的流程。不过内容仅仅涉及了解决思路,实际工程代码的发布还需要等待一段时间。文中提到的第二种算法的解决方法与本文举例类似,仅需加上归一化数据,求加权求和评分步骤就可以完成新解决方案的工作。希望本文能给读者带来一些帮助。