嘉宾介绍
董泽润 【高级DBA】
2010—2012年在搜狐畅游,负责游戏Mysql相关的运维。
2012—2015年在赶集网担任DBA,负责整个数据库团队的建设,主要研究 Mysql、Redis、MongoDB 等技术。
2015—至今在一家图片社交公司,专注于 Redis 的运维和自动化研发工作。
引子
这个7月注定不平凡,通过7月连续的Redis故障,细心如你,一定会对技术、公司、同事、职业有了更深刻的认识和反思,先回忆下吧……
本文主要涉及到的故障包括:
1.网卡故障
2.这该死的连接数
3.疑似 Cluster 脑裂?
4.Bgsave传统的典型问题
5.主库重启 Flush 掉从库
好的,敬请欣赏。
Redis Cluster 的迁移之路
我们Redis 部署特点如下:
◆集中部署,N台机器专职负责某个产品线。
◆传统 Twemproxy 方式,额外会有自己定制几套 Twemproxy 。
可以看出来,非常传统的方式。开始只有一个Default集群,PHP 所有功能获取Redis句柄都是这个,流量增长后开始按功能划分。
5月中旬,我来到公司,开始推进 Redis Cluster,争取替换掉 Twemproxy,制定了如下方案:
- Redis Cluster => Smart Proxy => PHP
集群模式能够做到自动扩容,可以把机器当成资源池使用
在 PHP 前面部署基于 Cluster 的 Smart Proxy,这是非常必要的,后文会说到。由于公司有自定义 Redis 和 Twemproxy 版本,所以为了做到无缝迁移,必须使用实时同步工具。
好在有@goroutine Redis-Port,非常感谢原 Codis 作者刘奇大大。
基于Redis-Port,修改代码可以把 Redis 玩出各种花样,如同七巧板一样,只有你想不到的没有他做不到的,可以不夸张的说是 Redis 界的瑞士军刀:
◆实时同步两套集群
◆跨机房同步
◆同步部分指定Key
◆删除指定Key
◆统计Redis内存分布
◆……
迁移方案如下:
1.Redis Master => Redis-Port => Smart Proxy => Redis Cluster
也即,Redis-Port 从原Redis Master 读取数据,再通过Smart Proxy 写入到 Redis Cluster。
2.修改 PHP Config, Gitlab 发布上线,使用新集群配置。
3.停掉老 Twemproxy 集群,完成迁移。
这种迁移方案下,原Redis 无需停业务。
注意:
此方案中的Smart Proxy 是我们自己写的,事实证明很有必要,其作为Redis Cluster 的前端,用来屏蔽Redis Cluster 的复杂性。
方案看似简单,实际使用要慎重。大家都知道 Redis Rdb Bgsave 会使线上卡顿,所以需要在低峰期做,并且轮流 Redis Master 同步,千万不能同时用 Redis Port 做 Sync。
在实施过程中,遇到多种问题,现在简要阐述如下:
问题1:还是网卡故障
想起《东京爱情故事》主题曲,突如其来的爱情,不知该从何说起。
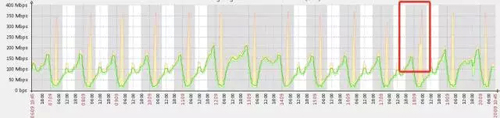
故障的图找不到了,截图一张正常网卡流量图 -_^
千兆网卡在某个周五23:00业务高峰期被打满,导致线上请求失败—如坐针毡的波峰图。
如前文所说,公司集中部署 Redis,此业务是线上 Cache 个人详情页登陆相关的,一共4台机器,每台20实例,无法做到立刻扩容,紧急之下 RD 同学降级,抛掉前端30%的请求。只是恢复后,高峰期已过。
Leader要求周六所有人加班去迁移,But,2点多大家睡了,嗯,就这样睡了ZZZZ~~ 故障暂时解决,但故事依然继续……
周六上午10点,市场运营推送消息,导致人为打造了小高峰,又是如坐针毡的波峰图,服务立马报警,紧急之下立马再次抛掉30%请求。
然后,紧急搭建两套不同功能的 Redis Cluster 集群,采用冷启动的方式,一点点将 Cache 流量打到新集群中,Mysql 几台从库 QPS 一度冲到8K。
针对网卡最后引出两个解决方案:
1.所有Redis 机器做双网卡 Bonding,变成2000Mbps。
2.所有 Redis 产品线散开,混合部署打散。
3.增加网卡流量监控,到达60%报警。
反思:
为什么要睡觉?而不是连夜迁移?做为运维人员,危险意识不够足。
另外:还有一起网卡故障,是应用层 Bug,频繁请求大 Json Key 打满网卡。当时QPS稳定保持在20W左右,千兆网卡被打满。临时解决方案直接干掉这个Key,过后再由 RD 排查。
深度剖析:
◆监控报警不到位,对于创业公司比较常见,发生一起解决一起。
◆针对这类问题,有两个想法:QPS 报警,比如阀值定在2W。还有一个在Proxy上做文章,对 Key 的访问做限速或增加 Key 的屏蔽功能。
◆QPS报警后运维人员排查,可能已经产生影响了,在Proxy层做对性能会有影响。
#p#
问题2:你这该死的连接数
某天8点40左右,还在地铁的我接到电话,Redis 连接报错,貌似几个实例的连接数被打满。这个故障持续时间较长,PHP Redis 扩展直连 Redis Cluster,连接持续增长,直到打满完全连不上。
后来经过排查,确认是扩展 Bug,导致老连接不释放。同时,其他原因也很多:
1.公司使用 Redhat7,所有的应用都是由 systemd 管理,启动没有指定Limit NOFILE,导致 Redis maxclients 限制死在4000左右。
2.PHP Redis 扩展 Bug,连接不释放,线下稳定复现。
这几次连续故障很严重,Leader 直接决定全部回退到老的 Twemproxy 版本,最后回退了两个最重要的产品线。
反思:
1.架构改动没有经过充分测试,线下稳定复现的Bug没有仔细测试直接上线。
2.运维意识不足,对 systemd 了解不够深入,没有对所有配置做严格检查。
3.做为”世界上最好的语言”,偶尔还是有些问题,最好在 Redis 和 PHP 间隔层 Proxy,将后端 Redis 保护在安全的位置。
问题3:疑似 Cluster 脑裂?
脑裂在所谓的分布式系统中很常见,大家也不陌生,做为DBA最怕的就是Mysql keepalived 脑裂,造成主库双写。难道 Redis Cluster中也会有脑裂么?
凌晨5点接到电话,发现应用看到数据不一致,偶尔是无数据,偶尔有数据,很像读到了脏数据。
Mysql 在多个从库上做读负载均衡很常见,Redis Cluster也会么?
登上Redis,Cluster Nodes,Cluster Config,确实发现不同 Redis 实例配置了不同的Cluster Nodes。想起了昨天有对该集群迁移,下掉了几个实例,但是在 PHP 配置端没有推送配置,导致 PHP 可能读到了旧实例数据,马上重新推送一遍配置,问题解决。
反思:
1.有任务配置的变更,一定考虑好所有环境的连动。这也是当前配置无自动发现的弊端。
2.屏蔽细节,在Redis Cluster上层做 Proxy 的重要性再一次得到验证。
3.运维意识不足,严重的人为故障。
问题4:Bgsave传统的典型问题
问题很典型了,非常严重的故障导致Redis OOM(Out of Memory)。
解决方案:
单台机器不同端口轮流 Bgsave,内存不足时先释放 Cache,释放失败拒绝再 Bgsave 并报警。
问题5:主库重启 Flush 掉从库
考虑不周,备份时,只在 Slave 上 Bgsave。主库由于某些原因重启,立马被 systemd 拉起,时间远短于 Cluster 选举时间。
后面就是普通 Redis Master/Slave 之间的故事了,Master 加载空 dump.rdb,replicate 到 Slave,刷掉 Slave数据。
解决方案:
1.备份的同时,将 dump.rdb rsync 到主库 datadir 目录下面一份。
2.根据 Redis 用途,做存储使用的 Redis systemd 去掉 Auto Restart 配置。
其它典型故障/问题
1.应用设计问题,部分 hset 过大,一度超过48W条记录,Redis频繁卡顿感。
2.使用 Redis 做计数器,占用过大内存空间。这个 Redis 官网有解决方案,利用 hash/list 的线性存储,很有效。但是由于 mget 无法改造,我们没采用。
3.混布,导致部份产品线消耗资源过高,影响其它所有实例。
4.机房IDC故障,单个机柜不通,里面所有混布的产品线无法提供请求,数据请求失败。
5.应用端分不清 Cache/Storage,经常可以做成 Cache 的 Key,不加ttl导致无效内存占用。
写在最后
虽然写在最后,但远没有结束,征程才刚刚开始。
每次故障都是一次反思,但我们拒绝活在过去,生活还要继续。
公司重度依赖Redis,除了图片其它所有数据都在Redis中。在稳定为主的前提下,还在向Redis Cluster迁移,其中有几个问题还待解决:
1.Redis 实例级别高可用,机柜级别高可用。
2.混布的资源隔离,看了 hunantv CMGS 的分享,Docker是一个方案。
3.隔离上层语言与 Redis,提供稳定的 Smart Proxy接口。
4.Redis 集群 build 和交付,缺少配置集中管理。
5.很多集群 QPS 并不高,内存浪费严重,急需持久化 Redis 协议存储,基于 ardb/ledisdb 的 sharding 是个方案,自己开发需要同事的信任,这点很重要。
最终公司线上存在两个版本,Twemproxy 开启 auto_reject_host 做 Cache 集群,Redis Cluster + Smart Proxy做存储。
如何一起愉快地发展
“高效运维”公众号(如下二维码)值得您的关注,作为高效运维系列微信群的唯一官方公众号,每周发表多篇干货满满的原创好文:来自于系列群的讨论精华、运维讲坛线上精彩分享及群友原创。“高效运维”也是互联网专栏《高效运维最佳实践》及运维2.0官方公众号。

提示:目前高效运维新群已经建立,欢迎加入。您可添加萧田国个人微信号xiaotianguo8 为好友,进行申请,请备注“申请入群”。
重要提示:除非事先获得授权,请在本公众号发布2天后,才能转载本文。尊重知识,请必须全文转载,并包括本行。