AWS Auto Scaling组是一个优秀的功能,该自动化系统负责管理服务器宕机并为用户自动扩展服务。一个Auto Scaling组连接到弹性负载均衡,则会让确保应用总是启动并处于运行中这件事变得容易。
管理员可以指定一个亚马逊Web服务(AWS)Auto Scaling组使用弹性负载均衡(ELB)健康检查,这将确保该服务在服务器上是运行的–而不只是服务器本身是运行的。这可以快速和自动更换任何行为不正常的服务器,杀掉那些坏的服务器并用好的干净的服务器取代它们。
使用ELB健康检查,而不仅仅是弹性计算云(EC2)健康检查是很重要的。我碰到过这样的问题,服务器仍在运行,但服务器上的服务已经死掉并且无法重新启动。该ELB会从服务器断开,因为它已不再服务请求,但AWS Auto Scaling组并没有替换它,因为服务器仍在运行。最终,所有服务器都有了同样的问题,该服务停止工作。然后,我收到了一个来自Pingdom的警告,通知我说Web服务不工作。AWS Auto Scaling组一直认为所有的服务器都正常,没有检测出实际的Web服务已经死亡并且无法重启。
***对每一个生产服务使用Scaling组,即使他们并不需要真正的自动扩展。我的大部分AWS Auto Scaling组只是简单的描述为,“保持X数量的服务器一直运行。”这意味着,如果出现一个问题然后其中一台服务器宕掉,该服务器会被杀掉并自动替换。这并不意味着我需要根据负载自动增加服务器的数量。但那使得自动化一些简单的DevOps任务如重新启动一台服务器变得更容易。
什么地方出错了?
关于AWS EC2定价的一个需要小小讨论的事实是,用户按照每台服务器运行任意部分小时来支付费用。这意味着,如果一个用户启动服务器,然后在五分钟内杀死它,他仍然要为这完整的一小时买单。这似乎是可接受的,但是如果一个用户杀掉一个服务器然后使用完全相同类型和位置的一个新的服务器来替换它,这个举动会让费用翻倍。
起初,我启动了一个服务器,被收取一台服务器的费用,五分钟后杀掉该服务器,然后换成另一台。但我被收取了2倍服务器运行的费用,直到***台服务器被启动(图1)之后达到一小时。当你将那种计费模式和AWS Auto Scaling组不断杀死和重新启动服务器的错误结合起来,成本就会不断上涨。
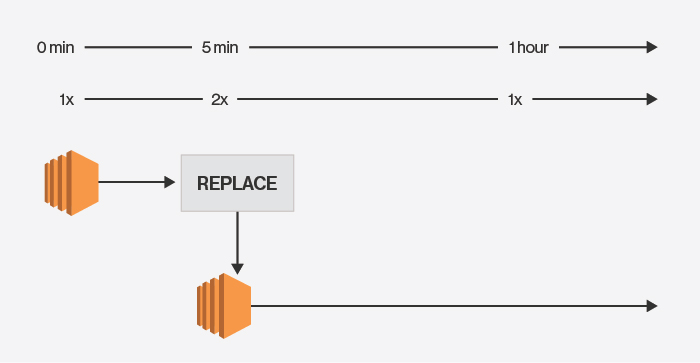
Auto Scaling在五分钟后杀死一个实例并启动另一个。
在我的这个案例中,Auto Scaling组的配置有一个问题,一个服务器连续被杀死并在有问题的同一区域内被重新启动。这意味着,每五分钟,一个新的服务器启动,旧的被取代,从而产生每小时12个实例小时的费用 - 即便在任何时间永远都只有一个实例在运行。并且该实例甚至都没有正常工作。
我一开始没有注意到,直到收到之后的帐单列表,因为这个原因出现了一笔额外的1200美金的支出。这时,我联系了AWS的支持人员。当我发现这个问题的时候我非常沮丧,但亚马逊修复了它并给了我由于坏掉的Auto Scaling组导致的额外的信用度。 AWS还针对该问题进行了检测,并给了我Auto Scaling组失控的2个月的信用度。
现在回想起来,我本应该设置Auto Scaling组的通知,我本应该验证Auto Scaling的行为不可能每15分钟超过一次。有了这些改变,最多只可能出现四倍的正常收费。这仍然是糟糕的,但却没有12倍那么糟糕。我本应该验证所有地区的服务器都正常启动了。
如何防止Auto Scaling故障
首先,订阅Auto Scaling组通知 - 即使它只是使用一个电子邮件地址,因为使用寻呼可能有点极端。管理员还应该小心该组突然“暴走”。如果确实发生了一些什么状况并且AWS Auto Scaling组不停的启动和替代服务器,管理员则可以禁用一个可用区域或阻止该组执行任何操作。把“冷静”时间增加到15分钟也许是个不错的主意,以防止类似的错误发生到完全失控。
***,确保ELB在服务器启动之后给予了足够宽裕的时间来决定是否最终会正常启动。如果该服务通常需要5分钟才能启动成功,那么给它15分钟。如果开发人员检查到他至少有2台服务器跑在ELB后面,在新的服务器正在启动时,运行的服务器必须能够处理负载。
提供额外的能力总是一个不错的主意,因为用户可能需要在修复问题的时候停掉一些服务器。请记住,AWS Elastic Beanstalk内部使用的是Auto Scaling组,因此也可以订阅对他们的通知,如果他们被设置好的话。
原文链接:http://www.searchcloudcomputing.com.cn/showcontent_91495.htm