作者介绍
余何,外号:众神的大师兄,运维心灵捕手,十余年IT金融运维经验,一直任职于某世界100强企业,参与并主导过各大神秘项目,热爱开源、感悟运维、痴迷于IT技术。
前言
It is the time you have wasted on your rose that makes your rose so important.
这是平凡的世界,不平凡的运维专栏的第一期,我很难以一种感性的方式告诉别人运维是做什么的,以至于对不同人会有不同的譬喻。
对于父母,运维是当前世界上很稳定的工作(让老人安心)。
对于妻子,运维是计算机世界的特工组织(熬夜不归的好理由)。
对于朋友,运维并不是帮人装杀毒软件(告诉别人它不是什么也很重要)。
对于业内人士,运维是可用率99.99%(我觉得以后要换一种方式)。
对于公司老板,运维是一门并不需要知道它有多精彩,但必须重视的岗位(这真的很难,也很矛盾)。
好了,让我们开启今天的主题,运维事件处理经验谈。
运维是一朵需要花时间照料的玫瑰
UIOC
为了保证可用率99.99%,除了在应用架构、资源容量上做足功夫外,运维人员还要面对一个事实,那就是异常、故障、突发事件总会发生,这在管理上必须有一个流程方法来应对之。
在我们组织内部有两个处理流程,对于突发重大事件,有专门召集各方联合诊断的UIOC(ugency incident office center),紧急事故处理中心。而一般事件,我们通过事件管理通道满足用户需求。
多团队合作
UIOC的目的在于快速调动IT资源,高效协同诊断事件,在这个过程中,开发关注应用逻辑、运营关注业务影响、运维关注底层资源、DBA关注数据库。
流程启动的第一步是将大家召集就位。沟通工具、渠道有多种,面对面沟通、邮件列表、即时通讯、视频会议等,不同团队类型有不同的处理习惯。但在事前,我们就应当将这些通道提前建立,并验证随时可用。
UIOC是一个联合诊断、积极配合过程,通常会有一个经验丰富的人员来现场指挥、协调各团队间的工作。
UIOC沟通工具很重要
UIOC六步骤
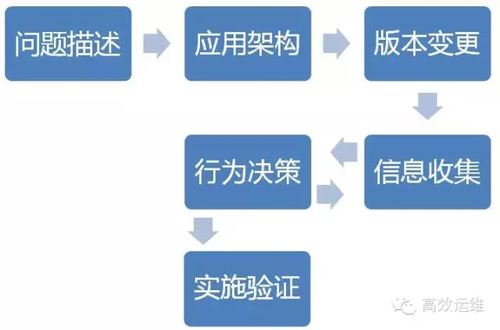
UIOC流程启动后,如没有统一管理,则很容易陷入到一片混乱中,我们一般会参照下面五点次序进行问题分析:
1.问题描述
启动UIOC后,会对问题、异常进行一个简单描述,如xx系统的xx功能无法使用。
另外,高层会关注业务影响,在这个步骤中,运营人员应当迅速的抽取出业务变化率。
2.应用架构
在问题、业务影响描述清楚后,下一步是系统负责人对应用的整体部署架构进行说明(对于问题所在模块一目了然的这步可省略)。
这个整体部署架构中包括了主要的配置信息、关联方等,其主要目的在于缩小问题范围。
3.版本变更
依据应用架构的输出来判断在这个范围内是否有组件版本发布、基础资源变更。
大部分故障都是由“变”而起,不是外部(访问量、安全攻击),就是内部(版本、变更)。
该步骤帮助我们发现内部变化,如若找到相关影响对象,可以考虑准备回滚步骤、方案。
4.信息收集
以上三步应当是习惯性地快速完成, 如仍无法准确定位到问题点的话,极有可能陷入到僵持状态中。
信息收集阶段,各团队开始各自挖矿,开发人员查看用户访问量、应用异常日志,运维人员检查基础资源情况,包括性能数据、日志信息,DBA检查数据库等待事件、top sql等,再将各自发现的可疑点共享出来,尽可能形成问题关联,比如存储发现IO延时比较高,请DBA确认是否有影响(不是所有的延时都影响数据库)。
#p#
5.行为决策
UIOC强调的是快速恢复,而不是问题分析,亦即找到问题点后可快速采取恢复方案,而不是将时间耗费在穷根问底。
UIOC准确的说是发现问题点在哪里,而不是回答为什么会有这个问题点,对于已发现的问题点,应当问:
◆是否可主备切换
◆是否可功能降级
◆是否可快速扩容
◆是否可版本回滚
在该步骤中确定快速恢复方案。
6.实施验证
在决策完毕后,实施方案,并做好验证,确保系统恢复正常。
事件处理
事件处理的是一些相对UIOC的紧急度要低、影响面较小的异常。在我们组织内部,对计算、存储、网络以及中间件的事件团队进行了整合,因此事件量大,涉及范围广,在这里介绍一些通用方法来帮助一线人员。
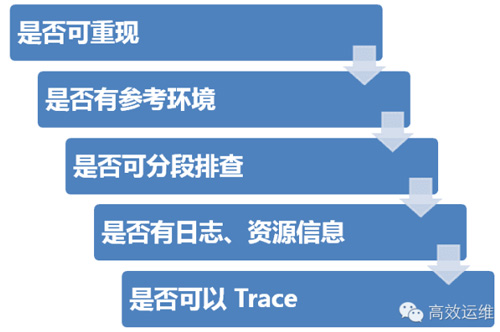
通用方法
1.是否可重现
问题是否可重现对于快速解决问题来说非常重要,但开发人员说我可以立即重现这个问题,好了,运维一线同事请放心,我们总有办法或工具帮助我们定位到问题点。
最怕的是问题出现之后就不会再有了,需要追溯原因,或者说问题的重现需要准备大量资源,比如特定时间段出现,我们要考虑部署相关工具,例如tcpdump抓包。
2.是否有参考环境
帮助你进一步快速解决问题的是一个参照物,例如一个子系统有多套环境,stg1、stg2,有参照物意味着你快速定位问题又进了一步。
3.是否可分段排查
问题是否可以分段(类似于网络异常)
找到路径上的怀疑项,通过组件替换、绕行以及验证等方式排除。
是否有日志、资源信息。
在第三步先是缩小问题范围,之后就是对此范围内的组件进行日志、资源信息检查,例如中间件日志、Windows事件管理器等。
在这个过程中发现的信息可求助于社区、百度、谷歌寻找解决答案,如果有厂商服务支持,也可以将这些信息提交给后方。
基础资源信息中关于性能的部分,如果组织内监控管理做得完善,那么这些异常告警会提前发出,也有一个集中、易用的可视化界面查看。
5.是否可以Trace
Trace意味着对问题点的活动数据进行采集或者全量查看。
Trace的使用要谨慎,Trace会影响到组件性能,甚至导致其异常退出,应当尽量避免在生产环境使用。
其包括的步骤包括:
应用服务器Debug开关
tcpdump抓包
strace系统调用
systemtap探针
heapdump内存分析
应该避免
1.碎片干扰
作为运维人员,一定要避免掉入到碎片干扰的陷阱中。
有时候开发人员并不会向你描述问题,而是抛出一段Exception stack(他也是专业人士)。
如果你不弄清楚问题,不追溯源头,而直接陷入到类似的Exception stack中,有时可以很快解决问题,但有时你将走一段弯路,最终你会发现问题根本原因和这个碎片一点关系都没有。
正确的做法是问题现象+异常信息,对于问题的快速诊断,二者缺一不可。
2.地毯扫荡
在上层压力下很容易出现地毯扫荡情况,对所有组件的所有配置进行一次扫荡检查,例如从网络设备、到物理机器、虚拟机、操作系统、中间件,这种情况也应当避免。
上层压力,下层疏导
3.消极配合
地毯扫荡和消极配合看似是矛盾的,积极配合看似就是地毯扫荡,当别人提出问题,希望你检查你所负责的相关资源时,你就陷入到了地毯扫荡之中。
总结而来,我们应该避免地毯扫荡,而避免的方法是遵循的问题处理方法论,将问题范围缩小到一定程度才开始进行地毯扫荡的。而对关联他的团队,我们应当是一个积极的配合态度。
4.无所不能
越是经验丰富、技术实力强的同事越容易陷入到这里。当他们找到问题点时,会竭尽全力的用各种高难度技术手段来帮助解决,例如在网络上无数次nat,在操作系统上hack掉问题点等,而其无意中却埋下了一个坑。
这些技术手段虽然可解决问题,但有可能增加运维复杂度、也有可能存在未验证的缺陷风险。我们并不是无所不能,无所不能应当控制在规范标准之内,或者放在研发验证之中。
我们不是无所不能的
如何一起愉快地发展
“高效运维”公众号(如下二维码)值得您的关注,作为高效运维系列微信群的唯一官方公众号,每周发表多篇干货满满的原创好文:来自于系列群的讨论精华、运维讲坛线上精彩分享及群友原创。“高效运维”也是互联网专栏《高效运维最佳实践》及运维2.0官方公众号。

提示:目前高效运维新群已经建立,欢迎加入。您可添加萧田国个人微信号xiaotianguo8 为好友,进行申请,请备注“申请入群”。
重要提示:除非事先获得授权,请在本公众号发布2天后,才能转载本文。尊重知识,请必须全文转载,并包括本行。