一、为什么要采用混合云的架构
在过去很长的时间内,大部分稍大些的互联网系统包括微博都是基于私有体系的架构,可以在某种程度理解成私有云系统。混合云,顾名思义就是指业务同时部署在私有云和公有云,并且支持在云之间切换。实际上“为什么要采用混合云”这个问题,就等于“为什么要上公有云”。我们的考虑点主要有四个方面
业务场景
随着微博活跃度的提升,以及push常规化等运营刺激,业务应对短时极端峰值挑战,主要体现在两个方面:
- 时间短,业务需要应对分钟级或者小时级。
- 高峰值,例如话题经常出现10到20倍流量增长。
成本优势
对于短期峰值应对,常规部署,离线计算几个场景,我们根据往年经验进行成本对比发现公有云优势非常明显

效率优势
公有云可以实现5分钟千级别节点的弹性调度能力,对比我们目前的私有云5分钟百级别节点的调度能力,也具有明显优势。
业界趋势
“Amazon首次公布AWS业绩:2014年收入51.6亿美元,2015年1季度AWS收入15.7亿美元,年增速超40%。”“阿里巴巴旗下云计算业务阿里云营收6.49亿元,比去年同期增长128%,超越亚马逊和微软的云计算业务增速,成为全球增速最快的云计算服务商。”
我们预计未来产品技术架构都会面临上云的问题,只是时间早晚问题。
安全性
基于数据安全的考虑,我们现阶段只会把计算和缓存节点上云,核心数据还放在私有云;另外考虑到公有云的技术成熟度,需要支持在多个云服务直接进行业务灵活迁移。
基于上述几点考虑,我们今年尝试了以私有云为主,公有云为辅的混合云架构。核心业务的峰值压力,会在公有云上实现,业务部署形态可参考下图

下面介绍介绍技术实现。整体技术上采用的是Docker Machine + Swarm + Consul的框架。系统分层如下图

二、跨云的资源管理与调度
跨云的资源管理与调度(即上图中的pluto部分)的作用是隔离云服务差异,对上游交付统一的Docker运行环境,支持快速弹性扩缩容及跨云调度。功能上主要包括:
- 系统初始化
- 元数据管理
- 镜像服务
- 网络
- 云服务选型
- 命令行工具
- 其他
系统界面如下图:

系统初始化
最初技术选型时认为Machine比较理想,仅需要SSH通道,不依赖任何预装的Agent。我们也几乎与阿里云官方同时向Docker Machine社区提交了Driver的PR,然后就掉进了大坑中不能自拔。
例举几个坑:
- 无法扩展,Machine的golang函数几乎都是小写,即内部实现,无法调用其API进行功能扩展。
- 不支持并发,并发创建只能通过启动多个Machine进程的方式,数量多了无法承载。
- 不支持自定义,Machine启动Docker Daemon是在代码中写死的,要定义Daemon的参数就非常ugly。
目前我们采用的是Puppet的方案,采用去Master的结构。配置在GitLab上管理,变更会通过CI推送到pluto系统,然后再推送到各实例进行升级。在基础资源层面,我们目前正在进行大范围基础环境从CentOS 6.5升级到CentOS 7的工作。做这个升级的主要原因是由于上层基于调度系统依赖Docker新版本,而新版本在CentOS 6.5上会引发cgroup的bug,导致Kernel Panic问题。
元数据的管理
调度算法需要根据每个实例的情况进行资源筛选,这部分信息目前是通过Docker Daemon的Label实现的,这样做的好处是资源和调度可以Docker Daemon解耦。例如我们会在Daemon上记录这个实例的归属信息:
- —label idc=$provider #记录云服务提供商
- —label ip=$eth0 #记录ip信息
- —label srv=$srv #记录所属业务
- —label role=ci/test/production…
- …
目前Docker Daemon最大的硬伤是任何元数据的改变都需要重启。所以我们计划把元数据从Daemon迁移到我们的系统中,同时尝试向社区反馈这个问题,比如动态修改Docker Daemon Label的接口(PR被拒,官方虽然也看到了问题,但是比较纠结是否要支持API方式),动态修改registry(PR被拒,安全因素),动态修改 Docker Container Expose Port(开发中)。
镜像服务
为了提升基础资源扩缩容的效率,我们正在构建虚机镜像服务。参考Dockerfile的思路,通过描述文件定义定义虚机的配置,支持继承关系,和简单的初始化指令。通过预先创建好的镜像进行扩缩容,可以节省大约50%的初始化时间。
描述文件示意如下:
centos 7.0:
– dns: 8.8.8.8
– docker:
– version: 1.6
– net: host
meta:
– service: $SRV
puppet:
– git: git.intra.weibo.com/docker/puppet/tags/$VERSION
entrypoint:
– init.sh
不过虚机镜像也有一些坑,例如一些云服务会在启动后自行修改一部分配置,例如router, dns, ntp, yum等配置。这就是上面entrypoint的由来,部分配置工作需要在实例运行后进行。
网络
网络的互联互通对业务来说非常关键,通常来说有三种方案:公网,VPC+VPN,VPC+专线。公网因为性能完全不可控,而且云服务通常是按照出带宽收费,所以比较适合相互通信较少的业务场景。VPC+VPN实际链路也是通过公网,区别是安全性更好,而且可以按照私有云的IP段进行网络规划。专线性能最好,但是价钱也比较好,且受运营商政策影响的风险较大。
网络上需要注意的是包转发能力,即每秒可以收发多少个数据包。一些云服务实测只能达到10万的量级,而且与CPU核数、内存无 关。也就是说你花再多的钱,转发能力也上不去。猜测是云厂商出于安全考虑在虚机层面做了硬性限制。我们在这上面也中过枪,比如像Redis主从不同步的问题等等。建议对于QPS压力比较重的实例进行拆分。
云服务选型
我们主要使用的是虚机和软负载两种云服务。因为微博对缓存服务已经构建一套高可用架构,所以我们没有使用公有云的缓存服务,而是在虚机中直接部署缓存容器。
虚机的选型我们重点关注CPU核数,内存,磁盘几个方面。CPU调度能力,我们测试总结公有云是私有云的1.2倍,即假设业务在私有云上需要6个核,在公有云上则需要8个。
内存写入速度和带宽都不是问题,我们测试发现甚至还好于私有云,MEMCPY的带宽是私有云的1.2倍,MCBLOCK是1.7倍。所以内存主要考虑的是价钱问题。
磁盘的性能也表现较好,顺序读写带宽公有云是私有云的1.4倍,随机写是1.6倍。唯一要注意的是对于Redis这种业务,需要使用I/O优化型的虚机。
以上数据仅供参考,毕竟各家情况不一样,我们使用的性能测试工具:sysbench, mbw, fio,可自行测试。
CLI客户端(命令行工具)
为了伺候好工程师们,我们实现了简单的命令行客户端。主要功能是支持创建Docker容器(公有云或私有云),支持类SSH登陆。因为我们要求容器本身都不提供SSH(安全考虑),所以我们是用Ruby通过模拟docker client的exec命令实现的,效果如下图:

其他方面
跨域的资源管理和调度还有很多技术环节需要处理,比如安全,基础设施(DNS、YUM等),成本核算,权限认证,由于这部分通用性不强,这里就不展开了。
#p#
三、容器的编排与服务发现
提到调度就离不开发现,Swarm是基于Consul来做节点发现的。Consul采用raft协议来保证server之间的数据一致性,采用 gossip协议管理成员和传播消息,支持多数据中心。Consul集群中的所有请求都会重定向到server,对于非leader的server会将写请求转发给leader处理。
Consul对于读请求支持3种一致性模式:
default :给leader一个time window,在这个时间内可能出现两个leader(split-brain情况下),旧的leader仍然支持读的请求,会出现不一致的情况。
consistent :完全一致,在处理读请求之前必须经过大多数的follower确认leader的合法性,因此会多一次round trip。
stale :允许所有的server支持读请求,不管它是否是leader。
我们采用的是default模式。
除了Swarm是基于Consul来做发现,业务直接也是通过Consul来做发现。我们服务采用Nginx来做负载均衡,开源社区的方案例如 Consul Template,都需要进行reload操作,而reload过程中会造成大量的失败请求。我们现在基于Consul实现了一个nginx- upsync-module。

Nginx仅需在upstream配置中声明Consul集群即可完成后端服务的动态发现
- upstream test {
- # fake server otherwise ngx_http_upstream will report error when startup
- server 127.0.0.1:11111;
- # all backend server will pull from consul when startup and will delete fake server
- consul 127.0.0.1:8500/v1/kv/upstreams/test update_timeout=6m update_interval=500ms strong_dependency=off;
- upstream_conf_path /usr/local/nginx/conf/upstreams/upstream_test.conf;
- }
这个模块是用C语言实现的,效率已经经过线上验证,目前验证在20W QPS压力没有问题。而且这个模块代码已经开源在Github上,也欢迎大家提Issue:https://github.com/weibocom/nginx-upsync-module。
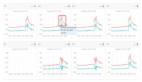
下图是我们做的几种方案的性能对比:

当然我们的RPC框架motan也会支持Consul,实现机制同样也是利用Consul的long polling机制,等待直到监听的X-Consul-Index位置发生变化,这个功能已经在我们内网验证通过,不过由于依赖整个motan框架,所以目前还没有开源。
Consul的监控
由于Consul处于系统核心位置,一旦出现问题会导致整体所有集群失联,所以我们对Consul做了一系列保障措施,其中所有Consul Server节点监控指标如下

Leader节点监控指标如下图

Consul的坑
除了使用不当导致的问题之外,Consul Server节点通信通道UDP协议,偶发会出现server不停被摘除的现象,这个问题官方已在跟进,计划会增加TCP的通道保证消息的可靠性。
容器调度
容器调度基于Swarm实现,依赖Consul来做节点发现(话说Swarm才刚刚宣布Production Ready)。容器调度分为三级,应用-应用池-应用实例,一个应用下有多个应用池,应用池可以按机房和用途等来划分。一个应用池下有多个Docker容器形式的应用实例。

我们利用Swarm的Filter机制,实现了适应业务的调度算法。整个调度过程分为两步:主机过滤:指定机房、内存、CPU、端口等条件,筛选出符合条件的主机集合;策略选择:对符合条件的主机集合进行打分,选择出最合适的主机,在其上创建容器以部署应用。调度子系统Roam实现了批量的容器调度与编排。
业务调度
容器调度是于业务无关,具体串联起资源管理,容器调度,发现等系统,完成业务容器最终跨云部署的是我们的JPool系统。JPool除了完成日常的业务容器上线发布之外,最重要的是完成动态扩缩容功能,使业务实现一键扩容、一键缩容,降低快速扩容成本。一次扩容操示意图如下

围绕这调度和发现,需要很多工具的支撑:
例如为了使业务接入更加方便,我们提供了自动打包工具,它包括代码打包、镜像打包的解决方案,支持svn、gitlab等代码仓库,业务仅需要在工程中定义pom.xml和Dockerfile即可实现一键打包代码,一键打包镜像,过程可控,接入简单。

我们还对Docker的Registry,我们进行了一些优化,主要是针对混合云跨机房场景,提供跨机房加速功能,整个服务架构如下:

#p#
四、混合云监控体系
微博体系在经历了多年的IT建设过程后,已经初步建立了一套完整的信息化管理流程,极大地提升了微博业务能力。同时微博开展了大量的IT基础设施建设(包括网络、机房、服务器、存储设置、数据库、中间件及各业务应用系统等)。
针对于混合云体系,我们提供了一套完整的监控告警解决方案,实现对于云上IT基础架构的整体监控与预警机制,最大程度地保证了微博体系能够稳定地运行在混合云体系上,不间断地为用户提供优质的服务。监控告警解决方案实现了四个级别上的监控与预警:
- 系统级监控
- 业务级监控
- 资源级监控
- 专线网络监控
- 系统级监控
混合云体系支持的系统级监控(与新浪sinawatch系统的对接)包括:CPU,磁盘,网卡,IOPS,Load,内存

业务监控
混合云体系集成了目前微博业务监控平台Graphite,自动提供了业务级别(SLA)的实时监控与告警。所有的配置与操作都是系统自动完成的,不需要用户进行额外的配置操作。

业务级别的监控包括:
- JVM监控: 实时监控堆、栈使用信息、统计gc收集时间、检查JVM瓶颈等。
- 吞吐量监控: 实时监控业务系统吞吐量(QPS或TPS)。
- 平均耗时监控: 实时监控业务系统接口的平均耗时时间。
- 单机性能监控: 实时监控单台服务器的各种业务指标。
- Slow监控: 监控服务器集群,实时显示当前业务系统中最慢的性能瓶颈。
资源监控
混合云体系集成了目前微博资源监控平台sinadsp,自动提供了对各种底层资源的实时监控与告警。所有的配置与操作都是系统自动完成的,不需要用户进行额外的配置操作。
具体的监控指标包括:命中率,QPS/TPS,连接数,上行/下行带宽,CPU,内存。

五、前进路上遇到的那些坑
需要注意的坑,实际在各部分中都有提及。今天分享的主要内容就是这些了,当然业务上云,除了上面这些工作之外,还存在很多技术挑战要解决。比如跨云的消息总线,缓存数据同步,容量评估,流量调度,RPC框架,微服务化等。
Q&A
Q1 : 为什么选Consul?看中有对比Zookeeper、etcd,尤其是etcd?
我们有对比etcd和consul,主要还是看重了consul基于K-V之外额外功能,比如支持DNS,支持ACL。另外etcd不对get request做超时处理,Consul对blocking query有超时机制。
Q2 : 上面提到的方案主要是Java体系, 对于其他语言(php, nodejs, golang)体系系统的是否有很好的支持(开发、测试、发布部署、监控等)?
已经在开始php的支持。其实容器化之后,所有语言都是适用的。
Q3 : Docker registry底层存储用的是什么,怎么保障高可用的?
底层使用的Ceph,前端无状态,通过DNS做跨云智能解析,加速下载。
Q4 : Consul temple reload nginx时为什么会造成大量请求失败呢,不是graceful的吗?
是graceful的,在QPS压力较大的情况下,由于需要进行大量重连,过程中会产生较多失败请求。
Q5 : 刚才提到的调度系统是自己开发的?还是基于开源改的?
是基于Swarm二次开发的。
Q6 : 容器跨主机通信是host网络吗?
对,目前线上采用的是host网络。
Q7 : Ceph IO情况怎么?高IO的是不是不太适合用Ceph?
针对Registry场景Ceph IO是可以胜任的。不过Ceph暂时还没有宣布Production Ready,所以对于极端业务场景,请谨慎。
关于作者

微博研发中心技术经理及高级技术专家。2008年毕业于北京邮电大学,硕士学位。毕业后就职华为北研。2012年加入新浪微博,负责微博Feed、用户关 系和微博容器化相关项目,致力于Docker技术在生产环境中的规模化应用。2015年3月,曾在QClub北京Docker专场分享《大规模 Docker集群助力微博迎接春晚峰值挑战》。
【内容来源:高可用架构公众号ArchNotes】