作者简介
丛磊 ,SAE总负责人 SAE创始人,2006年加入新浪公司,2008年起开始带领技术团队从事云计算方面的研究和开发,2009年作为技术经理主导开发了国内首个公有云Sina App Engine。经过数年的努力,SAE已经拥有数十万开发者,成为国内云计算数一数二的PaaS平台。作为国内最早研究云计算的一线工程师,丛磊具有丰富开发和设计经验,并且拥有两项算法专利。目前,丛磊负责整个新浪公有云计算业务,同时担任可信云认证的评审专家。
需求场景
作为公有云计算平台,SAE长期以来一直饱受各种攻击,这里面涉及各种类型,包括Syn-flood、UDP-floold、DNS/NTP反射、TCP flag攻击等,当然这里面最常见还是基于HTTP协议的CC攻击,因为篇幅有限,所以今天先不介绍TCP/IP防火墙,集中在HTTP层面。
我们可以把正常的HTTP访问分为:
HTTP访问=正常访问+抓站+攻击
这三类行为有明显的区分特征,主要体现在频率和特征上,比如抓站的目的是抓取信息,而不是让你网站502,而攻击往往是要把网站Rank打下来,直接打到用户访问不了。而这三类行为又没有特别清晰的界限,比如何种访问叫正常抓站?抓到什么程度叫恶意抓站?这些定义往往是跟用户业务行为相关,从云计算平台的角度界定起来有难度。举个例子,内推网是SAE上的一个HR招聘网站,每天有上千万的访问,从内推的角度肯定希望各大搜索引擎能够合理的抓取/索引,扩大信息出口,但又不希望同行抓取,保护有价值的内容,但这个度是跟业务相关的,可能在业务初期可以松点,业务起来后可以严一点。
两层HTTP防火墙
从云计算平台,无法帮用户设定这些跟业务紧密相关的参数,只能把这个关交给用户自身,这也就形成了“应用防火墙”。但从云计算平台角度,又有义务帮用户挡住恶意的CC攻击,于是,SAE把这两类需求组成了两个产品:
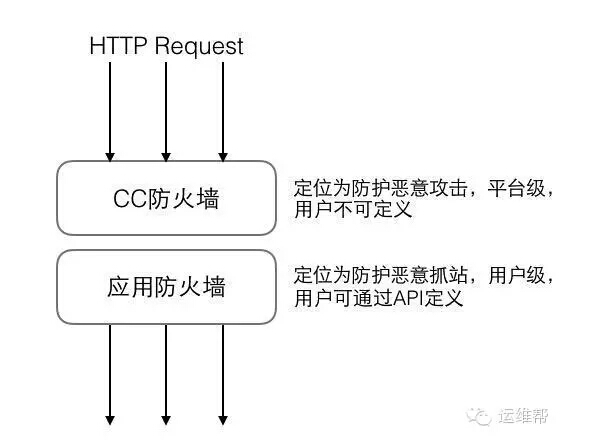
SAE HTTP层防火墙组成
“应用防火墙”,用户可以从SAE操作面板看到,应用防火墙的难点在于充分自定义,包括触发阈值后的行为,这部分SAE近期将进行版本升级,功能将会更强大,今天先重点说“CC防火墙”。
CC防火墙
既然CC防火墙的定位是防护恶意HTTP攻击,那么需要解决的环节有:
1,如何实时分析海量HTTP日志?
1,从日志中,如何发现攻击?用什么策略判断是攻击?
2,断定是攻击后,用什么办法拦住后续请求?
我们先来看整体CC防火墙架构图:
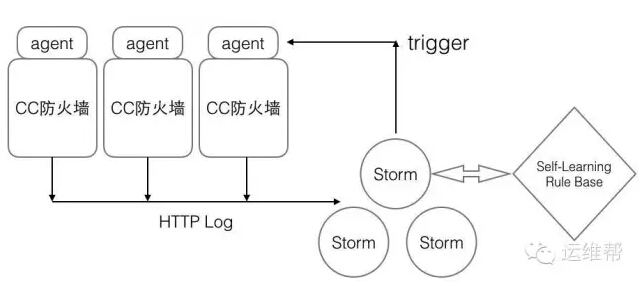
CC防火墙架构图
每天SAE产生上10亿的请求,这些请求都会经过CC防火墙,由日志重定向系统发送到Storm日志分发系统,而策略中心会下发策略,触发策略的IP和应用会由trigger反馈到CC防火墙上的agent,并最终更新到CC防火墙的内存里。
策略中心
策略分成下面两个维度:
- 首先确定哪些应用可能被攻击(当前PV/IP、历史PV/IP),这里面需要降噪处理,否则有些业务突然正常的流量突增(秒杀)可能收到影响
- 针对A筛选出来的可能被攻击的应用,分析其IP行为,这里分为两步:
- 将IP按行为进行分组,行为类似的IP为一组,组规模越大的可疑性越大(动用的资源更多)
- 针对群组IP分析,主要依靠 Feq(Request)/Num(URI),可疑性与频率成正比,而与访问地址的离散度成反比
自学习:
任何规则都会存在误杀,所以必要的自学习是必要的,系统会跟实际情况通过梯度下降算法调整策略参数的最优点。另外,对于机器学习,准确率和召回率是一对矛盾体,针对我们遇到的场景,我们的所有参数学习都偏向准确率,因为召回率可以由应用防火墙做补充,从我们线上运行的实际情况看,准确率为100%,目前没有误报。
#p#
防火墙的实现
防火墙本身没有用任何商用产品,完全是基于传统Linux服务器,最原始的CC防火墙是基于Nginx做的,针对触发规则的IP返回403(NGX_HTTP_FORBIDDEN),但经过我们实验,这样在请求量大的时候会有性能问题,主要是消耗CPU,容易在带宽没有吃满的把CPU跑满,这个问题后来我们发现有个办法优化:
优化Nginx
不返回403,而直接返回444(NGX_HTTP_CLOSE)
NGX_HTTP_CLOSE是一个Nginx自定义的返回码,目的是直接关闭链接,而不进行write_handle后面的输出,换句话说,要比403等返回节约大量CPU,看这段Nginx代码:
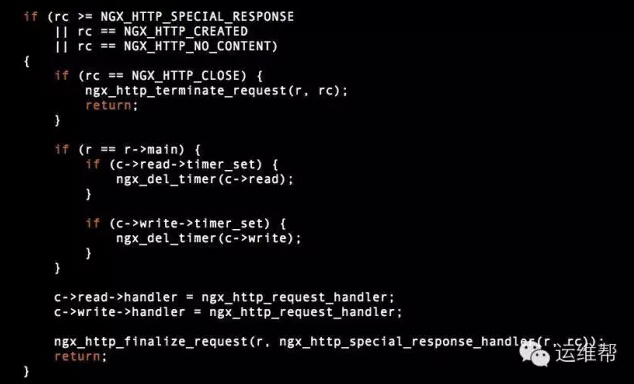
http/ngx_http_request.c
当rc为444时,直接就把connection关闭,这对于CC防火墙来说是最理想的结果,因为不需要组装response。
iptables
Nginx 444的性能已经有了很大提升,但离我们的期望还有些距离,那么还能不能优化呢?我们想到了iptable extension string,可以根据sk_buff的data的特征进行过滤,那么效果怎么样呢?
我们做一个实验,以相同的10000并发压测一个静态URL 100万次,在Nginx防火墙上,表现为:
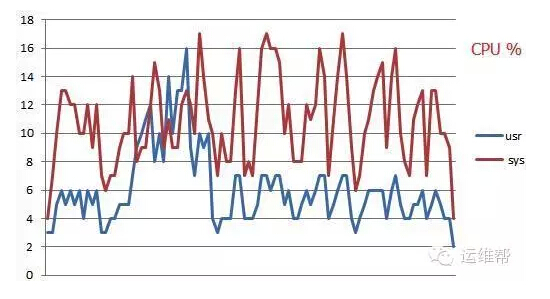
nginx防火墙CPU占用率
我们换成iptabels string防火墙,表现为:
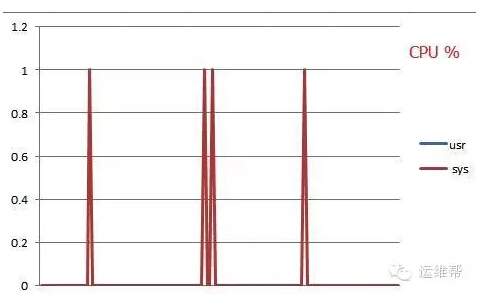
iptables防火墙
看到差距了吗,非常大!!!同样的压缩指标在iptables面前简直不算什么,原因也很简单,就是直接在netdev层根据sk_buff的data段分析,无需进行应用层协议解析,所以才会有如此巨大的性能提升。那么kmp和bm算法有区别吗?经过我们实验,在测试场景上区别微乎其微。
当然,在这里要注意两点:
- 指定from和to,因为只需要判断匹配data的部分,而不是全部
- 对于string,要匹配HTTP协议,当然这里有精确度问题,这个要改进的话,原生iptables模块是没办法了,可以写个iptabels扩展解决
drop & reject
在我们Linux系统团队具体实施时,又遇到一个有趣的问题,就是当iptables匹配这个规则后,执行的动作,我们有两个选择drop和reject,drop故名思议就是丢包,但这样会触发TCP层的重试,相当于deley每次HTTP攻击的时间,这是符合我们的预期的,因为增加了攻击者的时间成本。再来看reject,iptables user层支持大体上两种回报,一种是ICMP的控制包,一种是TCP层的reset包,这两种包在攻击方都会引起连接中断,从而可以立即发起下一个攻击请求,所以显然drop是正确选择。
但是drop带来一个附属问题,就是链接不释放的问题,因为正常的HTTP流量监测是:
step1:C<=>S建立三次握手连接
step2:C发起HTTP请求
step3:S分析数据包,匹配规则后丢弃
step4:C持续重发,直到重传定时器判断超时
在这里有一个问题,就是当drop后,S端的connection是还在的,也就是说,这时候你在S端利用netstat、ss类似的工具查看,可以发现ESTABLISHED连接存在,这样虽然攻击者的请求时间变长了,后续的包进不来了,但是会耗费大量的connection,从而占用大量内核资源,导致系统性能下降。怎么解决呢?
Netlink-Queue
我们的工程师发现,可以利用ip-queue,处理被规则匹配的攻击包,然后修改包为reset包,从而使S端释放链接,事实证明,这个办法非常有效。
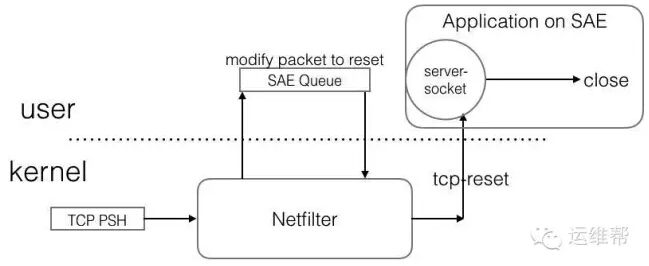
TCP包处理流程
如图所示,我们所做的只是将攻击包置reset位,等待用户层进程处理,处理后,触发应用层释放socket,从而保护了服务端资源。
当Queue起作用后,我们可以监控Queue状态以获取服务状态,类似:
- [root@dev include]# cat /proc/net/ip_queue
- Peer PID : 7659
- Copy mode : 2
- Copy range : 2048
- Queue length : 0
- Queue max. length : 1024
- Queue dropped : 0
- Netlink dropped : 0
那么Queue会不会成为瓶颈呢?是有可能的,因为ip queue handler对于一个协议簇不能支持多队列,如果遇到这种情况,可以考虑采用nfqueue,它可以支持多队列,提高处理速度,当然这个可以结合实际的场景进行。另外,还可以调整netlink缓存进行优化。
总结
SAE利用CC防火墙结合应用防火墙,有效的保护了用户的HTTP请求,当然目前这套系统还存在着不足,包括Storm计算能力、应用防火墙的自定义性不足、应用防火墙重定向等方面,这也是我们后面的工作方向。