本文由ChrisMu翻译向36大数据投稿,并经由36大数据编辑发布,原文作者Kunal Jain。任何不标明来源36大数据及本文链接http://www.36dsj.com/archives/37108 均为侵权。
前言
我刚和一位老友恢复了联系。她一直对数据科学很感兴趣,但10个月前才涉足这一领域——作为一个数据科学家加入了一个组织。我明显感觉到她已经在新的岗位上学到了很多东西。然而,我们聊天时,她提到了一个至今在我脑海里都挥之不去的事实或者说是问题。她说,不论她表现如何,每一个项目或分析任务在令经理满意之前都要做好多次。她还提到,往往事后发现原本不需要花这么多时间!
听起来是不是很像你的遭遇?你会不会在得出像样的答案之前反复分析很多次?或者一遍又一遍地为类似的活动写着代码?如果是这样的话,这篇文章正好适合你。我会分享一些提高效率和减少不必要的重复工作的方法。
备注:请别误会。我不是说迭代都不好。这篇文章的重点在于如何识别哪些迭代是必要的,哪些是不必要且需要避免的。
什么原因导致了数据分析中的重复工作?
我认为没有加入新信息,就没必要重复分析(后面提到一个例外)。下面这些重复工作都是可以避免的:
1、对客户问题的诊断有偏差,不能满足需求,所以要重做。
2、重复分析的目的在于收集更多的变量,而你之前认为不需要这些变量。
3、之前没有考虑到影响你分析活动的偏差或假设,后来考虑到了所以要重做。
哪些迭代是必要的呢?下面举两个例子,一、你先建立了一个6个月后的模型,随后有了新的信息,由此导致的迭代是健康的。二、你有意地从简单的模型开始逐渐深入理解并构建复杂模型。
上面没有涵盖所有可能的情况,但我相信这些例子足够帮助你判断你的分析迭代是不是健康的。
这些生产力杀手的影响?
我们很清楚一点——没有人想在分析中出现不健康的迭代和生产力杀手。不是每个数据科学家都乐于一边做一边增加变量并反复运行整个分析过程。
分析师和数据科学家会因为不健康迭代和丧失效率而深感挫败,缺乏成就感。那么让我们尽一切努力来避免它们吧。
小贴士:如何避免不健康迭代并增加效率
技巧1: 只关注重大问题
每个组织都有很多可以用数据解决的小问题!但雇一个数据科学家的主要目的不在于解决这些小问题。好钢要用在刀刃上,应该选取3到4个对整个组织影响最大的数据问题交给数据科学家来解决。这些问题一般具有挑战性,会给你的分析活动带来最大杠杆(或者收获满满或者颗粒无收,想象一下借贷炒股)。当更大的问题没被解决时,你不应当去解决小问题。
听起来没什么,但实际上很多组织都没做好这一点!我看到很多银行没用数据分析去改善风险评分,而是去做市场营销。有些保险公司没用数据分析提升客户留存率,而是试图建立针对代理机构的奖励计划。
技巧2: 一开始就创建数据分析的演示文稿 (可能的布局和结构)
我一直这样做并且受益匪浅。把分析演示稿的框架搭起来应该是项目启动后的第一件事。这听起来或许有悖常理,然而一旦你养成这个习惯,就可以节省时间。
如何搭框架呢?
你可以用ppt、word、或者一段话来搭框架,形式是无关紧要的。重要的是一开始就要把所有可能情况列出来。例如,如果你试图降低坏账冲销率,那么可以像下面一样布局你的演示文稿:
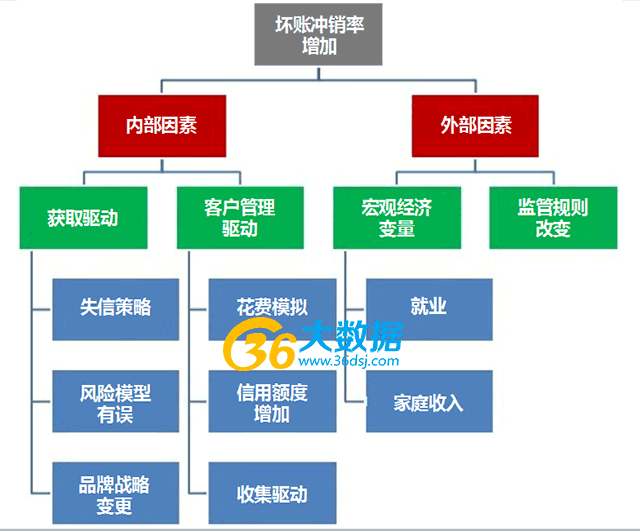
接下来,你可以考虑每个因素如何影响坏账冲销率?例如,由于给客户增加了信用额度导致银行的坏账冲销率增加,你可以:
首先,确定那些信用额度没被增加的客户并没有导致此次坏账冲销率增加。
下一步,用一个数学公式来测量这个影响。
一旦你把分析中的每一个分支都考虑到了,那么你已经为自己创造了一个良好的起点。
技巧3: 事先定义数据需求
数据需求直接源于最后的分析结果。如果你已经全面地规划了要做哪些分析、产生什么结果,那么你将知道数据需求是什么。这里有几个提示来帮助你:
• 试着赋予数据需求一个结构: 不单是记下变量列表,你应该分门别类地想清楚分析活动需要哪些表格。以上面增加坏账冲销率为例,你将需要客户人口统计表,过往市场营销活动统计表,客户过去 12 个月的交易记录,银行信贷政策变更文件等资料。
• 收集你可能需要的所有数据: 即使你不是 100%肯定是否需要所有的变量,在这一阶段你应该把所有数据都收集起来。这样做工作量大一些,但是与在以后的环节增加变量收集数据相比,还是更有效率一些。
• 定义您感兴趣的数据的时间区间。
技巧 4: 确保你的分析可重现
这个提示听起来可能很简单——但初学者和高级分析人员都难以把握好这一点。初学者会用Excel执行每一步活动,其中包括复制粘贴数据。对于高级用户,任何通过命令行界面完成的工作都可能不可重现。
同样,使用记事本(notebook)时需要格外小心。你应该克制自己修改以前的步骤,尤其是在前面的数据已经被后面的步骤使用的情况下。记事本在维护这种涉及前后数据勾稽关系的数据流方面表现地非常强大。但是如果记事本中没维护这种数据流,它也会非常没用。
技巧5: 建标准代码库
没必要为简单的操作一次又一次重写代码。它不仅浪费时间,还可能会造成语法错误。另一个窍门是创建常见操作的标准代码库并在整个团队中共享。
这将不仅确保整个团队使用相同的代码,而且也使他们更有效率。
技巧6: 建中间数据集市
很多的时候,你会反复需要同一批信息。例如,你将在多个分析和报告中用到所有客户信用卡消费记录。虽然你可以每次都从交易记录表中提取,但是创建包含这些表的中间数据集市,可以有效节省时间和精力。同样,市场营销活动的汇总表也没必要每次都查询提取一次。
技巧7: 使用保留样本和交叉验证防止过度拟合
很多初学者低估了保留样本和交叉验证的强大。很多人倾向于认为只要训练集足够大,几乎不会过拟合,因此没必要交叉验证或保留样本。
有这种想法,往往会在最后出岔子。不单我这样说——可以看一下Kaggle上任意竞赛公开或非公开的排行榜。你会发现前十名中有些人不再过拟合时他们的排名就不再下降了。你可以想象这些都是高级数据科学家。
技巧8: 集中一段时间工作并且有规律地休息
对于我来说,最佳的工作状态是集中利用2-3小时解决一个问题或项目。作为一名数据科学家,你很难同时完成多项任务。你需要以自己的最佳状态对待一个单独的问题。对于我来说,2-3 小时的时间窗口最有效率,你可以依据个人情况自行设定。
后记
上面这些就是我提高工作效率的一些方法。我不强调非要第一次就把事情做好,但是你必须养成每一次都能做好的习惯——这样你才能成为一个专业的数据科学家。
你有什么提高工作效率的好方法吗?有的话请在下面的评论中留言。