












前几天翻出了2012年2月在微博上发出的一条信息(图1),当时我为什么会那么兴奋,还得从更早的时候说起。
(图1 2012年的一条微博)
初次失败
2010年初,有个地图团队的PM找到我,演示了一份PPT,那是某个公司的统计分析系统的对外交流材料。据说这份材料先是被厂长看到,觉得做的挺好,就安排下面的人看是否也能做一套。我看了之后,发现就是针对某个互联网产品的流量、用户量的几个页面展示,针对地域、渠道等几个维度可以展开分析。心想这种系统在我们的Log统计平台上很容易用几个任务实现出来。但Log统计平台是以统计任务来管理的,虽然功能强大,但是不利于展示上的组织。对于一个业务线来说,就是一组报表,并没有层级管理。相比之下,PPT中演示的系统在界面组织上,就会好很多。我就给这位PM说,这套系统太简单了,既然我们要做,就要比他们做的牛逼。我先考虑一下,然后给出一套方案。
就这样,我和团队的三四个兄弟开始考虑如何做一套牛逼的方案,调研来调研去,发现还是数据仓库教材里介绍的数据立方体的模型,适合做这件事。于是拿着这套方案和PM沟通,PM听了介绍之后,说要是真的可以实现,我们的系统就太强大了。就这么敲定了。那时的我一是会希望自己做的事情非常独特,超越之前的任何方案,二是根本不会考虑人力是否能支持,***真正能投入到本项目的也就只有一个正式员工外加一个实习生。产品方案定了,接下来就是技术选型。
数据立方体是多维数据模型的一个通俗的叫法,主要由维度和指标两部分组成,比如地域是一个维度,操作系统也是个维度,销售额是一个指标,注册用户数也是个指标,成单量也是一个指标。那么我们就可以通过维度组合,看这种组合下的指标情况。如图2:
(图2 数据立方体的样例)
通过这个数据立方体,我们就可以看来自北京的,使用iOS的销售额是多少。这个模型非常清晰和简单,难点在于数据规模。我们针对百度的流量分析,可以拆开多个维度,比如时间、地域、渠道、操作系统、浏览器版本、频道、行为类型等。每个单位时间内,所产生的数据条数就是所有维度的乘积,假设每个维度有10个项目,如果有10个维度,那么就会产生10^10 条记录。每条记录按1KB大小,那么就是10TB数据量。如果在这个基础上做计算,一台机器的性能是显然撑不住的。
我们就在寻找适合在这种数据规模上进行查询的存储系统。找来找去,发现InfoBright这一存储引擎最合适,它采用列式存储,在针对多维数据分析这种模型上,性能很好。但因为是单机的,支持的数据规模有限,我们对某些维度的元素进行了聚合,来降低数据量,***降到半年的累计数据预计几百G。就这样,我们在半个正式员工、两个实习生的人员配置下,开启了整个项目。当时我是雄心勃勃,还把部门的高级总监邀请到开发群里,因为针对流量数据的多维分析,显然部门老大是最需要的。两个月后,悲剧发生了。
产品是做出来了,但多个维度的组合查询性能一塌糊涂,我有时候在界面上做了个查询,半个小时后都还看不到结果,根本没法用,整个产品只能算个半吊子的Demo,连部门老大也退出了群。在我这工作的八年的职业生涯中,有两个项目我认为是彻底的失败了,一个就是这个cube项目,另一个是基于impala改进的一个交互式查询产品,以后有机会再介绍。认识到性能问题后,我们又尝试将查询引擎从InfoBright替换到InfiniDB,只能说略好,但没有本质区别。
顺带交代两句这两个存储引擎的命运,InfoBright这家波兰公司的产品,在这两年转型做针对物联网的存储引擎了。而InfiniDB在去年的10月1日宣布了破产。看来创业公司纯粹做一款数据库引擎,日子并不会太好过。
出了存储层的问题,还有查询解释层Mondrian的性能问题,以及报表引擎JPivot的性能问题,数据导入的性能问题,预处理数据的计算性能问题,数据字段变更的维护问题等。总之在一个不合适的时机,提出了一个比较理想化的idea,结果可想而知了。
渐入佳境
这次项目失败后,我对数据立方体这种理论化的模型产生了怀疑,觉得在现实场景下走不通,作为数据仓库教材里的内容讲讲帮助理解,还是可以的。又过了一年,成立了基础架构部数据团队,并从Google聘请了一位总监,就是开始我在截图里提到的“硅谷知青” Alex Lv。他来百度之前,在Yahoo干过7年,Google干过5年,一直围绕数据仓库方向,可以说是这一领域的资深专家,Google的Tenzing引擎,就是他的团队做出的。他来了之后,真的是把我的思路打开了一大圈,相比之下,我之前对数据架构的理解真的太狭隘了。
他先是给我们提出了数据分层的金字塔模型,决定构建Baidu Data Warehouse(UDW),能够将用户在百度所有产品线的行为统一到一起去。有了这个地基,剩下的数据使用问题,就变得容易了。
这就回到了文章开头我发微博的那天,Alex Lv给我讲解了在UDW基础之上,将用户数据按照时间细粒度汇聚,可以根据不同维度组合查询,所有的报表需求都在这个基础上出。相比之下,我们之前的报表数据,都是直接从原始数据,经过计算,生成统计结果,计算效率是很低的,中间数据没有得到重复使用。
相比cube项目,常规报表数据是例行跑出的,而不是实时交互,这对查询性能要求没那么高。在UDW的基础之上,数据立方体的思路我意识到竟然能很好的解决计算资源浪费的问题,惊叹之余,发出了开头的那条微博。
对于交互式查询的需求,问题是一样存在的。我们数据团队是由两个团队合并创建的,一个是我所带领的数据平台团队,一个是内部叫做Doris的分布式查询团队。Doris主要是解决海量数据下,使用MPP架构,满足毫秒级的查询问题(对外的百度统计以前就使用了这一系统)。如果能把它改造一下,能够对接报表引擎,就可以满足。
这个最重要的改造就是要支持SQL。这一思路在一位Google的架构师James Peng的加入,得以传递。Doris团队的人员花了两周时间,直接将Doris作为mysql的存储引擎,这样就实现了通过mysql直接访问doris,支持了SQL语法。其实InfoBright也是这么一个实现思路。于是这样查询性能的问题也解决了。所有的核心报表,都通过数据立方体来实现,展现部分用了Oracle BIEE。
可以这么说,Oracle BIEE是我用到过了最烂的企业软件,第二烂的是Oracle ERP软件。虽然基于多维数据模型,实现了报表的基本需求。但是有两个严重的问题,一是BIEE配置报表非常麻烦,即使规整好的数据,还在再建一层数据模型,多此一举,界面操作非常复杂;二是数据的预处理即ETL工作比较复杂,数据源的变更,会导致结果出错,ETL计算周期长,导致报表发送延迟。总之是能基本满足,但不是特别的优雅。后来我们又开发了自己的可视化系统,解决报表展示问题。
发挥魔力
我在百度工作这几年,一直很反对做半吊子的产品,像我前面提到的cube项目,就是半吊子的典型。是围绕某个问题的一个解决方案,但这一解决方案很不成熟,用起来很不爽。《Lean Startup》里传递的一种理念是要做MVP(Minimium Viable Product,最小可用产品),先做一个原型,投放市场,然后根据反馈,迅速迭代。而苹果却貌似反其道而行之的,不管是iPod还是iPhone,还是iPad,等它发布的时候,我们都发现它们是成品,直接就是有魔力的产品,有些人会把它们形容为惊艳。
在参加工作三年之后,我逐步找到了一个把产品做出魔力的感觉,尽管还不断的失手,但越来越有自信了。至少有一点,我能保证我做出来的产品,一定是非常流畅的,让人用起来不卡壳,即使这是一个to B的工具产品。这次创业可以自行操刀,更是期望哪怕少做两个功能,也要把它做的有魔力。
因为创业是针对互联网创业公司的,数据规模上肯定和在百度没法比,另外,创业公司没有历史包袱,因此可以在数据源头上去规范起来。做了七年的数据平台,我总结的最重要的一点就是要把数据源处理好,如果源头不好,后面即使用再复杂的算法,也不能做好。我曾经在百度花了一年半的时间,推动公司的核心业务线从打印的各种花样的文本日志,转变成直接打印二进制结构化的,后面的数据处理都变得容易很多。那现在从零开始,就可以直接和创业公司一起,把数据源头规范好,把每一条的用户记录,规范成有多个维度的带有格式的数据,就像数据库里的一条标准记录。再稍加处理,就能形成标准的多维数据源。
在这个多维数据源基础上,进一步规范成多维数据分析模型,搭配上合适的存储和查询引擎,就能实现多种维度的交叉分析,但有在秒级响应。再将常用的事件分析、漏斗转化、留存分析进行抽象,直接建立在这一数据模型之上。我们可能用过各种BI(Business Inteligence,商务智能)系统,见过数百张报表,纷繁复杂。可是针对用户行为分析,在这几个简单功能之上,就能生成五彩缤纷的报表。
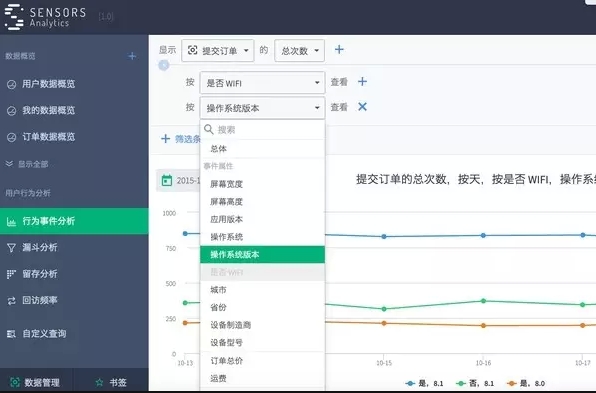
(图3 Sensors Analytics上的多维分析功能截图)
当我向客户介绍我们产品的底层实现时,都会感觉思路特简单。但当用到我们的产品时,又感觉特别强大,又非常易用。可这简单的背后,是花了大量的经历去抽象功能,并打磨细节。有一位GA(Google Analytics)专家,对统计分析工具非常精通,尤其擅长GA。我的两位合伙人和他交流之后,我问他们公司有没有可能用我们的产品,两个人都说不可能,人家都已经有了一套完整的现有方案,可没过两天,发来消息说决定要用我们的产品,我是被惊喜到了。在这创业的短短5个多月,10来个人的团队,产出了20多万行的代码,而我只在开始的一个半月,光界面部分,就提交了100个bug,这样才有了我们的Sensors Analytics 1.0(有兴趣的可以到http://www.sensorsdata.cn/申请试用)。即使现在,我还在每天至少提交一个bug/feature。
我在朋友圈发了那条微博的截图之后,Alex Lv回复说:为什么多维分析易说难做,你一定想明白了。


















