假如你有一个一千列和一百万行的数据集。无论你从哪个角度看它——小型,中型或大型的数据——你不可能看到它的全貌。将它放大或缩小。使它能够在一个屏幕里显示完全。由于人的本质,如果能够看到事物的全局的话,我们就会有更好的理解。有没有办法把数据都放到一张图里,让你可以像观察地图一样观察数据呢?
将深度学习与拓扑数据分析结合在一起完全能够达到此目的,并且还绰绰有余。
1、它能在几分钟内创建一张数据图,其中每一个点都是一个数据项或一组类似的数据项。
基于数据项的相关性和学习模式,系统将类似的数据项组合在一起。这将使数据有唯一的表示方式,并且会让你更清晰地洞察数据。可视化图中的节点由一个或多个数据点构成,而点与点之间的链接则代表数据项之间高相似性。

2、它展示了数据中的模式,这是使用传统商业智能无法识别的。
下面是个案例,展示的是算法是如何仅仅通过分析用户行为来识别两组不同的人群。典型的特征区分,黄色和蓝色点:女性和男性。
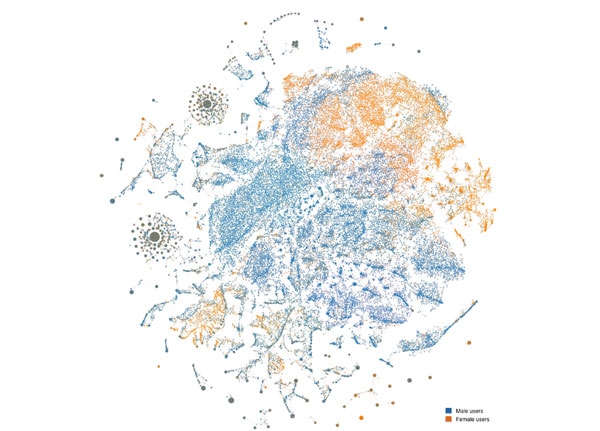
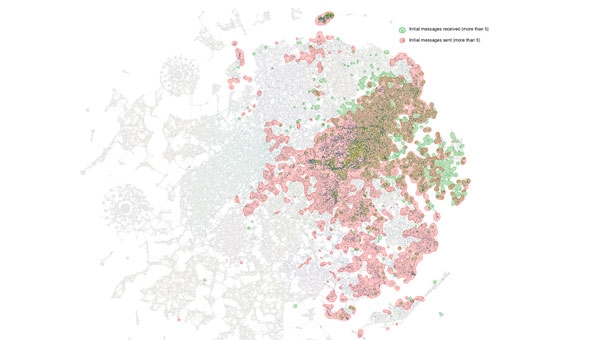
如果我们分析行为类型,我们会发现,其中一组大部分是发送信息(男性),而另一组则多为接收信息(女性)。
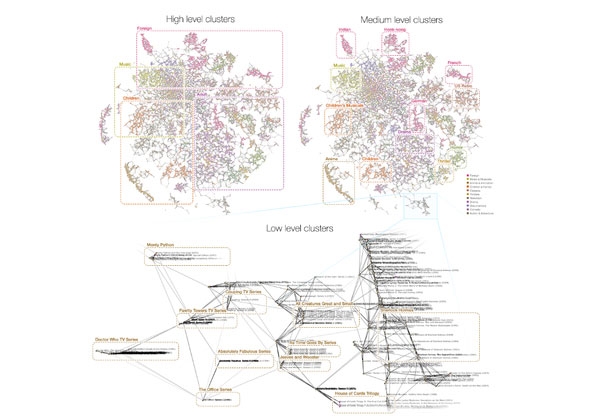
3、它能在多层面上识别分段数据
分段数据表现在多种层面上——从高层次分类到具有相同数据项的分组。
在一个Netflix数据集的例子中,每个数据项是一部电影。最高层次的一组是音乐,孩子,外交和成人电影。中层次的部分包含不同分段:从印度片和港片到惊悚片和恐怖片。在低层次中是电视连续剧分组,比如“万能管家”,“办公室”,“神秘博士”等。
4、它能分析任何数据:文本,图像,传感器数据,甚至音频数据。
任何数据都可以被分段并理解,如果可以将它展现为数字矩阵,其中每一行是一个数据项,列是一个参数。下面这些是最常见的用例:

5、如果你引导它,它能学习更复杂的依赖关系。
选择一组数据项,将它们分组,算法就会发现所有相关或类似的数据项。重复这个过程数次,那么神经网络可以学习到它们之间的差异,比如Mac硬件,PC硬件和一般电子文本的差异。
对20000篇属于20个不同主题的文章进行了初步分析,得出一个密集的点云图(左图)。在使用深度学习迭代几次之后,算法会将它们进行分类,错误率仅仅1.2%(右图)。
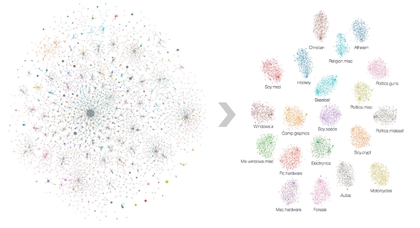
6、即使没有监督它也能够学习
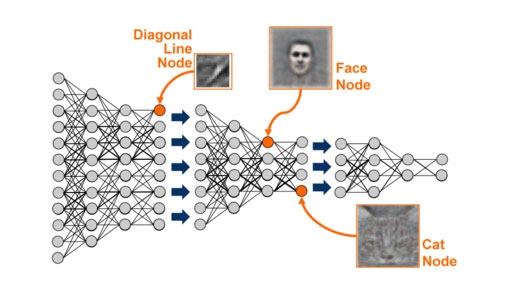
深度学习和自编码器模拟了人类大脑活动,并且能够在数据集中自动识别高层次的模式。例如,在谷歌大脑计划中,自编码器通过“观看”一千万条YouTube视频截取的数字图像,成功地学习并识别出人和猫脸:
我最近在使用拓扑数据分析和深度学习,并开发出一套工具,它将这些技术转换成了一个用户友好型界面,能够让人们观察数据并发现潜在联系。