













一、小数据来自哪里?
科技公司的数据科学、关联性分析以及机器学习等方面的活动大多围绕着”大数据”,这些大型数据集包含文档、 用户、 文件、 查询、 歌曲、 图片等信息,规模数以千计,数十万、 数百万、 甚至数十亿。过去十年里,处理这类型数据集的基础设施、 工具和算法发展得非常迅速,并且得到了不断改善。大多数数据科学家和机器学习从业人员就是在这样的情况下积累了经验,逐渐习惯于那些用着顺手的算法,而且在那些常见的需要权衡的问题上面拥有良好的直觉(经常需要权衡的问题包括:偏差和方差,灵活性和稳定性,手工特性提取和特征学习等等)。但小的数据集仍然时不时的出现,而且伴随的问题往往难以处理,需要一组不同的算法和不同的技能。小数据集出现在以下几种情况:
- 企业解决方案: 当您尝试为一个人员数量相对有限的企业提供解决方案,而不是为成千上万的用户提供单一的解决方案。
- 时间序列: 时间供不应求!尤其是和用户、查询指令、会话、文件等相比较。这显然取决于时间单位或采样率,但是想每次都能有效地增加采样率没那么容易,比如你得到的标定数据是日期的话,那么你每天只有一个数据点。
- 关于以下样本的聚类模型:州市、国家、运动队或任何总体本身是有限的情况(或者采样真的很贵)。【备注:比如对美国50个州做聚类】
- 多变量 A/B 测试: 实验方法或者它们的组合会成为数据点。如果你正在考虑3个维度,每个维度设置4个配置项,那么将拥有12个点。【备注:比如在网页测试中,选择字体颜色、字体大小、字体类型三个维度,然后有四种颜色、四个字号、四个字型】
- 任何罕见现象的模型,例如地震、洪水。
二、小数据问题
小数据问题很多,但主要围绕高方差:
- 很难避免过度拟合
- 你不只过度拟合训练数据,有时还过度拟合验证数据。
- 离群值(异常点)变得更危险。
- 通常,噪声是个现实问题,存在于目标变量中或在一些特征中。
三、如何处理以下情况
1-雇一个统计学家
我不是在开玩笑!统计学家是原始的数据科学家。当数据更难获取时统计学诞生了,因而统计学家非常清楚如何处理小样本问题。统计检验、参数模型、自举法(Bootstrapping,一种重复抽样技术),和其他有用的数学工具属于经典统计的范畴,而不是现代机器学习。如果没有好的专业统计员,您可以雇一个海洋生物学家、动物学家、心理学家或任何一个接受过小样本处理训练的人。当然,他们的专业履历越接近您的领域越好。如果您不想雇一个全职统计员,那么可以请临时顾问。但雇一个科班出身的统计学家可能是非常好的投资。
2-坚持简单模型
更确切地说: 坚持一组有限的假设。预测建模可以看成一个搜索问题。从初始的一批可能模型中,选出那个最适合我们数据的模型。在某种程度上,每一个我们用来拟合的点会投票,给不倾向于产生这个点的模型投反对票,给倾向于产生这个点的模型投赞成票。当你有一大堆数据时,你能有效地在一大堆模型/假设中搜寻,最终找到适合的那个。当你一开始没有那么多的数据点时,你需要从一套相当小的可能的假设开始 (例如,含有 3个非零权重的线性模型,深度小于4的决策树模型,含有十个等间隔容器的直方图)。这意味着你排除复杂的设想,比如说那些非线性或特征之间相互作用的问题。这也意味着,你不能用太多自由度 (太多的权重或参数)拟合模型。适当时,请使用强假设 (例如,非负权重,没有交互作用的特征,特定分布等等) 来缩小可能的假设的范围。
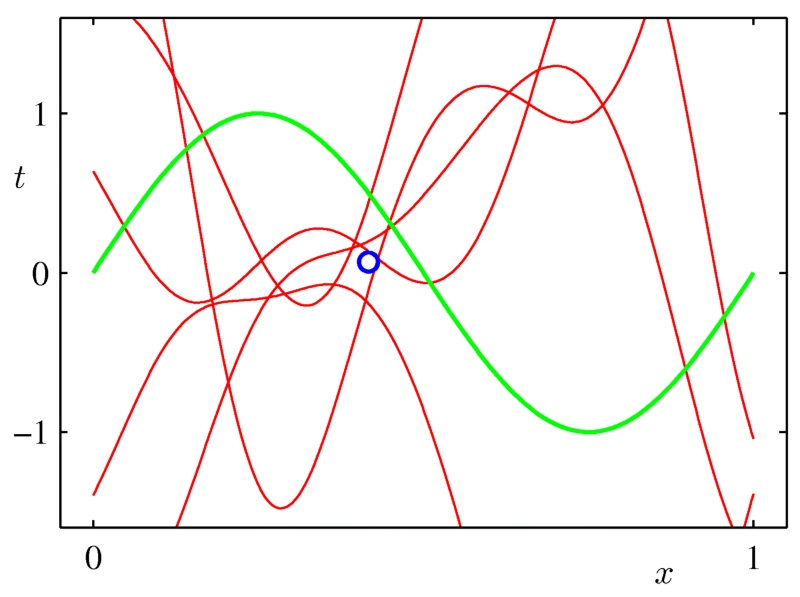
任何疯狂的模型都能拟合单点。
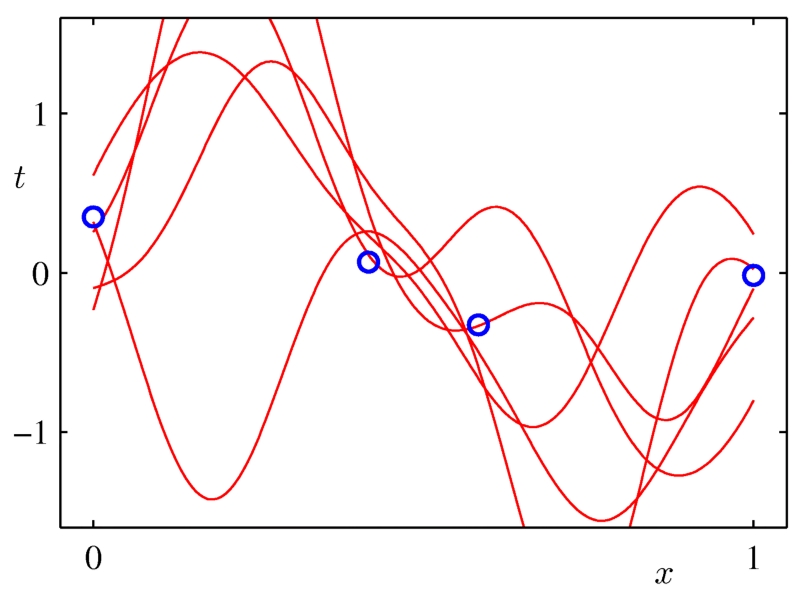
当我们有更多的数据点时,越来越少的模型可以拟合这些点。
图像来自Chris Bishop的书《模式识别和机器学习》
3-尽可能使用更多的数据
您想构建一个个性化的垃圾邮件过滤器吗?尝试构建在一个通用模型,并为所有用户训练这个模型。你正在为某一个国家的GDP建模吗?尝试用你的模型去拟合所有能得到数据的国家,或许可以用重要性抽样来强调你感兴趣的国家。你试图预测特定的火山爆发吗?……你应该知道如何做了。
4-做试验要克制
不要过分使用验证集。如果你尝试过许多不同的技术,并使用一个保留数据集来对比它们,那么你应该清楚这些结果的统计效力如何,而且要意识到对于样本以外的数据它可能不是一个好的模型。
5-清洗您的数据
处理小数据集时,噪声和异常点都特别烦人。为了得到更好的模型,清洗您的数据可能是至关重要的。或者您可以使用鲁棒性更好的模型,尤其针对异常点。(例如分位数回归)
6-进行特征选择
我不是显式特征选择的超级粉丝。我通常选择用正则化和模型平均 (下面会展开讲述)来防止过度拟合。但是,如果数据真的很少,有时显式特征选择至关重要。可以的话,***借助某一领域的专业知识来做特征选择或删减,因为穷举法 (例如所有子集或贪婪前向选择) 一样容易造成过度拟合。
7-使用正则化
对于防止模型过拟合,且在不降低模型中参数实际数目的前提下减少有效自由度,正则化几乎是神奇的解决办法。L1正则化用较少的非零参数构建模型,有效地执行隐式特征选择。而 L2 正则化用更保守 (接近零) 的参数,相当于有效的得到了强零中心的先验参数 (贝叶斯理论)。通常,L2 拥有比L1更好的预测精度。【备注:L2正则化的效果使权重衰减,人们普遍认为:更小的权值从某种意义上说,表示网络的复杂度更低,对数据的拟合刚刚好,这个法则也叫做奥卡姆剃刀。】
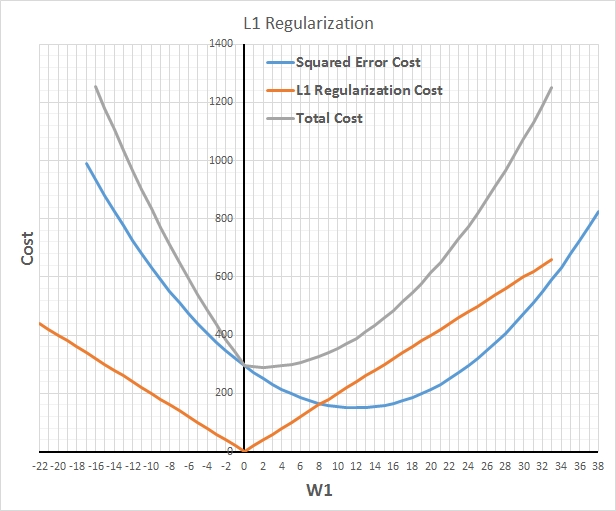
L1正则化可以使得大多数参数变为零
8 使用模型平均
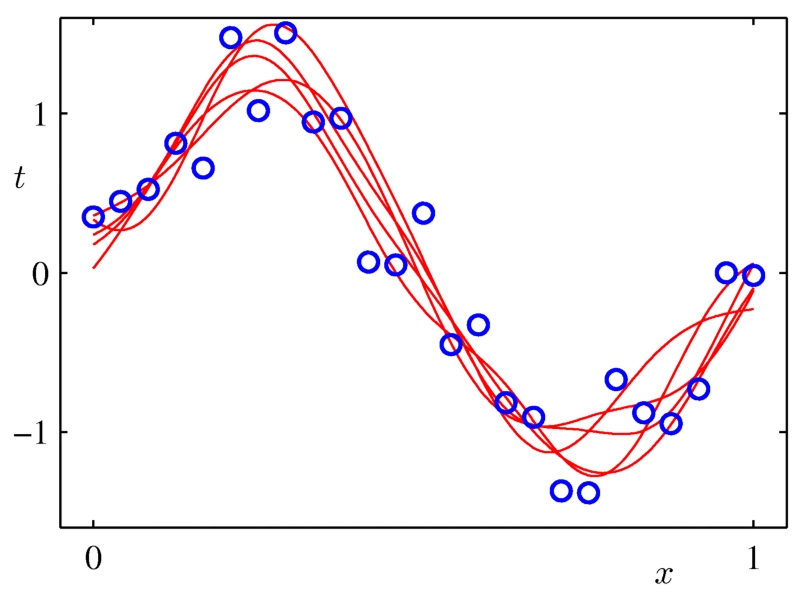
模型平均拥有类似正则化的效果,它减少方差,提高泛化,但它是一个通用的技术,可以在任何类型的模型上甚至在异构模型的集合上使用。缺点是,为了做模型平均,结果要处理一堆模型,模型的评估变得很慢。bagging和贝叶斯模型平均是两个好用的模型平均方法。
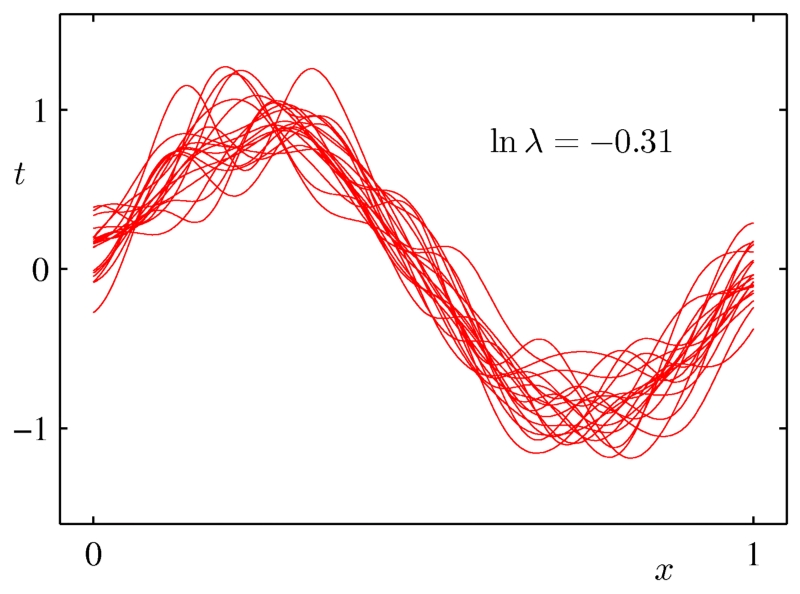
每条红线是一个拟合模型。
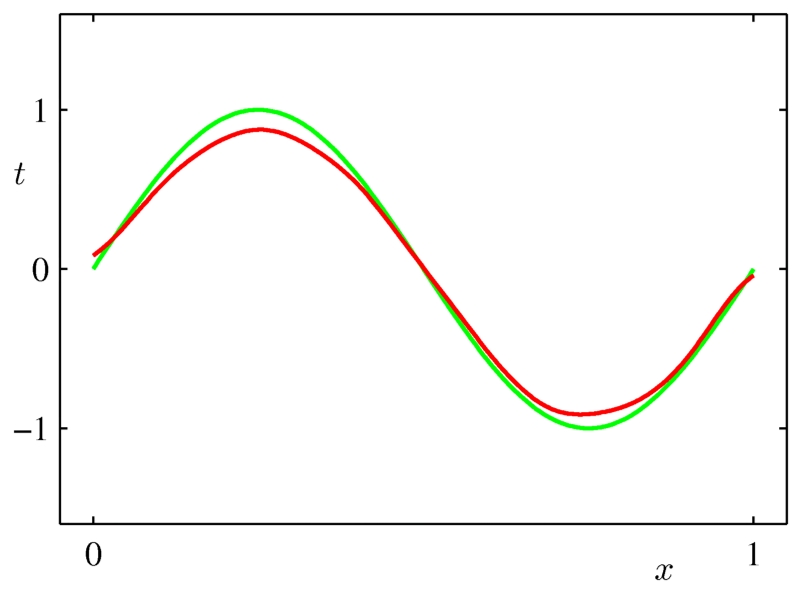
平均这些高方差模型之后,我们得到一个平滑的曲线,它很好的拟合了原有数据点的分布。
9-尝试贝叶斯建模和模型平均
这个依然不是我喜欢的技术,但贝叶斯推理可能适合于处理较小的数据集,尤其是当你能够使用专业知识构造好的先验参数时。
10-喜欢用置信区间
通常,除了构建一个预测模型之外,估计这个模型的置信是个好主意。对于回归分析,它通常是一个以点估计值为中心的取值范围,真实值以95%的置信水平落在这个区间里。如果是分类模型的话,那么涉及的将是分类的概率。这种估计对于小数据集更加重要,因为很有可能模型的某些特征相比其它特征没有更好的表达出来。如上所述的模型平均允许我们很容易得到在回归、 分类和密度估计中做置信的一般方法。当评估您的模型时它也很有用。使用置信区间评估模型性能将助于你避免得出很多错误的结论。
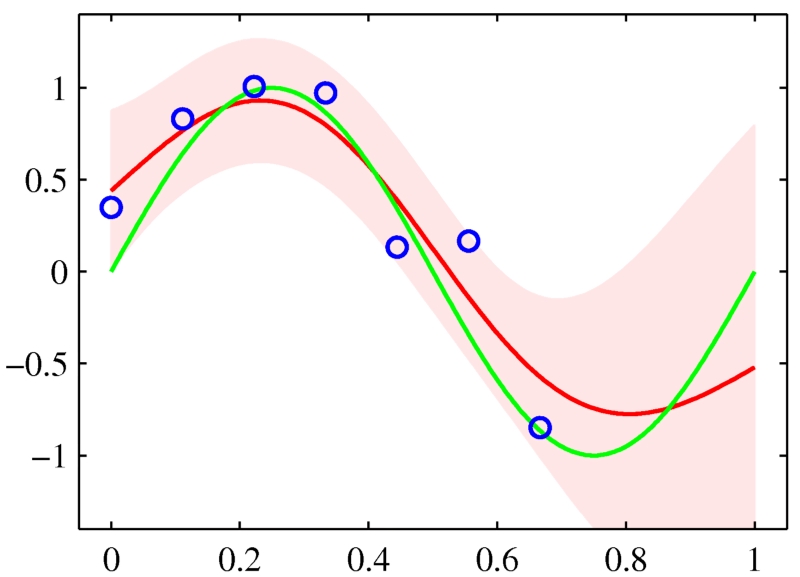
你的数据不乐意出现在特征空间的某些区域,那么预测置信应该有所反应。
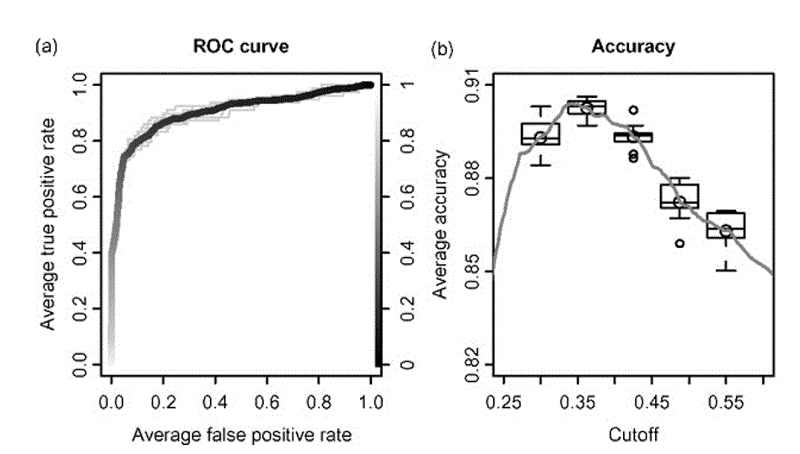
用ROCR得到的自举法性能图。
四、总结
上面讲的有点多,但他们都围绕着三个主题:约束建模,平滑和量化不确定性。这篇文章中所使用的图片来自Christopher Bishop的书《模式识别和机器学习》



















