可选MySQL高可用方案
MySQL的各种高可用方案,大多是基于以下几种基础来部署的:
基于主从复制;
基于Galera协议;
基于NDB引擎;
基于中间件/proxy;
基于共享存储;
基于主机高可用;
在这些可选项中,最常见的就是基于主从复制的方案,其次是基于Galera的方案,我们重点说说这两种方案。其余几种方案在生产上用的并不多,我们只简单说下。
基于主从复制的高可用方案
双节点主从 + keepalived/heartbeat
一般来说,中小型规模的时候,采用这种架构是最省事的。
两个节点可以采用简单的一主一从模式,或者双主模式,并且放置于同一个VLAN中,在master节点发生故障后,利用keepalived/heartbeat的高可用机制实现快速切换到slave节点。
在这个方案里,有几个需要注意的地方:
采用keepalived作为高可用方案时,两个节点***都设置成BACKUP模式,避免因为意外情况下(比如脑裂)相互抢占导致往两个节点写入相同数据而引发冲突;
把两个节点的auto_increment_increment(自增起始值)和auto_increment_offset(自增步长)设成不同值。其目的是为了避免master节点意外宕机时,可能会有部分binlog未能及时复制到slave上被应用,从而会导致slave新写入数据的自增值和原先master上冲突了,因此一开始就使其错开;当然了,如果有合适的容错机制能解决主从自增ID冲突的话,也可以不这么做;
slave节点服务器配置不要太差,否则更容易导致复制延迟。作为热备节点的slave服务器,硬件配置不能低于master节点;
如果对延迟问题很敏感的话,可考虑使用MariaDB分支版本,或者直接上线MySQL 5.7***版本,利用多线程复制的方式可以很大程度降低复制延迟;
对复制延迟特别敏感的另一个备选方案,是采用semi sync replication(就是所谓的半同步复制)或者后面会提到的PXC方案,基本上无延迟,不过事务并发性能会有不小程度的损失,需要综合评估再决定;
keepalived的检测机制需要适当完善,不能仅仅只是检查mysqld进程是否存活,或者MySQL服务端口是否可通,还应该进一步做数据写入或者运算的探测,判断响应时间,如果超过设定的阈值,就可以启动切换机制;
keepalived最终确定进行切换时,还需要判断slave的延迟程度。需要事先定好规则,以便决定在延迟情况下,采取直接切换或等待何种策略。直接切换可能因为复制延迟有些数据无法查询到而重复写入;
keepalived或heartbeat自身都无法解决脑裂的问题,因此在进行服务异常判断时,可以调整判断脚本,通过对第三方节点补充检测来决定是否进行切换,可降低脑裂问题产生的风险。
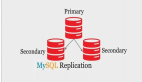
双节点主从+keepalived/heartbeat方案架构示意图见下:
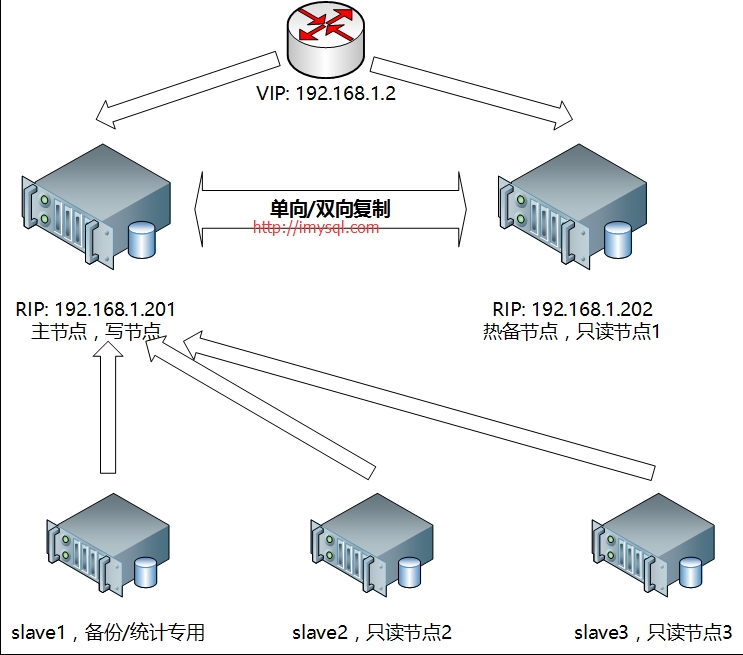
图解:MySQL双节点(单向/双向主从复制),采用keepalived实现高可用架构。
多节点主从+MHA/MMM
多节点主从,可以采用一主多从,或者双主多从的模式。
这种模式下,可以采用MHA或MMM来管理整个集群,目前MHA应用的最多,优先推荐MHA,***的MHA也已支持MySQL 5.6的GTID模式了,是个好消息。
MHA的优势很明显:
开源,用Perl开发,代码结构清晰,二次开发容易;
方案成熟,故障切换时,MHA会做到较严格的判断,尽量减少数据丢失,保证数据一致性;
提供一个通用框架,可根据自己的情况做自定义开发,尤其是判断和切换操作步骤;
支持binlog server,可提高binlog传送效率,进一步减少数据丢失风险。
不过MHA也有些限制:
需要在各个节点间打通ssh信任,这对某些公司安全制度来说是个挑战,因为如果某个节点被黑客攻破的话,其他节点也会跟着遭殃;
自带提供的脚本还需要进一步补充完善,当然了,一般的使用还是够用的。
多节点主从+etcd/zookeeper
在大规模节点环境下,采用keepalived或者MHA作为MySQL的高可用管理还是有些复杂或麻烦。
首先,这么多节点如果没有采用配置服务来管理,必然杂乱无章,线上切换时很容易误操作。
在较大规模环境下,建议采用etcd/zookeeper管理集群,可实现快速检测切换,以及便捷的节点管理。
基于Galera协议的高可用方案
Galera是Codership提供的多主数据同步复制机制,可以实现多个节点间的数据同步复制以及读写,并且可保障数据库的服务高可用及数据一致性。
基于Galera的高可用方案主要有MariaDB Galera Cluster和Percona XtraDB Cluster(简称PXC),目前PXC用的会比较多一些。
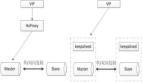
PXC的架构示意图见下:
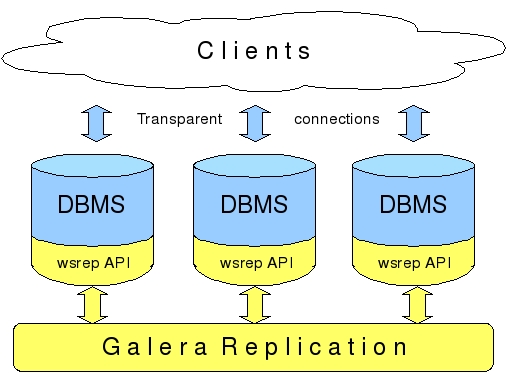
(图片源自网络),图解:在底层采用wsrep接口实现数据在多节点间的同步复制。
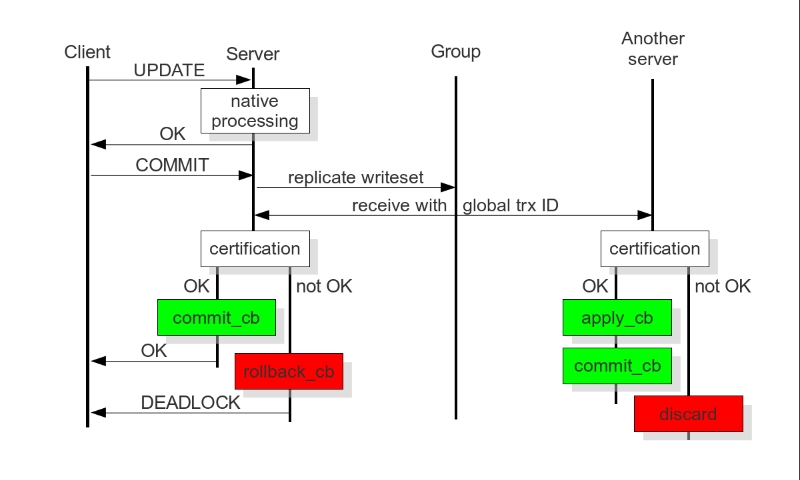
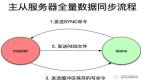
(图片源自网络),图解:在PXC中,一次数据写入在各个节点间的验证/回滚流程。
PXC的优点
服务高可用;
数据同步复制(并发复制),几乎无延迟;
多个可同时读写节点,可实现写扩展,不过***事先进行分库分表,让各个节点分别写不同的表或者库,避免让galera解决数据冲突;
新节点可以自动部署,部署操作简单;
数据严格一致性,尤其适合电商类应用;
完全兼容MySQL;
虽然有这么多好处,但也有些局限性:
只支持InnoDB引擎;
所有表都要有主键;
不支持LOCK TABLE等显式锁操作;
锁冲突、死锁问题相对更多;
不支持XA;
集群吞吐量/性能取决于短板;
新加入节点采用SST时代价高;
存在写扩大问题;
如果并发事务量很大的话,建议采用InfiniBand网络,降低网络延迟;
事实上,采用PXC的主要目的是解决数据的一致性问题,高可用是顺带实现的。因为PXC存在写扩大以及短板效应,并发效率会有较大损失,类似semi sync replication机制。
其他高可用方案
基于NDB Cluster,由于NDB目前仍有不少缺陷和限制,不建议在生产环境上使用;
基于共享存储,一方面需要不太差的存储设备,另外共享存储可也会成为新的单点,除非采用基于高速网络的分布式存储,类似RDS的应用场景,架构方案就更复杂了,成本也可能更高;
基于中间件(Proxy),现在可靠的Proxy选择并不多,而且没有通用的Proxy,都有有所针对,比如有的专注解决读写分离,有的专注分库分表等等,真正好用的Proxy一般要自行开发;
基于主机高可用,是指采用类似RHCS构建一个高可用集群后,再部署MySQL应用的方案。老实说,我没实际用过,但从侧面了解到这种方案生产上用的并不多,可能也有些局限性所致吧;
以DBA们的聪明才智,肯定还有其他我不知道的方案,也欢迎同行们间多多交流。