【引自粗茶淡饭的博客】一、keepalived介绍
1.Keepalived 定义
Keepalived 是一个基于VRRP协议来实现的LVS服务高可用方案,可以利用其来避免单点故障。一个LVS服务会有2台服务器运行Keepalived,一台为主服务器(MASTER),一台为备份服务器(BACKUP),但是对外表现为一个虚拟IP,主服务器会发送特定的消息给备份服务器,当备份服务器收不到这个消息的时候,即主服务器宕机的时候, 备份服务器就会接管虚拟IP,继续提供服务,从而保证了高可用性。Keepalived是VRRP的完美实现,因此在介绍keepalived之前,先介 绍一下VRRP的原理。
2.VRRP 协议简介
在现实的网络环境中,两台需要通信的主机大多数情况下并没有直接的物理连接。对于这样的情况,它们之间路由怎样选择?主机如何选定到达目的主机的下一跳路由,这个问题通常的解决方法有两种:
◆在主机上使用动态路由协议(RIP、OSPF等)
◆在主机上配置静态路由
很明显,在主机上配置动态路由是非常不切实际的,因为管理、维护成本以及是否支持等诸多问题。配置静态路由就变得十分流行,但路由器(或者说默认网关 default gateway)却经常成为单点故障。VRRP的目的就是为了解决静态路由单点故障问题,VRRP通过一竞选(election)协议来动态的将路由任务交给LAN中虚拟路由器中的某台VRRP路由器。
3.VRRP 工作机制
在一个VRRP虚拟路由器中,有多台物理的VRRP路由器,但是这多台的物理的机器并不能同时工作,而是由一台称为MASTER的负责路由工 作,其它的都是BACKUP,MASTER并非一成不变,VRRP让每个VRRP路由器参与竞选,最终获胜的就是MASTER。MASTER拥有一些特 权,比如,拥有虚拟路由器的IP地址,我们的主机就是用这个IP地址作为静态路由的。拥有特权的MASTER要负责转发发送给网关地址的包和响应ARP请 求。
VRRP通过竞选协议来实现虚拟路由器的功能,所有的协议报文都是通过IP多播(multicast)包(多播地址224.0.0.18)形式 发送的。虚拟路由器由VRID(范围0-255)和一组IP地址组成,对外表现为一个周知的MAC地址。所以,在一个虚拟路由器中,不管谁是 MASTER,对外都是相同的MAC和IP(称之为VIP)。客户端主机并不需要因为MASTER的改变而修改自己的路由配置,对客户端来说,这种主从的切换是透明的。
在一个虚拟路由器中,只有作为MASTER的VRRP路由器会一直发送VRRP通告信息(VRRPAdvertisement message),BACKUP不会抢占MASTER,除非它的优先级(priority)更高。当MASTER不可用时(BACKUP收不到通告信息), 多台BACKUP中优先级最高的这台会被抢占为MASTER。这种抢占是非常快速的(<1s),以保证服务的连续性。由于安全性考虑,VRRP包使用了加密协议进行加密。
4.VRRP 工作流程
(1)初始化
路由器启动时,如果路由器的优先级是255(最高优先级,路由器拥有路由器地址),要发送VRRP通告信息,并发送广播ARP信息通告路由器 IP地址对应的MAC地址为路由虚拟MAC,设置通告信息定时器准备定时发送VRRP通告信息,转为MASTER状态;否则进入BACKUP状态,设置定 时器检查定时检查是否收到MASTER的通告信息。
(2)Master
◆设置定时通告定时器;
◆用VRRP虚拟MAC地址响应路由器IP地址的ARP请求;
◆转发目的MAC是VRRP虚拟MAC的数据包;
◆如果是虚拟路由器IP的拥有者,将接受目的地址是虚拟路由器IP的数据包,否则丢弃;
◆当收到shutdown的事件时删除定时通告定时器,发送优先权级为0的通告包,转初始化状态;
◆如果定时通告定时器超时时,发送VRRP通告信息;
◆收到VRRP通告信息时,如果优先权为0,发送VRRP通告信息;否则判断数据的优先级是否高于本机,或相等而且实际IP地址大于本地实际IP,设置定时通告定时器,复位主机超时定时器,转BACKUP状态;否则的话,丢弃该通告包。
(3)Backup
◆设置主机超时定时器;
◆不能响应针对虚拟路由器IP的ARP请求信息;
◆丢弃所有目的MAC地址是虚拟路由器MAC地址的数据包;
◆不接受目的是虚拟路由器IP的所有数据包;
◆当收到shutdown的事件时删除主机超时定时器,转初始化状态;
◆主机超时定时器超时的时候,发送VRRP通告信息,广播ARP地址信息,转MASTER状态;
◆收到VRRP通告信息时,如果优先权为0,表示进入MASTER选举;否则判断数据的优先级是否高于本机,如果高的话承认MASTER有效,复位主机超时定时器;否则的话,丢弃该通告包。
5.ARP查询处理
当内部主机通过ARP查询虚拟路由器IP地址对应的MAC地址时,MASTER路由器回复的MAC地址为虚拟的VRRP的MAC地址,而不是实际网卡的 MAC地址,这样在路由器切换时让内网机器觉察不到;而在路由器重新启动时,不能主动发送本机网卡的实际MAC地址。如果虚拟路由器开启的ARP代理 (proxy_arp)功能,代理的ARP回应也回应VRRP虚拟MAC地址;好了VRRP的简单讲解就到这里,我们下来讲解一下Keepalived的案例。
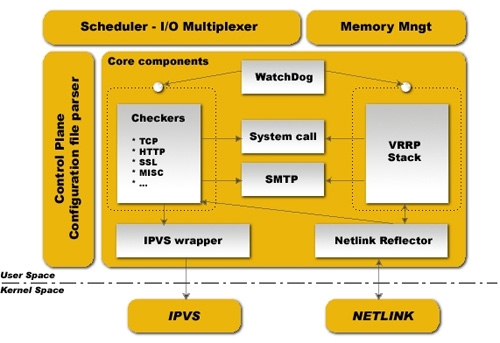
6.keepalived组成
keepalived主要有三个模块,分别是core、check和vrrp。core模块为keepalived的核心,负责主进程的启动、维护以及全局配置文件的加载和解析。check负责健康检查,包括常见的各种检查方式。vrrp模块是来实现VRRP协议的。
#p#
二、keepalived的配置文件说明
keepalived只有一个配置文件keepalived.conf,里面主要包括以下几个配置区域,分别是global_defs、 static_ipaddress、static_routes、vrrp_script、vrrp_instance和virtual_server。
1.global_defs区域
主要是配置故障发生时的通知对象以及机器标识。
- global_defs {
- notification_email {
- acassen@firewall.loc
- failover@firewall.loc
- sysadmin@firewall.loc
- }
- notification_email_from Alexandre.Cassen@firewall.loc
- smtp_server 192.168.200.1
- smtp_connect_timeout 30
- enable_traps
- router_id LVS_DEVEL
- }
◆notification_email 故障发生时,给谁发邮件通知。
◆notification_email_from 通知邮件从哪个地址发出。
◆smpt_server 通知邮件的smtp地址。
◆smtp_connect_timeout 连接smtp服务器的超时时间。
◆enable_traps 开启SNMP陷阱(Simple Network Management Protocol)。
◆router_id 标识本节点的字条串,通常为hostname,但不一定非得是hostname。故障发生时,邮件通知会用到。
2.vrrp_script区域
用来做健康检查的,当时检查失败时会将vrrp_instance的priority减少相应的值。
- vrrp_script chk_http_port {
- script "</dev/tcp/127.0.0.1/80"
- interval 1
- weight -10
- }
以上意思是如果script中的指令执行失败,那么相应的vrrp_instance的优先级会减少10个点。
3.vrrp_instance和vrrp_sync_group区域
vrrp_instance用来定义对外提供服务的VIP区域及其相关属性。 vrrp_rsync_group用来定义vrrp_intance组,使得这个组内成员动作一致。举个例子来说明一下其功能: 两个vrrp_instance同属于一个vrrp_rsync_group,那么其中一个vrrp_instance发生故障切换时,另一个vrrp_instance也会跟着切换(即使这个instance没有发生故障)。
- vrrp_sync_group VG_1 {
- group {
- inside_network # name of vrrp_instance (below)
- outside_network # One for each moveable IP.
- ...
- }
- notify_master /path/to_master.sh
- notify_backup /path/to_backup.sh
- notify_fault "/path/fault.sh VG_1"
- notify /path/notify.sh
- smtp_alert
- }
- vrrp_instance VI_1 {
- state MASTER
- interface eth0
- use_vmac <VMAC_INTERFACE>
- dont_track_primary
- track_interface {
- eth0
- eth1
- }
- mcast_src_ip <IPADDR>
- lvs_sync_daemon_interface eth1
- garp_master_delay 10
- virtual_router_id 1
- priority 100
- advert_int 1
- authentication {
- auth_type PASS
- auth_pass 12345678
- }
- virtual_ipaddress {
- 10.210.214.253/24 brd 10.210.214.255 dev eth0
- 192.168.1.11/24 brd 192.168.1.255 dev eth1
- }
- virtual_routes {
- 172.16.0.0/12 via 10.210.214.1
- 192.168.1.0/24 via 192.168.1.1 dev eth1
- default via 202.102.152.1
- }
- track_script {
- chk_http_port
- }
- nopreempt
- preempt_delay 300
- debug
- notify_master <STRING>|<QUOTED-STRING>
- notify_backup <STRING>|<QUOTED-STRING>
- notify_fault <STRING>|<QUOTED-STRING>
- notify <STRING>|<QUOTED-STRING>
- smtp_alert
- }
◆notify_master/backup/fault 分别表示切换为主/备/出错时所执行的脚本。
◆notify 表示任何一状态切换时都会调用该脚本,并且该脚本在以上三个脚本执行完成之后进行调用,keepalived会自动传递三个参数($1 = "GROUP"|"INSTANCE",$2 = name of group or instance,$3 = target state of transition(MASTER/BACKUP/FAULT))。
◆smtp_alert 表示是否开启邮件通知(用全局区域的邮件设置来发通知)。
◆state 可以是MASTER或BACKUP,不过当其他节点keepalived启动时会将priority比较大的节点选举为MASTER,因此该项其实没有实质用途。
◆interface 节点固有IP(非VIP)的网卡,用来发VRRP包。
◆use_vmac 是否使用VRRP的虚拟MAC地址。
◆dont_track_primary 忽略VRRP网卡错误。(默认未设置)
◆track_interface 监控以下网卡,如果任何一个不通就会切换到FALT状态。(可选项)
◆mcast_src_ip 修改vrrp组播包的源地址,默认源地址为master的IP。(由于是组播,因此即使修改了源地址,该master还是能收到回应的)
◆lvs_sync_daemon_interface 绑定lvs syncd的网卡。
◆garp_master_delay 当切为主状态后多久更新ARP缓存,默认5秒。
◆virtual_router_id 取值在0-255之间,用来区分多个instance的VRRP组播。注意: 同一网段中virtual_router_id的值不能重复,否则会出错。
◆priority 用来选举master的,要成为master,那么这个选项的值最好高于其他机器50个点,该项取值范围是1-255(在此范围之外会被识别成默认值100)。
◆advert_int 发VRRP包的时间间隔,即多久进行一次master选举(可以认为是健康查检时间间隔)。
◆authentication 认证区域,认证类型有PASS和HA(IPSEC),推荐使用PASS(密码只识别前8位)。
◆virtual_ipaddress vip,不解释了。
◆virtual_routes 虚拟路由,当IP漂过来之后需要添加的路由信息。
◆virtual_ipaddress_excluded 发送的VRRP包里不包含的IP地址,为减少回应VRRP包的个数。在网卡上绑定的IP地址比较多的时候用。
◆nopreempt 允许一个priority比较低的节点作为master,即使有priority更高的节点启动。首先nopreemt必须在state为BACKUP的 节点上才生效(因为是BACKUP节点决定是否来成为MASTER的),其次要实现类似于关闭auto failback的功能需要将所有节点的state都设置为BACKUP,或者将master节点的priority设置的比BACKUP低。我个人推荐 使用将所有节点的state都设置成BACKUP并且都加上nopreempt选项,这样就完成了关于autofailback功能,当想手动将某节点切 换为MASTER时只需去掉该节点的nopreempt选项并且将priority改的比其他节点大,然后重新加载配置文件即可(等MASTER切过来之 后再将配置文件改回去再reload一下)。 当使用track_script时可以不用加nopreempt,只需要加上preempt_delay 5,这里的间隔时间要大于vrrp_script中定义的时长。
◆preempt_delay master启动多久之后进行接管资源(VIP/Route信息等),并提是没有nopreempt选项。
#p#
4.virtual_server_group和virtual_server区域
- virtual_server IP Port {
- delay_loop <INT>
- lb_algo rr|wrr|lc|wlc|lblc|sh|dh
- lb_kind NAT|DR|TUN
- persistence_timeout <INT>
- persistence_granularity <NETMASK>
- protocol TCP
- ha_suspend
- virtualhost <STRING>
- alpha
- omega
- quorum <INT>
- hysteresis <INT>
- quorum_up <STRING>|<QUOTED-STRING>
- quorum_down <STRING>|<QUOTED-STRING>
- sorry_server <IPADDR> <PORT>
- real_server <IPADDR> <PORT> {
- weight <INT>
- inhibit_on_failure
- notify_up <STRING>|<QUOTED-STRING>
- notify_down <STRING>|<QUOTED-STRING>
- # HTTP_GET|SSL_GET|TCP_CHECK|SMTP_CHECK|MISC_CHECK
- HTTP_GET|SSL_GET {
- url {
- path <STRING>
- # Digest computed with genhash
- digest <STRING>
- status_code <INT>
- }
- connect_port <PORT>
- connect_timeout <INT>
- nb_get_retry <INT>
- delay_before_retry <INT>
- }
- }
- }
◆delay_loop 延迟轮询时间(单位秒)。
◆lb_algo 后端调试算法(load balancing algorithm)。
◆lb_kind LVS调度类型NAT/DR/TUN。
◆virtualhost 用来给HTTP_GET和SSL_GET配置请求header的。
◆sorry_server 当所有real server宕掉时,sorry server顶替。
◆real_server 真正提供服务的服务器。
◆weight 权重。
◆notify_up/down 当real server宕掉或启动时执行的脚本。
◆健康检查的方式,N多种方式。
◆path 请求real serserver上的路径。
◆digest/status_code 分别表示用genhash算出的结果和http状态码。
◆connect_port 健康检查,如果端口通则认为服务器正常。
◆connect_timeout,nb_get_retry,delay_before_retry分别表示超时时长、重试次数,下次重试的时间延迟。
三、keepalived+lvs环境搭建
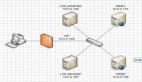
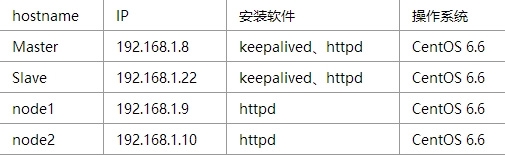
1.环境介绍
2.同步时间
- [root@Master ~]# ntpdate 202.120.2.101
- [root@Slave ~]# ntpdate 202.120.2.101
- [root@node1 ~]# ntpdate 202.120.2.101
- [root@node2 ~]# ntpdate 202.120.2.101
3.realserver安装httpd服务及提供测试页
- [root@node1 ~]# rpm -q httpd
- httpd-2.2.15-45.el6.centos.x86_64
- [root@node1 ~]# cat /www/a.com/htdoc/index.html
- <h1>This is node1 !</h1>
- [root@node2 ~]# rpm -q httpd
- httpd-2.2.15-45.el6.centos.x86_64
- [root@node2 ~]# cat /www/a.com/htdoc/index.html
- <h1>This is node2 !</h1>
4.各realserver启动httpd并测试
- [root@node1 ~]# service httpd start
- [root@node2 ~]# service httpd start
- [root@Master ~]# curl http://192.168.1.9
- <h1>This is node1 !</h1>
- [root@Master ~]# curl http://192.168.1.10
- <h1>This is node2 !</h1>
5.配置node1节点
- [root@node1 ~]# vim realserver.sh
- #!/bin/bash
- #
- # Script to start LVS DR real server.
- # description: LVS DR real server
- #
- . /etc/rc.d/init.d/functions
- VIP=192.168.1.88 #修改你的VIP
- host=`/bin/hostname`
- case "$1" in
- start)
- # Start LVS-DR real server on this machine.
- /sbin/ifconfig lo down
- /sbin/ifconfig lo up
- echo 1 > /proc/sys/net/ipv4/conf/lo/arp_ignore
- echo 2 > /proc/sys/net/ipv4/conf/lo/arp_announce
- echo 1 > /proc/sys/net/ipv4/conf/all/arp_ignore
- echo 2 > /proc/sys/net/ipv4/conf/all/arp_announce
- /sbin/ifconfig lo:0 $VIP broadcast $VIP netmask 255.255.255.255 up
- /sbin/route add -host $VIP dev lo:0
- ;;
- stop)
- # Stop LVS-DR real server loopback device(s).
- /sbin/ifconfig lo:0 down
- echo 0 > /proc/sys/net/ipv4/conf/lo/arp_ignore
- echo 0 > /proc/sys/net/ipv4/conf/lo/arp_announce
- echo 0 > /proc/sys/net/ipv4/conf/all/arp_ignore
- echo 0 > /proc/sys/net/ipv4/conf/all/arp_announce
- ;;
- status)
- # Status of LVS-DR real server.
- islothere=`/sbin/ifconfig lo:0 | grep $VIP`
- isrothere=`netstat -rn | grep "lo:0" | grep $VIP`
- if [ ! "$islothere" -o ! "isrothere" ];then
- # Either the route or the lo:0 device
- # not found.
- echo "LVS-DR real server Stopped."
- else
- echo "LVS-DR real server Running."
- fi
- ;;
- *)
- # Invalid entry.
- echo "$0: Usage: $0 {start|status|stop}"
- exit 1
- ;;
- esac
- [root@node1 ~]# chmod +x realserver.sh
- [root@node1 ~]# ./realserver.sh start
查看脚本是否执行成功:
- [root@node1 ~]# ifconfig
- eth0 Link encap:Ethernet HWaddr 00:0C:29:FE:B8:0D
- inet addr:192.168.1.9 Bcast:192.168.1.255 Mask:255.255.255.0
- inet6 addr: fe80::20c:29ff:fefe:b80d/64 Scope:Link
- UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
- RX packets:15783 errors:0 dropped:0 overruns:0 frame:0
- TX packets:4866 errors:0 dropped:0 overruns:0 carrier:0
- collisions:0 txqueuelen:1000
- RX bytes:1396596 (1.3 MiB) TX bytes:724790 (707.8 KiB)
- lo Link encap:Local Loopback
- inet addr:127.0.0.1 Mask:255.0.0.0
- inet6 addr: ::1/128 Scope:Host
- UP LOOPBACK RUNNING MTU:65536 Metric:1
- RX packets:0 errors:0 dropped:0 overruns:0 frame:0
- TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
- collisions:0 txqueuelen:0
- RX bytes:0 (0.0 b) TX bytes:0 (0.0 b)
- lo:0 Link encap:Local Loopback
- inet addr:192.168.1.88 Mask:255.255.255.255
- UP LOOPBACK RUNNING MTU:65536 Metric:1
#p#
6.配置node2
- [root@node1 ~]# ifconfig
- eth0 Link encap:Ethernet HWaddr 00:0C:29:FE:B8:0D
- inet addr:192.168.1.9 Bcast:192.168.1.255 Mask:255.255.255.0
- inet6 addr: fe80::20c:29ff:fefe:b80d/64 Scope:Link
- UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
- RX packets:15783 errors:0 dropped:0 overruns:0 frame:0
- TX packets:4866 errors:0 dropped:0 overruns:0 carrier:0
- collisions:0 txqueuelen:1000
- RX bytes:1396596 (1.3 MiB) TX bytes:724790 (707.8 KiB)
- lo Link encap:Local Loopback
- inet addr:127.0.0.1 Mask:255.0.0.0
- inet6 addr: ::1/128 Scope:Host
- UP LOOPBACK RUNNING MTU:65536 Metric:1
- RX packets:0 errors:0 dropped:0 overruns:0 frame:0
- TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
- collisions:0 txqueuelen:0
- RX bytes:0 (0.0 b) TX bytes:0 (0.0 b)
- lo:0 Link encap:Local Loopback
- inet addr:192.168.1.88 Mask:255.255.255.255
- UP LOOPBACK RUNNING MTU:65536 Metric:1
现在已经将realserver给配置好了,下面就是配置master与slave。
7.安装keepalived、ipvsadm
- [root@Master ~]# yum install -y keepalived ipvsadm
- [root@Slave ~]# yum install -y keepalived ipvsadm
8.修改Master配置文件并启动服务
- [root@Master ~]# cat /etc/keepalived/keepalived.conf
- ! Configuration File for keepalived
- global_defs {
- notification_email {
- XXXXXXXXX@126.com
- }
- notification_email_from Master
- smtp_server 127.0.0.1
- smtp_connect_timeout 30
- router_id LVS_DEVEL
- }
- vrrp_instance VI_1 {
- state MASTER
- interface eth0
- virtual_router_id 51
- priority 101
- advert_int 1
- authentication {
- auth_type PASS
- auth_pass 1111
- }
- virtual_ipaddress {
- 192.168.1.88
- }
- }
- virtual_server 192.168.1.88 80 {
- delay_loop 6
- lb_algo rr
- lb_kind DR
- nat_mask 255.255.255.0
- #persistence_timeout 50
- protocol TCP
- real_server 192.168.1.9 80 {
- weight 1
- HTTP_GET {
- url {
- path /
- status_code 200
- }
- connect_timeout 2
- nb_get_retry 3
- delay_before_retry 1
- }
- }
- real_server 192.168.1.10 80 {
- weight 1
- HTTP_GET {
- url {
- path /
- status_code 200
- }
- connect_timeout 2
- nb_get_retry 3
- delay_before_retry 1
- }
- }
- }
- [root@Master ~]# service keepalived start
- 正在启动 keepalived: [确定]
- [root@Master ~]# ipvsadm -L -n
- IP Virtual Server version 1.2.1 (size=4096)
- Prot LocalAddress:Port Scheduler Flags
- -> RemoteAddress:Port Forward Weight ActiveConn InActConn
- TCP 192.168.1.88:80 rr
- -> 192.168.1.9:80 Route 1 0 0
- -> 192.168.1.10:80 Route 1 0 0
9.为Slave修改配置文件并启动服务
- [root@Slave ~]# cat /etc/keepalived/keepalived.conf
- ! Configuration File for keepalived
- global_defs {
- notification_email {
- XXXXXXXX@126.com
- }
- notification_email_from Slave
- smtp_server 127.0.0.1
- smtp_connect_timeout 30
- router_id LVS_DEVEL
- }
- vrrp_instance VI_1 {
- state BACKUP
- interface eth0
- virtual_router_id 51
- priority 100
- advert_int 1
- authentication {
- auth_type PASS
- auth_pass 1111
- }
- virtual_ipaddress {
- 192.168.1.88
- }
- }
- virtual_server 192.168.1.88 80 {
- delay_loop 6
- lb_algo rr
- lb_kind DR
- nat_mask 255.255.255.0
- #persistence_timeout 50
- protocol TCP
- real_server 192.168.1.9 80 {
- weight 1
- HTTP_GET {
- url {
- path /
- status_code 200
- }
- connect_timeout 2
- nb_get_retry 3
- delay_before_retry 1
- }
- }
- real_server 192.168.1.10 80 {
- weight 1
- HTTP_GET {
- url {
- path /
- status_code 200
- }
- connect_timeout 2
- nb_get_retry 3
- delay_before_retry 1
- }
- }
- }
- [root@Slave ~]# service keepalived start
- 正在启动 keepalived: [确定]
- [root@Slave ~]# ipvsadm -L -n
- IP Virtual Server version 1.2.1 (size=4096)
- Prot LocalAddress:Port Scheduler Flags
- -> RemoteAddress:Port Forward Weight ActiveConn InActConn
- TCP 192.168.1.88:80 rr
- -> 192.168.1.9:80 Route 1 0 0
- -> 192.168.1.10:80 Route 1 0 0
#p#
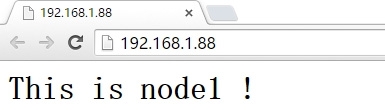
10.浏览器测试
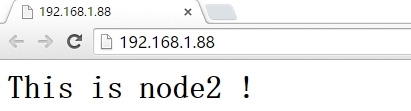
11.模拟realserver故障
停止node1:
- [root@node1 ~]# service httpd stop
- 停止 httpd: [确定]
- 查看lvs:
- [root@Master ~]# ipvsadm -L -n
- IP Virtual Server version 1.2.1 (size=4096)
- Prot LocalAddress:Port Scheduler Flags
- -> RemoteAddress:Port Forward Weight ActiveConn InActConn
- TCP 192.168.1.88:80 rr
- -> 192.168.1.10:80 Route 1 0 0
浏览器查看:
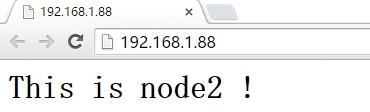
收到下线邮件:
![]()
node1上线:
- [root@node1 ~]# service httpd start
- 正在启动 httpd: [确定]
- 查看lvs:
- [root@Master ~]# ipvsadm -L -n
- IP Virtual Server version 1.2.1 (size=4096)
- Prot LocalAddress:Port Scheduler Flags
- -> RemoteAddress:Port Forward Weight ActiveConn InActConn
- TCP 192.168.1.88:80 rr
- -> 192.168.1.9:80 Route 1 0 0
- -> 192.168.1.10:80 Route 1 0 0
收到上线邮件:
![]()
12.模拟keepalived节点故障
将Master的 keepalived服务停止:
- [root@Master ~]# service keepalived stop
- 停止 keepalived: [确定]
查看lvs:
- [root@Master ~]# ipvsadm -L -n
- IP Virtual Server version 1.2.1 (size=4096)
- Prot LocalAddress:Port Scheduler Flags
- -> RemoteAddress:Port Forward Weight ActiveConn InActConn
- 在Slave查看lvs:
- [root@Slave ~]# ipvsadm -L -n
- IP Virtual Server version 1.2.1 (size=4096)
- Prot LocalAddress:Port Scheduler Flags
- -> RemoteAddress:Port Forward Weight ActiveConn InActConn
- TCP 192.168.1.88:80 rr
- -> 192.168.1.9:80 Route 1 0 0
- -> 192.168.1.10:80 Route 1 0 0
浏览器查看,发现服务没有停止:
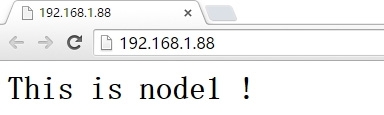
大家可以看到,经过上面的演示我们现在LVS的高可用即前端负载均衡的高可用,同时实现对后端realserver监控,也实现后端realserver宕机时会给管理员发送邮件。但还有几个问题我们还没有解决,问题如下:
◆所有realserver都down机,怎么处理?是不是用户就没法打开,还是提供一下维护页面。
◆怎么完成维护模式keepalived切换?
◆如何在keepalived故障时,发送警告邮件给指定的管理员?
#p#
13.为各keepalived提供错误页面
当我们的所以realserver全部都挂掉以后可以在前端的访问入口,即keepalived+lvs机器上提供个错误提示页,这样做对用户有很好的印象,不会是干巴巴的5XX。
先给Master、Slave安装http服务及提供错误页:
- [root@Master ~]# rpm -q httpd
- httpd-2.2.15-45.el6.centos.x86_64
- [root@Master ~]# cat /www/a.com/htdoc/index.html
- <h1>Website is currently under maintenance, please come back later!</h1>
- [root@Slave ~]# rpm -q httpd
- httpd-2.2.15-47.el6.centos.i686
- [root@Slave ~]# cat /var/www/html/index.html
- <h1>Website is currently under maintenance, please come back later!</h1>
启动httpd服务并测试是否能访问:
- [root@Master ~]# service httpd start
- [root@Slave ~]# service httpd start
- [root@node1 ~]# curl http://192.168.1.8
- <h1>Website is currently under maintenance, please come back later!</h1>
- [root@node1 ~]# curl http://192.168.1.22
- <h1>Website is currently under maintenance, please come back later!</h1>
修改Master配置文件:
- [root@Master ~]# cat /etc/keepalived/keepalived.conf
- ! Configuration File for keepalived
- global_defs {
- notification_email {
- XXXXXXXXX@126.com
- }
- notification_email_from Master
- smtp_server 127.0.0.1
- smtp_connect_timeout 30
- router_id LVS_DEVEL
- }
- vrrp_instance VI_1 {
- state MASTER
- interface eth0
- virtual_router_id 51
- priority 101
- advert_int 1
- authentication {
- auth_type PASS
- auth_pass 1111
- }
- virtual_ipaddress {
- 192.168.1.88
- }
- }
- virtual_server 192.168.1.88 80 {
- delay_loop 6
- lb_algo rr
- lb_kind DR
- nat_mask 255.255.255.0
- #persistence_timeout 50
- protocol TCP
- real_server 192.168.1.9 80 {
- weight 1
- HTTP_GET {
- url {
- path /
- status_code 200
- }
- connect_timeout 2
- nb_get_retry 3
- delay_before_retry 1
- }
- }
- real_server 192.168.1.10 80 {
- weight 1
- HTTP_GET {
- url {
- path /
- status_code 200
- }
- connect_timeout 2
- nb_get_retry 3
- delay_before_retry 1
- }
- }
- sorry_server 127.0.0.1 80 #增加一行sorry_server
- }
修改Slave配置文件:
把上面添加的内容sorry_server 127.0.0.1 80,放在Slave的keepalived配置文件相同的位置。
关闭所有的real server并重新启动一下master与slave的keepalived:
- [root@node1 ~]# service httpd stop
- [root@node2 ~]# service httpd stop
- [root@Master ~]# service keepalived restart
- [root@Slave ~]# service keepalived restart
查看lvs:
- [root@Slave ~]# ipvsadm -L -n
- IP Virtual Server version 1.2.1 (size=4096)
- Prot LocalAddress:Port Scheduler Flags
- -> RemoteAddress:Port Forward Weight ActiveConn InActConn
- TCP 192.168.1.88:80 rr
- -> 127.0.0.1:80 Local 1 0 0
浏览器测试:

14.为Master和Slave提供状态检测
我们一般进行主从切换测试时都是关闭keepalived或关闭网卡接口,有没有一种方法能实现在不关闭keepalived下或网卡接口来实现维护呢?方法肯定是有的,在keepalived新版本中,支持脚本vrrp_srcipt。
定义脚本说明:
- vrrp_srcipt chk_schedown { #定义vrrp执行脚本
- script "[ -e /etc/keepalived/down ] && exit 1 || exit 0" #查看是否有down文件,有就进入维护模式
- interval 1 #监控间隔
- weight -5 #减小优先级
- fall 2 #监控失败次数
- rise 1 #监控成功次数
- }
执行脚本:
- track_script {
- chk_schedown #执行chk_schedown脚本
- }
修改Master配置文件:
- [root@Master ~]# cat /etc/keepalived/keepalived.conf
- ! Configuration File for keepalived
- global_defs {
- notification_email {
- XXXXXXXXX@126.com
- }
- notification_email_from Master
- smtp_server 127.0.0.1
- smtp_connect_timeout 30
- router_id LVS_DEVEL
- }
- vrrp_script chk_schedown {
- script "[ -e /etc/keepalived/down ] && exit 1 || exit 0"
- interval 1
- weight -5
- fall 2
- rise 1
- }
- vrrp_instance VI_1 {
- state MASTER
- interface eth0
- virtual_router_id 51
- priority 101
- advert_int 1
- authentication {
- auth_type PASS
- auth_pass 1111
- }
- virtual_ipaddress {
- 192.168.1.88
- }
- track_script {
- chk_schedown
- }
- }
- virtual_server 192.168.1.88 80 {
- delay_loop 6
- lb_algo rr
- lb_kind DR
- nat_mask 255.255.255.0
- #persistence_timeout 50
- protocol TCP
- real_server 192.168.1.9 80 {
- weight 1
- HTTP_GET {
- url {
- path /
- status_code 200
- }
- connect_timeout 2
- nb_get_retry 3
- delay_before_retry 1
- }
- }
- real_server 192.168.1.10 80 {
- weight 1
- HTTP_GET {
- url {
- path /
- status_code 200
- }
- connect_timeout 2
- nb_get_retry 3
- delay_before_retry 1
- }
- }
- sorry_server 127.0.0.1 80
- }
#p#
Slave上的配置文件在相同的位置也添加上面两项内容:vrrp_script chk_schedown和track_script。
测试:
- [root@Master ~]# touch /etc/keepalived/down
查看日志:
- [root@Master ~]# tail -f /var/log/messages
- Sep 11 20:12:27 Master Keepalived_vrrp[2019]: VRRP_Script(chk_schedown) failed
- Sep 11 20:12:28 Master Keepalived_vrrp[2019]: VRRP_Instance(VI_1) Received higher prio advert
- Sep 11 20:12:28 Master Keepalived_vrrp[2019]: VRRP_Instance(VI_1) Entering BACKUP STATE
- Sep 11 20:12:28 Master Keepalived_vrrp[2019]: VRRP_Instance(VI_1) removing protocol VIPs.
- Sep 11 20:12:28 Master Keepalived_healthcheckers[2018]: Netlink reflector reports IP 192.168.1.88 removed
查看VIP是否转移:
- [root@Master ~]# ip addr show
- 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN
- link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
- inet 127.0.0.1/8 scope host lo
- inet6 ::1/128 scope host
- valid_lft forever preferred_lft forever
- 2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
- link/ether 00:0c:29:b0:04:27 brd ff:ff:ff:ff:ff:ff
- inet 192.168.1.8/24 brd 192.168.1.255 scope global eth0
- inet6 fe80::20c:29ff:feb0:427/64 scope link
- valid_lft forever preferred_lft forever
- [root@Slave ~]# ip addr show
- 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN
- link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
- inet 127.0.0.1/8 scope host lo
- inet6 ::1/128 scope host
- valid_lft forever preferred_lft forever
- 2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UNKNOWN qlen 1000
- link/ether 00:0c:29:df:1e:04 brd ff:ff:ff:ff:ff:ff
- inet 192.168.1.22/24 brd 192.168.1.255 scope global eth0
- inet 192.168.1.88/32 scope global eth0
- inet6 fe80::20c:29ff:fedf:1e04/64 scope link
- valid_lft forever preferred_lft f
15.在keepalived故障时(或主备切换时),发送警告邮件给指定的管理员
keepalived通知脚本进阶示例:
◆-s, --service SERVICE,...:指定服务脚本名称,当状态切换时可自动启动、重启或关闭此服务;
◆-a, --address VIP: 指定相关虚拟路由器的VIP地址;
◆-m, --mode {mm|mb}:指定虚拟路由的模型,mm表示主主,mb表示主备;它们表示相对于同一种服务而方,其VIP的工作类型;
◆-n, --notify {master|backup|fault}:指定通知的类型,即vrrp角色切换的目标角色;
修改Master配置文件:
- [root@Master ~]# cat /etc/keepalived/keepalived.conf
- ! Configuration File for keepalived
- global_defs {
- notification_email {
- XXXXXXXX@126.com
- }
- notification_email_from Master
- smtp_server 127.0.0.1
- smtp_connect_timeout 30
- router_id LVS_DEVEL
- }
- vrrp_script chk_schedown { #定义vrrp执行脚本
- script "[ -e /etc/keepalived/down ] && exit 1 || exit 0"
- interval 1
- weight -5
- fall 2
- rise 1
- }
- vrrp_instance VI_1 {
- state MASTER
- interface eth0
- virtual_router_id 51
- priority 101
- advert_int 1
- authentication {
- auth_type PASS
- auth_pass 1111
- }
- virtual_ipaddress {
- 192.168.1.88
- }
- track_script {
- chk_schedown
- }
- #添加如下三行
- notify_master "/etc/keepalived/notify.sh -n master -a 192.168.1.88"
- notify_backup "/etc/keepalived/notify.sh -n backup -a 192.168.1.88"
- notify_fault "/etc/keepalived/notify.sh -n fault -a 192.168.1.88"
- }
- virtual_server 192.168.1.88 80 {
- delay_loop 6
- lb_algo rr
- lb_kind DR
- nat_mask 255.255.255.0
- #persistence_timeout 50
- protocol TCP
- real_server 192.168.1.9 80 {
- weight 1
- HTTP_GET {
- url {
- path /
- status_code 200
- }
- connect_timeout 2
- nb_get_retry 3
- delay_before_retry 1
- }
- }
- real_server 192.168.1.10 80 {
- weight 1
- HTTP_GET {
- url {
- path /
- status_code 200
- }
- connect_timeout 2
- nb_get_retry 3
- delay_before_retry 1
- }
- }
- sorry_server 127.0.0.1 80
- }
修改Slave的配置文件:
在Slave的keepalived配置文件中插入下面三行,位置和Master所放的位置一样。
- notify_master "/etc/keepalived/notify.sh -n master -a 192.168.1.88"
- notify_backup "/etc/keepalived/notify.sh -n backup -a 192.168.1.88"
- notify_fault "/etc/keepalived/notify.sh -n fault -a 192.168.1.88"
在Master和Slave中同时增加notify.sh 脚本:
- [root@Master ~]# cat /etc/keepalived/notify.sh
- #!/bin/bash
- # Author: freeloda
- # description: An example of notify script
- # Usage: notify.sh -m|--mode {mm|mb} -s|--service SERVICE1,... -a|--address VIP -n|--notify {master|backup|falut} -h|--help
- contact='XXXXXXX@126.com'
- helpflag=0
- serviceflag=0
- modeflag=0
- addressflag=0
- notifyflag=0
- Usage() {
- echo "Usage: notify.sh [-m|--mode {mm|mb}] [-s|--service SERVICE1,...] <-a|--address VIP> <-n|--notify {master|backup|falut}>"
- echo "Usage: notify.sh -h|--help"
- }
- ParseOptions() {
- local I=1;
- if [ $# -gt 0 ]; then
- while [ $I -le $# ]; do
- case $1 in
- -s|--service)
- [ $# -lt 2 ] && return 3
- serviceflag=1
- services=(`echo $2|awk -F"," '{for(i=1;i<=NF;i++) print $i}'`)
- shift 2 ;;
- -h|--help)
- helpflag=1
- return 0
- shift
- ;;
- -a|--address)
- [ $# -lt 2 ] && return 3
- addressflag=1
- vip=$2
- shift 2
- ;;
- -m|--mode)
- [ $# -lt 2 ] && return 3
- mode=$2
- shift 2
- ;;
- -n|--notify)
- [ $# -lt 2 ] && return 3
- notifyflag=1
- notify=$2
- shift 2
- ;;
- *)
- echo "Wrong options..."
- Usage
- return 7
- ;;
- esac
- done
- return 0
- fi
- }
- #workspace=$(dirname $0)
- RestartService() {
- if [ ${#@} -gt 0 ]; then
- for I in $@; do
- if [ -x /etc/rc.d/init.d/$I ]; then
- /etc/rc.d/init.d/$I restart
- else
- echo "$I is not a valid service..."
- fi
- done
- fi
- }
- StopService() {
- if [ ${#@} -gt 0 ]; then
- for I in $@; do
- if [ -x /etc/rc.d/init.d/$I ]; then
- /etc/rc.d/init.d/$I stop
- else
- echo "$I is not a valid service..."
- fi
- done
- fi
- }
- Notify() {
- mailsubject="`hostname` to be $1: $vip floating"
- mailbody="`date '+%F %H:%M:%S'`, vrrp transition, `hostname` changed to be $1."
- echo $mailbody | mail -s "$mailsubject" $contact ##注意此命令需要安装mailx包。
- }
- # Main Function
- ParseOptions $@
- [ $? -ne 0 ] && Usage && exit 5
- [ $helpflag -eq 1 ] && Usage && exit 0
- if [ $addressflag -ne 1 -o $notifyflag -ne 1 ]; then
- Usage
- exit 2
- fi
- mode=${mode:-mb}
- case $notify in
- 'master')
- if [ $serviceflag -eq 1 ]; then
- RestartService ${services[*]}
- fi
- Notify master
- ;;
- 'backup')
- if [ $serviceflag -eq 1 ]; then
- if [ "$mode" == 'mb' ]; then
- StopService ${services[*]}
- else
- RestartService ${services[*]}
- fi
- fi
- Notify backup
- ;;
- 'fault')
- Notify fault
- ;;
- *)
- Usage
- exit 4
- ;;
- esac
- [root@Master ~]# chmod +x /etc/keepalived/notify.sh
- [root@Slave ~]# chmod +x /etc/keepalived/notify.sh
从新载入配置文件:
- [root@Master ~]# service keepalived restart
- [root@Slave ~]# service keepalived restart
模拟故障:
现将刚才测试文件给删除。
- [root@Master ~]# rm -rf /etc/keepalived/down
查看VIP:
- [root@Master ~]# ip addr show
- 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN
- link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
- inet 127.0.0.1/8 scope host lo
- inet6 ::1/128 scope host
- valid_lft forever preferred_lft forever
- 2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
- link/ether 00:0c:29:b0:04:27 brd ff:ff:ff:ff:ff:ff
- inet 192.168.1.8/24 brd 192.168.1.255 scope global eth0
- inet 192.168.1.88/32 scope global eth0
- inet6 fe80::20c:29ff:feb0:427/64 scope link
- valid_lft forever preferred_lft forever
进入维护模式:
- [root@Master ~]# touch /etc/keepalived/down
- [root@Master ~]# ip addr show
- 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN
- link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
- inet 127.0.0.1/8 scope host lo
- inet6 ::1/128 scope host
- valid_lft forever preferred_lft forever
- 2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
- link/ether 00:0c:29:b0:04:27 brd ff:ff:ff:ff:ff:ff
- inet 192.168.1.8/24 brd 192.168.1.255 scope global eth0
- inet6 fe80::20c:29ff:feb0:427/64 scope link
- valid_lft forever preferred_lft forever
- [root@Slave ~]# ip addr show
- 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN
- link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
- inet 127.0.0.1/8 scope host lo
- inet6 ::1/128 scope host
- valid_lft forever preferred_lft forever
- 2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UNKNOWN qlen 1000
- link/ether 00:0c:29:df:1e:04 brd ff:ff:ff:ff:ff:ff
- inet 192.168.1.22/24 brd 192.168.1.255 scope global eth0
- inet 192.168.1.88/32 scope global eth0
- inet6 fe80::20c:29ff:fedf:1e04/64 scope link
- valid_lft forever preferred_lft forever
查看邮件:

大家可以看到,主备切换时,会发送邮件报警,好了到这里所有演示全部完成。
本文出自 “粗茶淡饭” 博客,请务必保留此出处http://cuchadanfan.blog.51cto.com/9940284/1696588