海量小文件存储(简称LOSF,lots of small files)出现后,就一直是业界的难题,众多博文(如 [1] )对此问题进行了阐述与分析,许多互联网公司也针对自己的具体场景研发了自己的存储方案(如taobao开源的 TFS ,facebook自主研发的 Haystack ),还有一些公司在现有开源项目(如hbase,fastdfs,mfs等)基础上做针对性改造优化以满足业务存储需求;
一. 海量小文件存储侧重于解决的问题
通过对若干分布式存储系统的调研、测试与使用,与其它分布式系统相比,海量小文件存储更侧重于解决两个问题:
1. 海量小文件的元数据信息组织与管理: 对于百亿量级的数据,每个文件元信息按100B计算,元信息总数据量为1TB,远超过目前单机服务器内存大小;若使用本地持久化设备存储,须高效满足每次 文件存取请求的元数据查询寻址(对于上层有cdn的业务场景,可能不存在明显的数据热点),为了避免单点,还要有备用元数据节点;同时,单组元数据服务器 也成为整个集群规模扩展的瓶颈;或者使用独立的存储集群存储管理元数据信息,当数据存储节点的状态发生变更时,应该及时通知相应元数据信息进行变更;
对此问题,tfs/fastdfs设计时,就在文件名中包含了部分元数据信息,减小了元数据规模,元数据节点只负责管理粒度更大的分片结构信息; 商用分布式文件系统龙存,通过升级优化硬件,使用分布式元数据架构——多组(每组2台)高性能ssd服务器——存储集群的元数据信息,满足单次io元数据 查询的同时,也实现了元数据存储的扩展性;Haystack Directory模块提供了图片逻辑卷到物理卷轴的映射存储与查询功能,使用Replicated Database存储,并通过cache集群来降低延时提高并发,其对外提供的读qps在百万量级;
2. 本地磁盘文件的存储与管理(本地存储引擎):对于常见的linux文件系统,读取一个文件通常需要三次磁盘IO(读取目录元数据到内存,把文件的 inode节点装载到内存,***读取实际的文件内容);按目前主流2TB~4TB的sata盘,可存储2kw~4kw个100KB大小的文件,由于文件数 太多,无法将所有目录及文件的inode信息缓存到内存,很难实现每个图片读取只需要一次磁盘IO的理想状态,而长尾现象使得热点缓存无明显效果;当请求 寻址到具体的一块磁盘,如何减少文件存取的io次数,高效地响应请求(尤其是读)已成为需要解决的另一问题;
对此问题,有些系统(如tfs,Haystack)采用了小文件合并存储+索引文件的优化方案,此方案有若干益处:a.合并后的合并大文件通常在 64MB,甚至更大,单盘所存存储的合并大文件数量远小于原小文件的数量,其inode等信息可以全部被cache到内存,减少了一次不必要的磁盘 IO;b.索引文件通常数据量(通常只存储小文件所在的合并文件,及offset和size等关键信息)很小,可以全部加载到内存中,读取时先访问内存索 引数据,再根据合并文件、offset和size访问实际文件数据,实现了一次磁盘IO的目的;c.单个小文件独立存储时,文件系统存储了其guid、属 主、大小、创建日期、访问日期、访问权限及其它结构信息,有些信息可能不是业务所必需的,在合并存储时,可根据实际需要对文件元数据信息裁剪后在做合并, 减少空间占用。除了合并方法外,还可以使用性能更好的SSD等设备,来实现高效响应本地io请求的目标。
当然,在合并存储优化方案中,删除或修改文件操作可能无法立即回收存储空间,对于存在大量删除修改的业务场景,需要再做相应的考量。
二. 海量小文件存储与Ceph实践
Ceph 是近年越来越被广泛使用的分布式存储系统,其重要的创新之处是基于 CRUSH 算法的计算寻址,真正的分布式架构、无中心查询节点,理论上无扩展上限(更详细ceph介绍见网上相关文章);Ceph的基础组件RADOS本身是对象存 储系统,将其用于海量小文件存储时,CRUSH算法直接解决了上面提到的***个问题;不过Ceph OSD目前的存储引擎( Filestore , KeyValuestore )对于上面描述的海量小文件第二个问题尚不能很好地解决;ceph社区曾对此问题做过描述并提出了基于rgw的一种 方案 (实际上,在实现本文所述方案过程中,发现了社区上的方案),不过在***代码中,一直未能找到方案的实现;
我们在Filestore存储引擎基础上对小文件存储设计了优化方案并进行实现,方案主要思路如下:将若干小文件合并存储在RADOS系统的一个 对象(object)中,<小文件的名字、小文件在对象中的offset及小文件size>组成kv对,作为相应对象的扩展属性(或者 omap,本文以扩展属性表述,ceph都使用kv数据库实现,如leveldb)进行存储,如下图所示,对象的扩展属性数据与对象数据存储在同一块盘上;
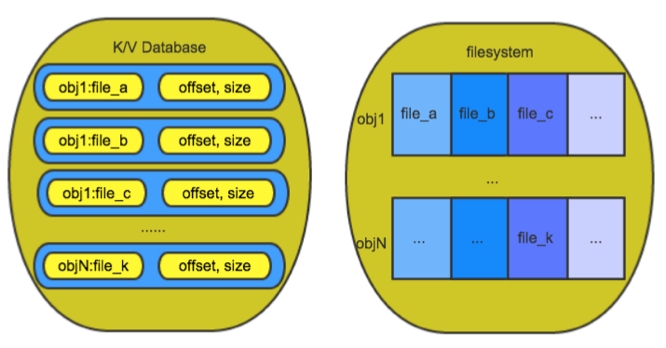
使用本结构存储后,write小文件file_a操作分解为: 1)对某个object调用append小文件file_a;2)将小文件file_a在相应object的offset和size,及小文件名字 file_a作为object的扩展属性存储kv数据库。read小文件file_a操作分解为:1)读取相应object的file_a对应的扩展属性 值(及offset,size);2)读取object的offset偏移开始的size长度的数据。对于删除操作,直接将相应object的 file_a对应的扩展属性键值删除即可,file_a所占用的存储空间延迟回收,回收以后讨论。另外,Ceph本身是强一致存储系统,其内在机制可以保 证object及其扩展属性数据的可靠一致;
由于对象的扩展属性数据与对象数据存储在同一块盘上,小文件的读写操作全部在本机本OSD进程内完成,避免了网络交互机制潜在的问题。另一方面, 对于写操作,一次小文件写操作对应两次本地磁盘随机io(逻辑层面),且不能更少,某些kv数据库(如leveldb)还存在write amplification问题,对于写压力大的业务场景,此方案不能很好地满足;不过对于读操作,我们可以通过配置参数,尽量将kv数据保留在内存中, 实现读取操作一次磁盘io的预期目标;
如何选择若干小文件进行合并,及合并存储到哪个对象中呢?最简单地方案是通过计算小文件key的hash值,将具有相同hash值的小文件合并存 储到id为对应hash值的object中,这样每次存取时,先根据key计算出hash值,再对id为hash值的object进行相应的操作;关于 hash函数的选择,(1)可使用最简单的hash取模,这种方法需要事先确定模数,即当前业务合并操作使用的object个数,且确定后不能改变,在业 务数据增长过程中,小文件被平均分散到各个object中,写压力被均匀分散到所有object(即所有物理磁盘,假设object均匀分布) 上;object文件大小在一直增长,但不能***增长,上限与单块磁盘容量及存储的object数量有关,所以在部署前,应规划好集群的容量和hash模 数。(2)对于某些带目录层次信息的数据,如/a/b/c/d/efghi.jpg,可以将文件的目录信息作为相应object的id,及/a/b/c /d,这样一个子目录下的所有文件存储在了一个object中,可以通过rados的listxattr命令查看一个目录下的所有文件,方便运维使用;另 外,随着业务数据的增加,可以动态增加object数量,并将之前的object设为只读状态(方便以后的其它处理操作),来避免object的***增 长;此方法需要根据业务写操作量及集群磁盘数来合理规划当前可写的object数量,在满足写压力的前提下将object大小控制在一定范围内。
本方案是为小文件(1MB及以下)设计的,对于稍大的文件存储(几十MB甚至更大),如何使用本方案存储呢?我们将大文件 large_file_a切片分成若干大小一样(如2MB,可配置,***一块大小可能不足2MB)的若干小块文 件:large_file_a_0, large_file_a_1 ... large_file_a_N,并将每个小块文件作为一个独立的小文件使用上述方案存储,分片信息(如总片数,当前第几片,大文件大小,时间等) 附加在每个分片数据开头一并进行存储,以便在读取时进行解析并根据操作类型做相应操作。
根据业务的需求,我们提供如下操作接口供业务使用(c++描述):
- int WriteFullObj(const std::string& oid, bufferlist& bl, int create_time = GetCurrentTime());
- int Write(const std::string& oid, bufferlist& bl, uint64_t off, int create_time = GetCurrentTime());
- int WriteFinish(const std::string& oid, uint64_t total_size, int create_time = GetCurrentTime());
- int Read(const std::string& oid, bufferlist& bl, size_t len, uint64_t off);
- int ReadFullObj(const std::string& oid, bufferlist& bl, int* create_time = NULL);
- int Stat(const std::string& oid, uint64_t *psize, time_t *pmtime, MetaInfo* meta = NULL);
- int Remove(const std::string& oid);
- int BatchWriteFullObj(const String2BufferlistHMap& oid2data, int create_time = GetCurrentTime());
对于写小文件可直接使用WriteFullObj;对于写大文件可使用带offset的Write,写完所有数据后,调用 WriteFinish;对于读取整个文件可直接使用ReadFullObj;对于随机读取部分文件可使用带offset的Read;Stat用于查看文 件状态信息;Remove用于删除文件;当使用第二种hash规则时,可使用BatchWriteFullObj提高写操作的吞吐量。