












引言
公司由粗犷式发展转向精细化运营的过程中,数据决策支持发挥着至关重要的作用。而在传统行业里,由于数据量相对较小;业务系统变更相对规律;系统架构相对简单;数据来源相对单一等原因,从而使数据的计算过程更加简单,计算结果更加准确。而作为业务与技术高速发展的京东,用常规的架构设计无法满足公司对数据高 质量的要求。如何在保障业务高速发展的同时,将数据仓库的数据污染降低到最小?我们重点来说说引起数据污染的原因以及解决方案。
业务系统的数据源多样化
随着技术的发展,不同的业务系统由不同的团队开发与维护,造成了公司多样化的数据存储方式,如SQL SERVER、ORACLE、MYSQL、HBASE、DB2、XML、文本等数十种数据结构,于是就要求数据中心支持异构数据源的数据同步,并将数据存储为可相互关联的统一数据结构,数据源越多,数据的交换成本和维护成本就越高。这一阶段数据的主要污染集中在不同数据源之间的数据一致性。
业务系统架构频繁变更
传统行业的优势是业务系统相对成熟且稳定,而互联网行业的架构大幅度升级如家常便饭,有时是迫于业务的快速发展,有时候是为了改变而改变,所有改变中最为痛苦的就是新老系统并行运行,其中部分业务仍在老系统A上运行,而部分业务在新系统B上运行,这一阶段的数据污染主要体现在:
1)新老系统数据不一致的差异解释
2)新老系统数据库结构的不统一,导致数据中心的数据抽取不稳定且后续业务的解释异常复杂。
数据库设计复杂化
传 统行业依靠优秀的大型硬件配置来支撑海量数据的查询,除非必要情况一般采用单一表的数据存储,而在互联网行业通过分库分表来解决业务的可扩展性,对于数据中心来讲,业务系统的分库规则的多样化,在数据集中时面临巨大的挑战。对于京东来讲,库房数据的质量保障是我所接触到的所有场景中最为复杂的,有几个特 点:
1)库房分布地域不同,网络环境好坏不一
2)各库房根据业务不同,数据库结构不尽相同
3)当地库房系统维护人员工作习惯不统一
这三点对仓库生产基地数据的质量提出了非常高的挑战。
业务系统的人员数据质量意识单薄
由于长期的业务开发更加关注业务系统流程,功能方面的可用性,对于滞后于业务系统的数据统计、数据分析与数据挖掘关注较少,且不属于职能范畴,因此粗糙的前期数据设计会给后端的数据消费带来极高的成本:
1)业务系统为保障数据的展现实效性,将商品的描述信息全部存储为XML,后端的消费时需要解析XML,这没有技术难点,但这种灵活的存储方式使得XML的结构变更非常容易,后端解析很难保证一致性。所以,在设计时应该存储XML,同时将商品属性信息进行格式化存储,后端采用结构化的统一数据。这样XML与格式化的数据由同一个团队提供,在一定程度上保障了数据源的稳定。
2)大量的数据分析要求数据的变化有历史记录,从而发现用户的有效行为,但有些系统没有存储表变更历史或者变更日志,从而导致变化的数据无法追溯;更有甚者直接登录到数据库进行数据的调整操作,违规的数据修改,会给后端带来严重的数据污染。
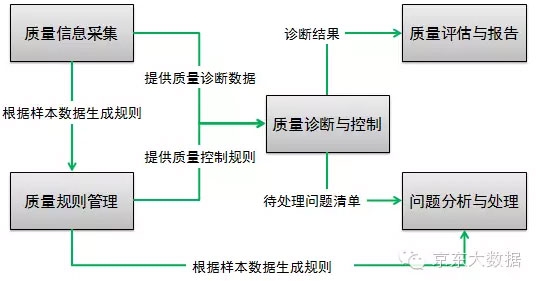
解决方案-数据质量管理框架
1)质量信息采集:获取数据信息
2)质量规则管理:数据验证规则,包含系统规则、技术规则、业务规则
3)质量诊断与控制:大数据监控平台
4)质量评估与报告:定期完成质量报告
5)问题分析与处理:发现问题,分析问题,解决问题
解决方案-数据质量系统架构
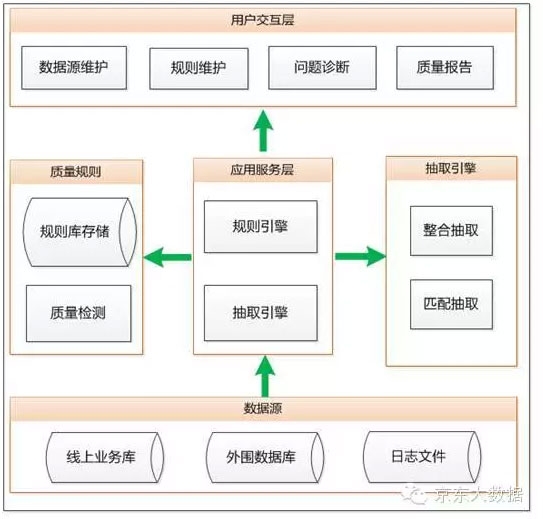
1)数据源:
a、线上业务库:生产业务系统数据
b、外部数据库:外围系统对接数据
c、日志文件:操作流点击日志文件(非结构化数据)
2)应用服务层:数据处理核心层
a、规则引擎:主要包括规则库存储和质量检测,负责质量规则维护和检测处理,保证数据抽取质量
b、抽取引擎:主要包括匹配抽取和整合抽取,保证数据更快抽取。
3)用户交互层:
a、数据源维护:主要包括SQL SERVER、ORACLE、MYSQL、HBASE等数据源的维护
b、规则维护:质量校验规则维护
c、问题诊断:质量问题分析和解决
d、质量报告:数据质量定期报告
小结
以 前有一句话来形容业务系统的架构对数据质量的影响:垃圾进去,垃圾出来,虽然形容的不够贴切,但一定程度上反映了数据来源的质量决定了数据仓库数据污染的程度。那么问题来了,是否可以***的保障数据仓库的质量呢?答案是肯定的,但这要花费很大的代价,即数据质量的高低与资源的消费成本成正比。
因此个人认为,除了在质量监控系统的自动化上面进行优化和减少人工干预外,还需要达成共识,20%的数据满足了80%的企业级数据需求,二八原则在这里同样适用。
在快速迭代的业务系统时期,数据污染是必然的,所以即使严格的审计报告也会有大量差异的解释工作,即做到数据污染的可追述、可证明即可满足企业数据需求。













