为了在网络设备这块大热地盘里开疆拓土,Intel在嵌入式平台领域已经持续发力了好一段时间。目前,它在该领域内***端的盒式平台是E5双路CPU平台,在实验室测试环境中***可跑到80G的网络吞吐——这已然达到了单一硬件平台的计算能力顶峰,并且短期内很难有本质性的提升。
这时候,如果还想进一步提升处理性能,那么,就该轮到硬件分流机制粉墨登场了。
何谓“硬件分流”?
硬件分流机制是为了进一步引入交换架构、实现多硬件平台的分布式堆叠处理而生。当然,能顺带节省出一点点儿软件分流的计算资源,也是乐事一桩。
如此一来,ADC设备的性能扩展就可以是现有***端盒式设备的线性倍数关系,再配合机架式可扩展业务板硬件设计,那么实现ADC设备的性能n倍增、实现真正计算资源随意在线扩展也是指日可待之事。
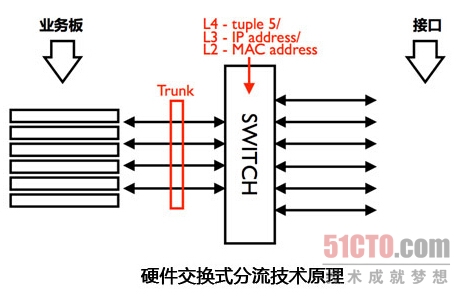
硬件交换分流架构
所谓硬件分流是指,数据包进入CPU处理之前先经过硬件交换芯片的分流处理。就像地铁口进站需要排队一样,利用交换芯片的trunk分流机制,所有数据包在进入设备的时候都会经过hash计算,交换芯片再根据数据包计算出的hash值将该数据包分配给各个业务板——具备相同hash值的数据流自然会被分配到同一块业务板中去。 现在,暂停一下,一个需要我们注意的例外流程——流关联——出现了。
什么是流关联?
在网络中传输的数据流,会在某些情况下衍生出关联关系,即两条具有亲和性的数据流需要在同一块业务板上进行处理。这个时候交换芯片硬件分流有可能会掉链子,就需要业务板上的软件对数据包进行二次分流。因为业务板都是连接在同一个交换系统上,所以这个二次分流就非常方便了——只需要将数据报文打上适当的vlan标签发给交换芯片,交换芯片就能够正确地将数据报文发送到正确的业务板上。
T1和F5 viprion机架式设备的对比
T1的硬件交换式架构产品与F5的viprion系列机架式产品都是利用外部硬件交换系统实现分流,以实现业务系统计算能力的堆叠的。
但是,此硬件架构非彼硬件架构,T-Force V系列在这方面与F5的Viprion还是有着很大差别:
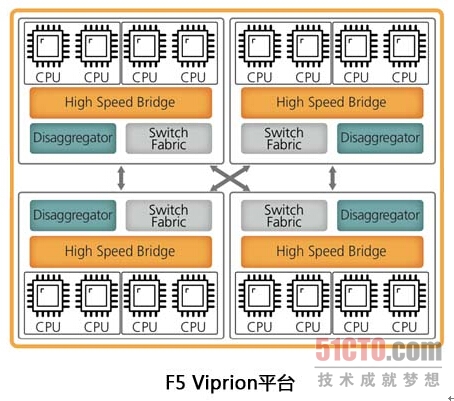
不难看出,上图的交换系统容量是扩展式的,并没有交换板的概念,交换系统分布在各个业务板上。
由于没有统一的交换网络,所以在背板设计上两两业务槽位之间都要做全速率的连接,这就是所谓的Full-mesh架构。这是一种比较少应用的架构,因为其设计复杂度非常高,存在工艺瓶颈,所以以F5的160G业务板为例,目前背板***水平工艺也就只能支撑4个槽位。
T-Force V系列
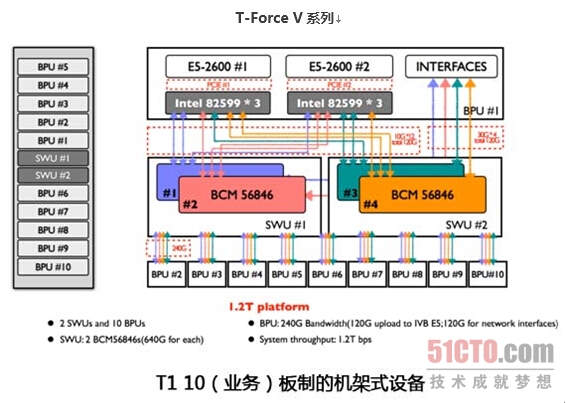
T-Force V硬件交换采用星型架构,也就是统一交换节点,只需要增加中心交换节点的交换容量,就可以很方便地扩展更多的业务板,堆叠更多的计算资源。这种双交换架构也是太一星晨研发的***思路。
在这个系统中,交换板扩展为2块,用4片640G交换芯片并行连接可以扩展出10个120G业务槽位。总的业务吞吐能力为1.2T,成为业内首款T级别应用交付产品,远超F5 Viprion系列。
无创新不发展,在这个神话频出的技术领域里,T-Force开创了7层交付的里程碑,相信在不久的将来,它会带给我们更多开疆拓土的惊喜。