













CPU篇
邓小平曾经说过一句很经典的话:“两手抓,两手都要硬”。作为一类比较特殊的网络设备,应用交付产品同样存在着两个重要的要求:一是网关位置的应用场景要求具有超大的网络吞吐性能;另一方面,应用层加速的特性功能又要求具备超强的CPU计算能力。从这种意义上来讲,它是既要求纯四层防火墙场景下的高吞吐,又要求防攻击防病毒特性下的高计算能力。
那么,怎么样才能在应用交付上实现这两大重要功能?Intel x86平台款款而来。
近年来,为了在网络产品上开疆拓土,Intel在嵌入式平台领域上持续发力,并且其Sandybridge / Ivybridge系列平台在IO方面做了大幅优化,这就使得它在网络吞吐方面不再存在短板。
基础硬件平台搭建起来后,让各家厂家继续抓耳挠腮的事情就只剩一样了:优化。怎样才能在同质化的硬件平台上优化各自的软件架构,并创造最大的性能效益,成为了让各应用交付厂商两眼冒绿光的重要课题。
在x86平台上,优化目标很明确:就是在单CPU处理能力够强劲的基础上增加多核的并行计算水平。目前在中低端嵌入式平台上普遍应用的Sandybridge/Ivybridge酷睿CPU,最多4核心,如果算上超线程计数可达8核心;而应用于中高端嵌入式的双路至强平台,则最多可以做到2路10核心也就是总共20核心,再算上超线程即可达到40核心之多。如此多的CPU核心,如果能够做到完全并行的话,创造出的性能效益那是杠杠地强啊!
通用操作系统的困扰
因为Linux自身就具备支持并行化处理的功能,因此,目前国内大部分厂商都采用直接利用Linux的SMP模式。

为什么会导致这种问题出现?
第一,流水线作业导致堵车事故时有发生。Linux的SMP在工作时,CPU几个核必须流水线一样依次处理各个任务,前面的任务完不成,后面的任务就不能继续。
第二,SMP模式存在大量的互锁操作。何为互锁操作?我们来打个比方,我们把CPU比作人。如果一群人打算吃一筐苹果,当第一个人从筐里拿苹果的时候,为了避免与其他人的操作产生冲突,需要临时“锁”住这筐苹果,这样其他人就必须等第一个人把苹果吃完才能接着“吃”。如此一来,必然人数越多,冲突就越厉害。
第三,内存共享与IPC机制。Linux多核内存共享,一个CPU操作内存的部分数据块时,其他CPU就得在旁边干等着。
第四,是IPC通讯,CPU核与核之间完成交互、调度机制,需要通过IPC消息,而这个在大流量应用层处理时,往往占据了大量的系统开销。
由于SMP机制的这些问题,因此直接导致了在多核平台下,软件的使用效率很低。
T-Force应用交付如何做到高性能?
同样是多核平台,T-Force的ADC为什么能做到这么高的性能呢?
核心在于,T-Force单独设计了软件架构,在业务系统前端增加了分流器的概念。也就是说,进入ADC设备的数据流首先经过分流器的梳理,将数据流分成若干份(一般是按照TCP/UDP五元组的hash值进行分流),再分配到每个核心的业务系统上。这样每个核心的业务系统处理自己单独的一份数据流,不需要和其他核心共享任何表项资源,最大程度上避免共享资源的互斥访问,增加业务处理的并行性。
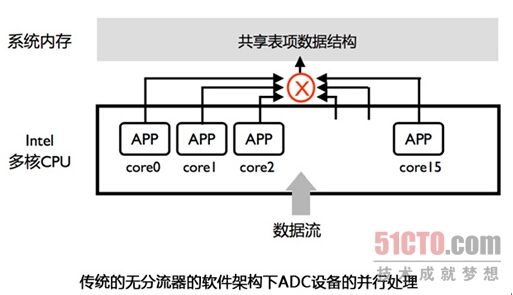
从上图不难看出,处理业务流量的APP受传统的操作系统的SMP管理,每个APP随机处理数据包。因此所有的APP会在系统内存中共享全局的连接表等资源,业务处理过程就存在比较明显的互斥访问。在核心数越多的情况下,互斥碰撞的概率越高,并行化水平也就衰减得越快。
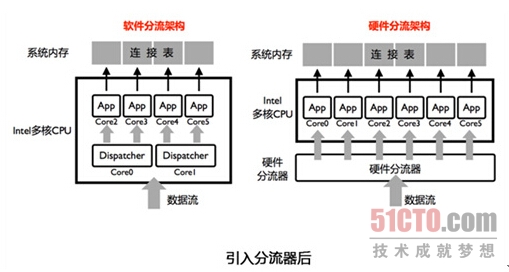
分流器的实质是将流量分组化,每个核心处理一组独立的流。分组之后连接表等数据结构都分布化了,核心之间自然也不存在共享互斥了。
软件分流与硬件分流的差别
软件分流是使用多核CPU内部的某些核心去处理分流的工作。
硬件分流是在CPU之外扩展硬件组件完成分流的工作。
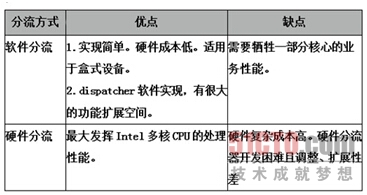
软件分流器架构以其实现方便,灵活性好的优点,在盒式ADC设备中普遍应用,为其带来了很大的成本、性能优势。











