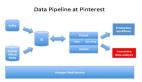
借助真实案例和代码样本,本文作者展示了如何将Sparke和MySQL结合起来,创造数据分析上的强大工具。 Apache Spark是一个类似Apache Hadoop的集群计算框架,在Wikipedia上有大量描述:Apache Spark是一个开源集群计算框架,出自加州大学伯克利分校的AMPLab,后被捐赠给了Apache软件基金会。 相对于Hadoop基于磁盘的两段式MapReduce规范,Spark基于内存的多段式基元在特定应用上表现要优出100倍。Spark允许用户程序将数据加载到集群内存中反复查询,非常适合机器学习算法。 
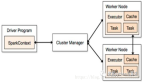
与流行的看法相反,Spark不需要将所有数据存入内存,但会使用缓存来加速操作(就像MySQL那样)。Spark也能独立运行而无需Hadoop,并可以运行在单独一台服务器上(甚至笔记本或台式机上),并充分利用所有CPU内核。开启它并使用分布式模式真的很简单。先打开master,在同一个节点上运行slave:
然后在任何额外的节点上运行Spark worker(确定向/etc/hosts 添加了hostname或者使用DNS):
在很多任务中MySQL(开箱即用的)表现并不太好。MySQL的限制之一在于:1次查询=1个CPU内核。也就是说,即便你有48个速度飞快的内核,外加一个大型数据集可用,也无法充分利用所有的计算能力,相反Spark却能充分使用CPU内核。
MySQL与Spark的另一差异在于:
l MySQL使用所谓的“写时模式(schema on write)”——需要将数据转化到MySQL中,如果未包含在MySQL里,就无法使用sql来查询。
l Spark(还有Hadoop/Hive)使用“读时模式(schema on read)”——比如在一个压缩txt文件顶部使用表格结构(或者其他支持的输入格式),将其看作表格;然后我们可以用SQL来查询这个“表格”。
也就是说,MySQL负责存储+处理,而Spark只负责处理,并可直接贯通数据与外部数据集(Hadoop、Amazon S3,本地文件、JDBC MySQL或其他数据集)的通道。Spark支持txt文件(压缩的)、SequenceFile、其他Hadoop输入格式和Parquet列式存储。相对Hadoop来说,Spark在这方面更为灵活:例如Spark可以直接从MySQL中读取数据。
向MySQL加载外部数据的典型管道(pipeline)是:
1、 解压缩(尤其是压缩成txt文件的外部数据);
2、用“LOAD DATA INFILE”命令将其加载到MySQL的存储表格中;
3、只有这样,我们才能筛选/进行分组,并将结果保存到另一张表格中。
这会导致额外的开销;在很多情况下,我们不需要“原始”数据,但仍需将其载入MySQL中。
相反,我们的分析结果(比如聚合数据)应当存在MySQL中。将分析结果存在MySQL中并非必要,不过更为方便。假设你想要分析一个大数据集(即每年的销售额对比),需要使用表格或图表的形式展现出来。由于会进行聚合,结果集将会小很多,将其存在MySQL中与很多标准程序一同协作处理将会容易许多。
一个有趣的免费数据集是Wikipedia的页数(从2008年启用后到现在,压缩后大于1TB)。这个数据可以下载(压缩空间确定txt文件),在AWS上也是可用的(有限数据集)。数据以小时聚合,包括以下字段:
l项目(比如en,fr等,通常是一种语言)
l页头(uri),采用urlencode编码
l请求数
l返回内容的大小
(数据字段编译到了文件名中,每小时1个文件)
我们的目标是:找出英文版wiki中每日请求数位居前10的页面,不过还要支持对任意词的搜索,方便阐释分析原理。例如,将2008到2015年间关于“Myspace”和“Facebook”的文章请求数进行对比。使用MySQL的话,需要将其原封不动的载入MySQL。所有文件按内置的日期编码分布。解压的总大小大于10TB。下面是可选的步骤方案(典型的MySQL方式):
1、解压文件并运行“LOAD DATA INFILE”命令,将其录入临时表格:
2、“插入到”最终的表格,进行聚合:
3、通过url解码标题(可能用到UDF)。
开销很大:解压并将数据转化为MySQL格式,绝大部分都会被丢弃,作为损耗。
根据我的统计,整理6年来的数据需耗时超过1个月,还不包括解压时间,随着表格逐渐变大、索引需要更新所带来的加载时间折损。当然,有很多办法可以加速这一过程,比如载入不同的MySQL实例、首先载入内存表格再集合成InnoDB等。
不过最简单的办法是使用Apache Spark和Python脚本(pyspark)。Pyspark可以读出原始的压缩txt文件,用SQL进行查询,使用筛选、类似urldecode函数等,按日期分组,然后将结果集保存到MySQL中。
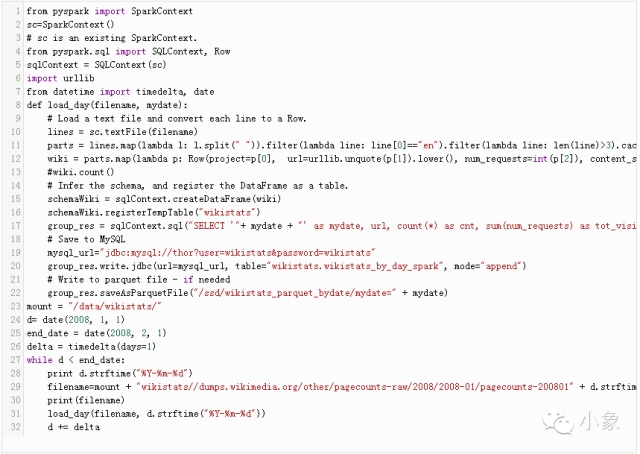
下面是执行操作的Python脚本:
在脚本中用到了Spark来读取原始压缩文件(每次一天)。我们可以使用目录作为“输入”或者文件列表。然后用弹性分布式数据集(RDD)转化格式;Python包含lambda函数映射和筛选,允许我们将“输入文件”分离并进行筛选。
下一步是应用模式(declare fields);我们还能使用其他函数,比如用urllib.unquote来解码标题(urldecode)。最终,我们可以注册临时表格,然后使用熟悉的SQL来完成分组。
该脚本可以充分利用CPU内核。此外,即便不使用Hadoop,在分布式环境中运行也非常简易:只要将文件复制到SparkNFS/外部存储。
该脚本花了1个小时,使用了三个box,来处理一个月的数据,并将聚合数据加载到MySQL上(单一实例)。我们可以估出:加载全部6年的(聚合)数据到MySQL上需要大约3天左右。
你可能会问,为什么现在要快得多(而且实现了同样的实例)。答案是:管道不同了,而且更为有效。在我们起初的MySQL管道中,载入的是原始数据,需要大约数月时间完成。而在本案例中,我们在读取时筛选、分组,然后只将需要的内容写入MySQL。
这里还有一个问题:我们真的需要整个“管道”吗?是否可以简单地在“原始”数据之上运行分析查询?答案是:确实有可能,但是也许会需要1000个节点的Spark集群才能奏效,因为需要扫描的数据量高达5TB(参见下文中的“补充”)。
#p#
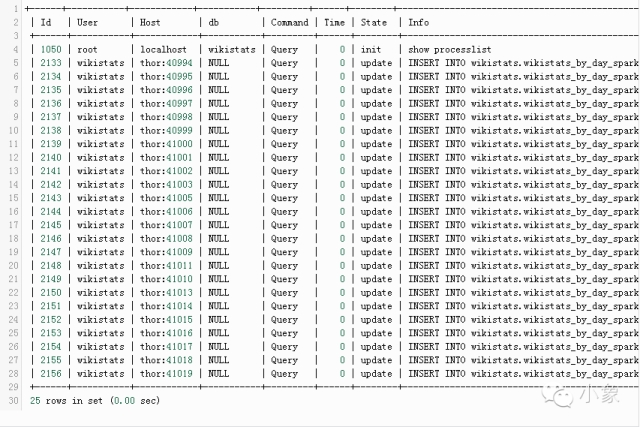
通过使用group_res.write.jdbc(url=mysql_url, table=”wikistats.wikistats_by_day_spark”, mode=”append”) ,Spark会启动多线程插入。
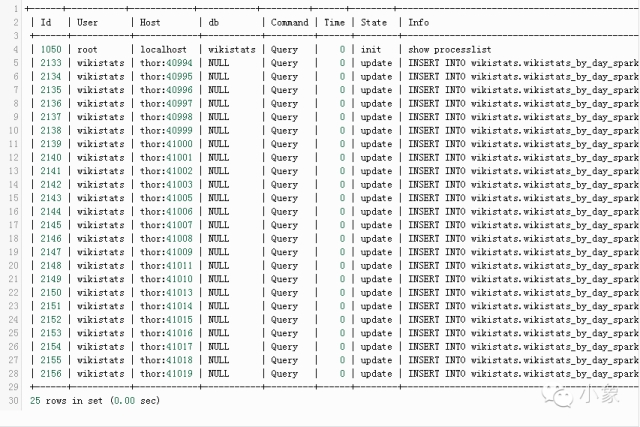
Spark提供了web接口,方便对工作进行监控管理。样例如下:运行wikistats.py application:
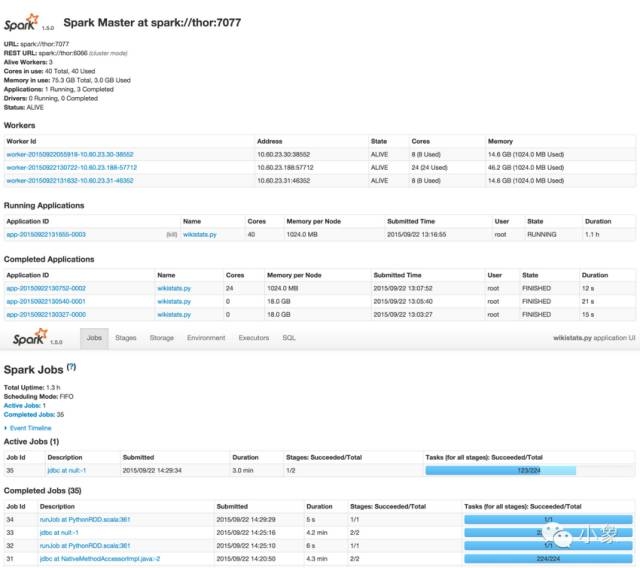
结果:使用Parquet分列格式与MySQL InnoDB表格
Spark支持Apache Parquet分列格式,因此我们可以将RDD存储为parquet文件(存入HDFS时可以保存到目录中):
![]()
我们将管道结果(聚合数据)存入Spark。这次使用了按天分区(“mydate=20080101”),Spark可以在这种格式中自动发现分区。得到结果后要进行查询。假设我们想要找到2018年1月查询最频繁的10大wiki页面。可以用MySQL进行查询(需要去掉主页和搜索页):

请注意,我们已经使用了聚合(数据汇总)表格,而不是“原始”数据。我们可以看到,查询花了1小时22分钟。由于将同样的结果存入了Parquet(见脚本)中,现在可以在Spark-SQL中使用它了:
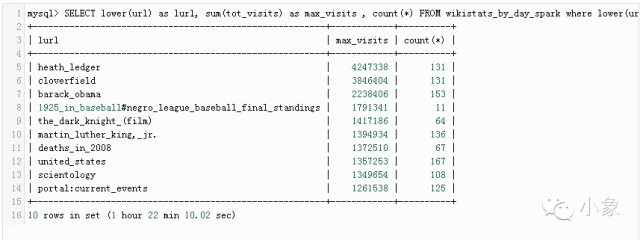
这将用到spark-sql的本地版本,而且只用到1个主机。
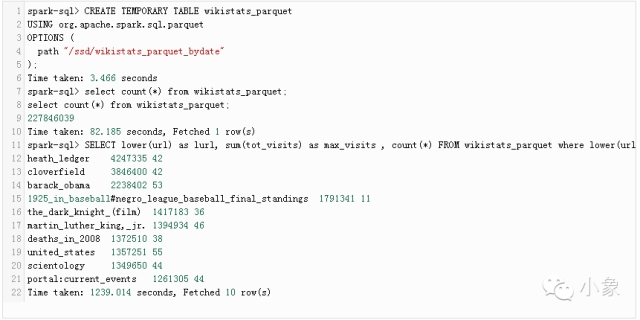
耗时大约20分钟,比之前更快。
Apache Spark是分析和聚合数据的好办法,而且非常简便。我喜欢Spark与其他大数据还有分析框架的原因在于:
l开源与积极开发
l不依赖工具,例如输入数据与输出数据不一定非要借助Hadoop
l独立模式,启动迅速,易于部署
l大规模并行,易于添加节点
l支持多种输入与输出格式;比如可以读取/写入MySQL(Java数据库连接驱动)与Parquet分列格式
但是,也有很多缺点:
l技术太新,会有一些bug和非法行为。很多错误难以解释。
l需要Java;Spark 1.5仅支持Java 7及以上版本。这也意味着需要额外内存——合情合理。
l你需要通过“spark-submit”来运行任务。
我认为作为工具,Apache Spark十分不错,补足了MySQL在数据分析与商业智能方面的短板。