今天要讲的题目是《企业级云平台的实践和思考》, 主要涉及一些基于云环境的应用构建的技术, 讲一下我在这方面的一些实践经历和一些思考, 主要讲两个参与开发的系统的功能和设计为主,不会涉及太多细节技术。 当然,我们也可以就一些点具体讨论一下。
资源管理和应用管理
基于云的应用平台,我将它分成两类:
一块是资源管理技术, 比如私有云如OpenStack、CloudStack或者公有云技术; 还有就是资源集群管理技术, 在Docker这个技术领域,个人感觉集群技术更适用。
另一块就是应用的构建和管理技术, 包括应用资源管理,应用构建、部署、维护、 监控和弹性扩展等技术,以下我会就这两块来分享。
先看集群技术,大家都知道,云计算、大数据相关的技术最早都是从集群管理技术开始的,”Google的几篇经典论文介绍了当前大数据技术格局的相关基础技术,包括GFS、MapReduce、BigTable及Chubby等。另外就是Borg这个技术,它是Google内部一切服务的基础。最近朋友圈大家也不断转发最新的Borg的论文, 其实国内外互联网公司也有类似的系统,如Twitter中使用的由加州大学伯克利分校AMPLab开发的Mesos,国内公司如百度的Volunteer Computing平台以及腾讯SOSO部门开发的台风系统。 Hadoop社区2.X版本引入的Yarn也是类似思路的产物。这些技术因为Docker或者Linux上的容器技术的出现都有了新的变化, 就是我们大家都知道的k8s、Mesos+Marathon、百度Matrix、腾讯Gaia等。
以上技术都是立足互联网应用的,企业级其实也有类似的技术。 分布式领域有一篇著名的论文《Utopia: a Load Sharing Facility for Large, Heterogeneous Distributed Computer Systems 》,这个算是分布式计算领域的开山几篇论文之一,1993年发表的,包括Google的几篇著名论文就引用了它,它描述的就是当前流行的分布式计算体系,论文作者就是分布式计算公司Platform Computing的创始人。
资源管理器:Platform EGO
下来我们要介绍的Platform EGO就是这个技术在HPC等分布式企业领域演进10年后的2.0架构中的资源管理技术, 在最近北京、西安的Mesos Meetup都有所介绍, 就是所谓的IBM Platform DCOS技术,下面是其中一张PPT。
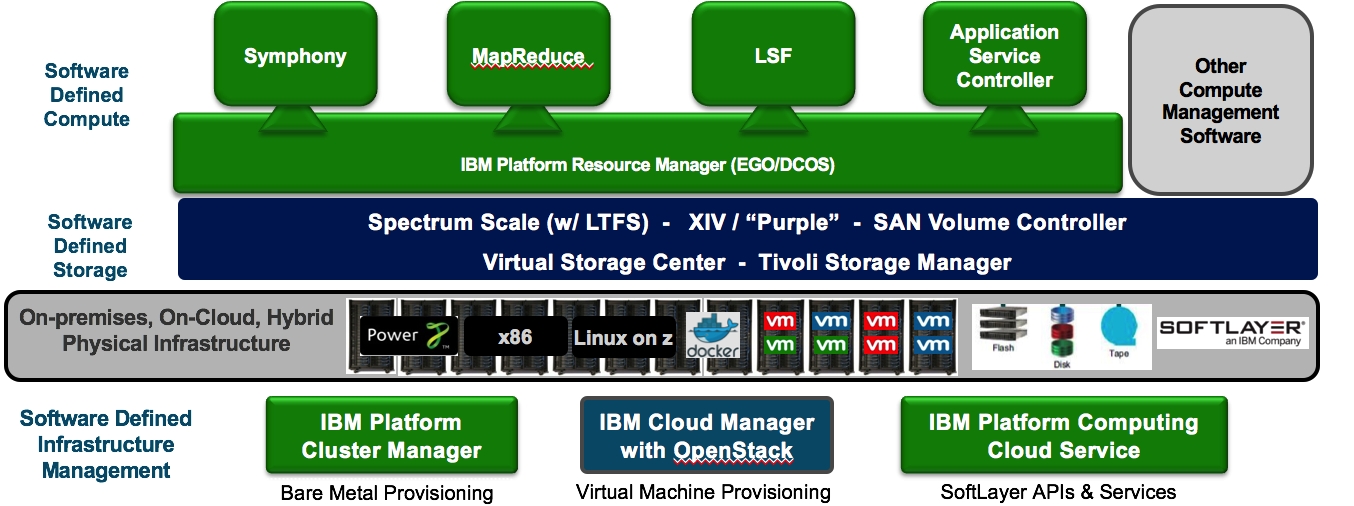
上面的图中所有绿色都是IBM Platform的产品,其中一个核心就是它的资源管理器 Resource Manager(EGO/DCOS)。 它是2004~2005年开始设计开发,和上层的任务负载调度系统LSF,Symphony合起来构成业界最早出现的二层调度系统,至少是针对企业市场交付的第一款类似产品。
我2005年在腾讯开始接触分布式系统设计开发, 2006年加入Platform Computing,我2006~2010年之间四年多一直参与开发这个产品和基于它的云管理产品Platform ISF。Platform ISF在2011年被Forrester评价为私有云业界第一, 但是IBM收购Platform后相关的策略变化导致它从产品序列中退出作为IBM Platform Cluster Manager的一部分保留。
EGO架构
下面来看EGO的一个模块图 :
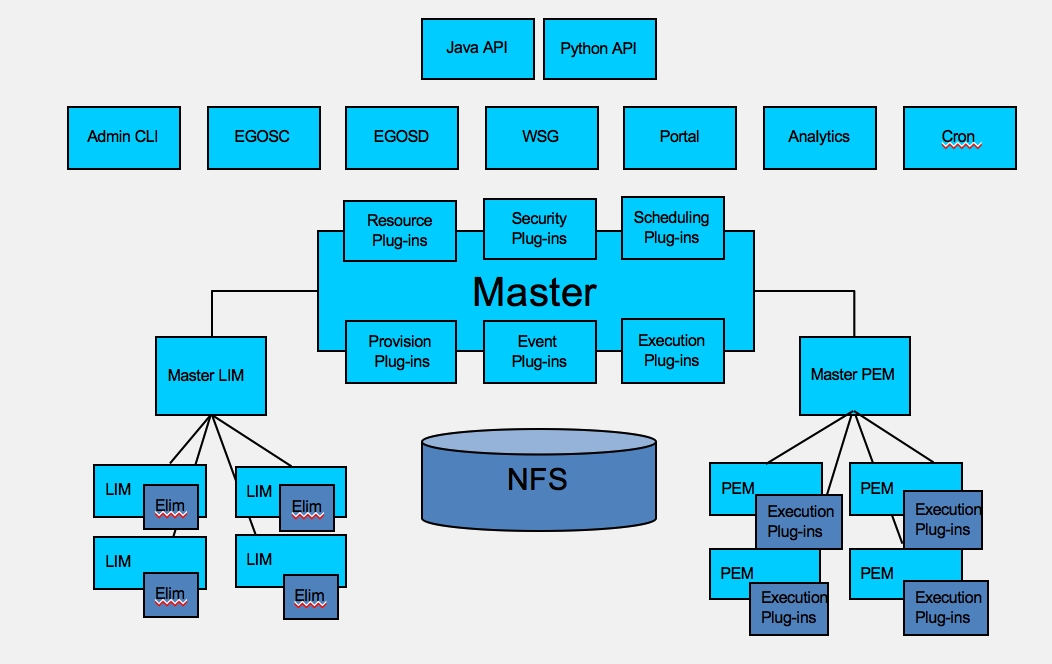
这是一个非官方的架构图,是我根据对系统的理解和当时的一些规划画的,不代表现在情况。它是一个典型的SOA架构,核心包括的LIM、PEM和Master组成的核心服务, 上层包括initd Service EGOSC、name Service egosd、crond Service - Cron、web api service- wsg、自服务门户、分析服务等,也支持C、Java、Python API,后来也有Restful API。 我有意将它画得像一个人,有手有脚,有大脑主要想表达其中核心资源管理问题3块, 一是收集信息,一直执行任务,一是资源分配调度, 调度就是大脑,收集信息和执行任务就是手脚。
从上面的图中能够看出来,EGO核心Master它是基于插件的架构, 包括资源插件、安全插件、调度插件、部署(provision)插件、 事件插件和执行插件。
LIM( Load Information Manager)是一个用来收集信息的Master-Slave分布式系统,作为默认的资源插件使用。 实际上EGO Master会保留标准的API,外部系统可以容易地增加新的资源类型, 比如软件License,网络拓扑管理等资源信息。 EGO将各种资源被抽象为有类型的Resource Entity和具有一组属性,用name-type-value 3元组来描述, 这个概念等价于DMTF组织定义的CIM(Common Information Modle)并具有同样的表达能力,实践中也确实覆盖了软件,硬件等各种需求。
PEM(Process Execution Manager)是执行系统, 也是一个主从结构的分布式系统, 默认master内嵌在EGO Maser中,但后续设计会将它拆除来通过插件完成, 同时支持其他各种执行系统。 这里EGO会为每个外部系统分配一部分资源(抽象单位为slot,可以通过配置定义slot具体对应为多少MEM、CPU或者其他资源), 然后远程执行一个任务。一个任务的早期抽象概念叫Container,后来更改为Activity, 我看到的设计文档中关于这部分提到了容器/分区等各种Unix类系统上的虚拟化技术, 不过没有具体的实现。在Linux上,后来也出现对LXC的需求,应该也没有实现。
调度插件是资源管理的重要组成部分,EGO支持多个调度器, 可以同时支持进程分配,虚拟机资源分配, 批处理任务资源调度等多种资源分配需求。 我在Platform的最后一阶段工作还设计了开发调度策略的DSL语言和默认实现,支持管理员用python语言开发自定义的调度策略。
EGO调度策略
来看一个经典的EGO调度策略:
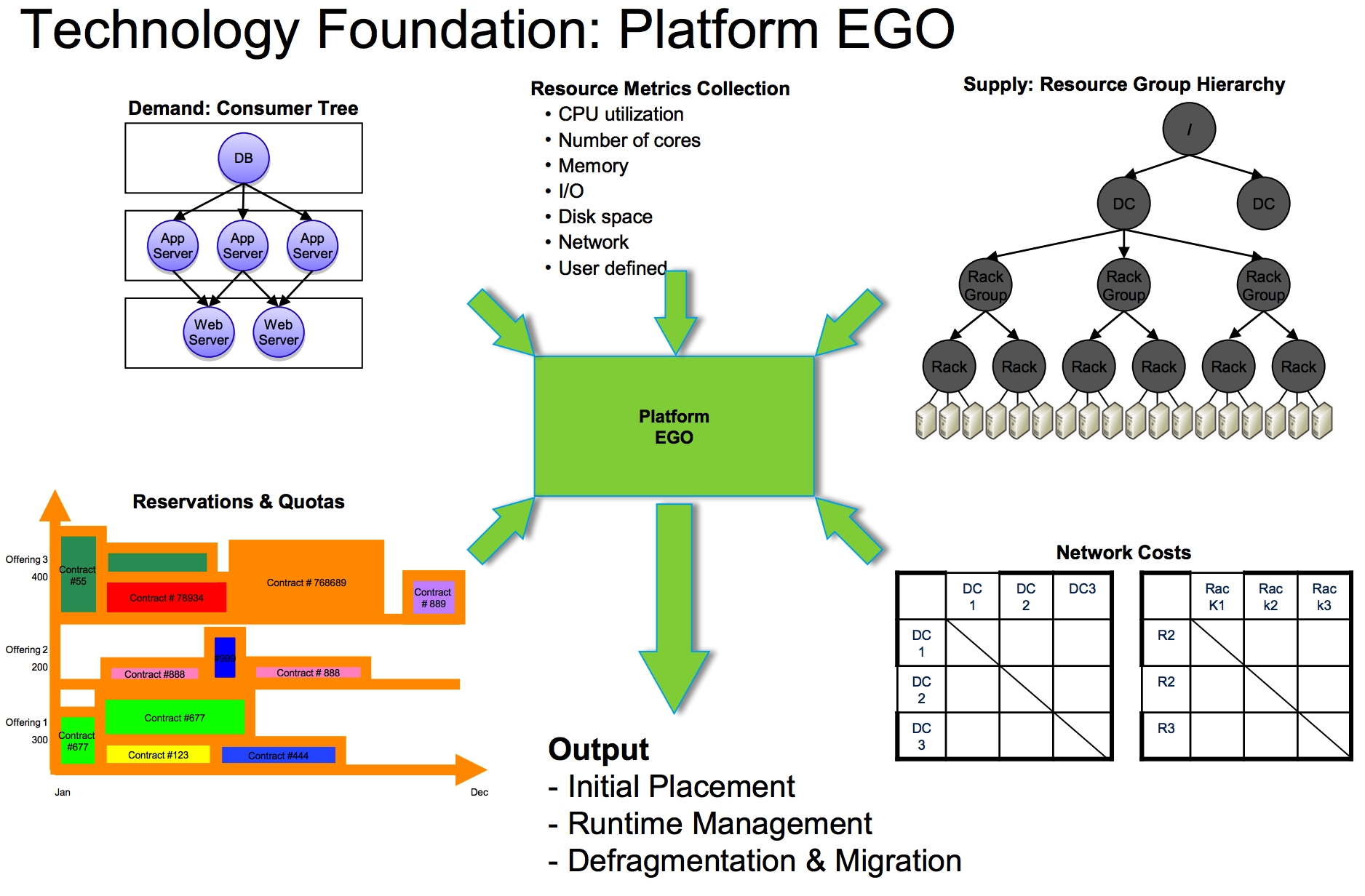
从上面的PPT来看, EGO的调度策略会考虑应用的Topo结构、资源的负载、资源拓扑逻辑、网络速率、包括应用的运行时间(比如分时运行、周期性运行等各种模型)。另外也考虑了运行期中的资源分片问题,提供了资源整理和迁移的功能。
安全插件支持基本的User/Password、Token/Credential、SSL等, 还包括各种商业的系统如Kerberos、SiteMinder等,当然也支持企业常用的AD、LADP系统,也支持基于RABC的权限管理。这里要多说一点, 经常大家会听到3A或者4A这种说法, 就是认证Authentication、账号Account、授权Authorization、审计Audit,中文名称为统一安全管理平台解决方案。 EGO的这部分设计就是为了cover企业在这方面的需求, 当时相关的功能陆续做了近1年才基本满足相关的需求。EGO原生设计就支持多租户, 很容易切换到当前云的环境和需求。
部署插件是为了满足各种上层应用系统二进制软件分发的需求,有基于FTP,NFS等各种实现。事件插件主要是将系统中关于资源生命周期的各种事件通知出去的, 支持SNMP等协议。
与Mesos、Yarn、Kubernetes的对比
比较EGO和Mesos、Yarn和现在的Kubernetes, 我们发现企业级应用系统除了核心的功能,管理功能非常重要,基本是3分功能, 7分管理。
细说一下,为了描述资源使用者, 设计了用户、消费者、client/session等概念来描述使用资源的人、组织和应用程序。 资源的抽象考虑各种扩展,采用业界标准CIM模型。资源分配过程支持优先级,预分配,实时分配,资源抢占等各种机制。资源支持运行进程、VM、容器等各种资源消耗模式, 当年我们经常讲的一句话, “分配资源后拿来什么也不干,也是一种资源使用方式”。 如果大家有兴趣,可以去看看《面向模式的软件架构卷3:资源管理模式》, 这本书将资源管理中的问题和解决方案都进行了抽象,值得一读。 综合来看, 对于企业级的资源管理或者集群技术, 可管理是个重要的需求。它要求的管理是细粒度的,全方位的。 另外它要和企业已有的IT架构和管理整合, 在软件架构灵活性和适应性要求较高。
#p#
应用管理
刚才讲的是资源管理或者集群管理的技术,再来看看应用层面的技术。先看一下天云SkyForm应用管理产品的架构图:
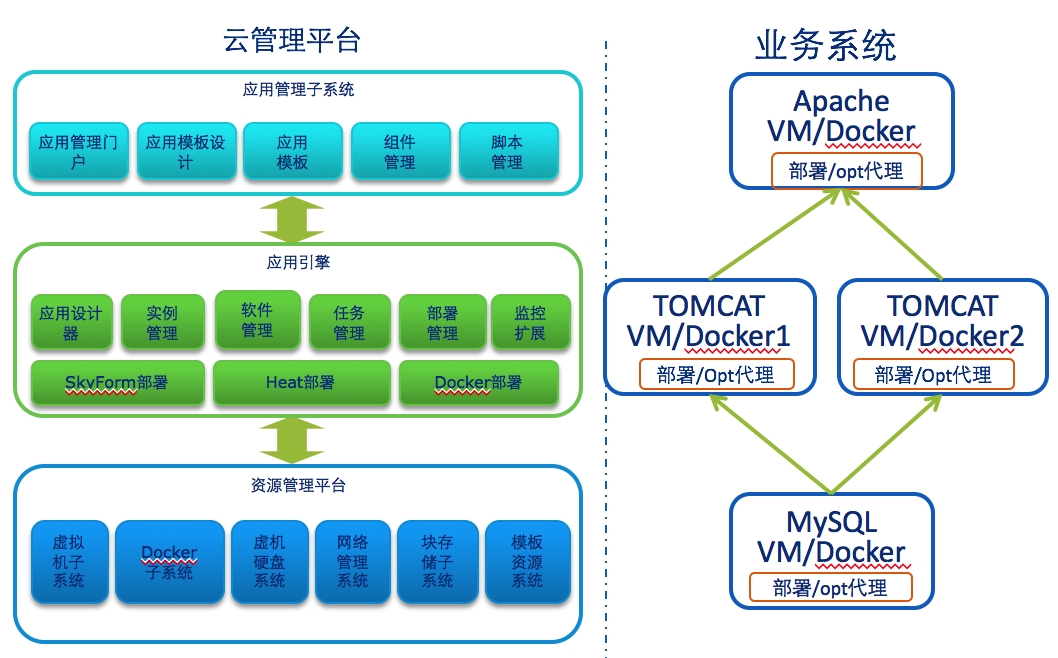
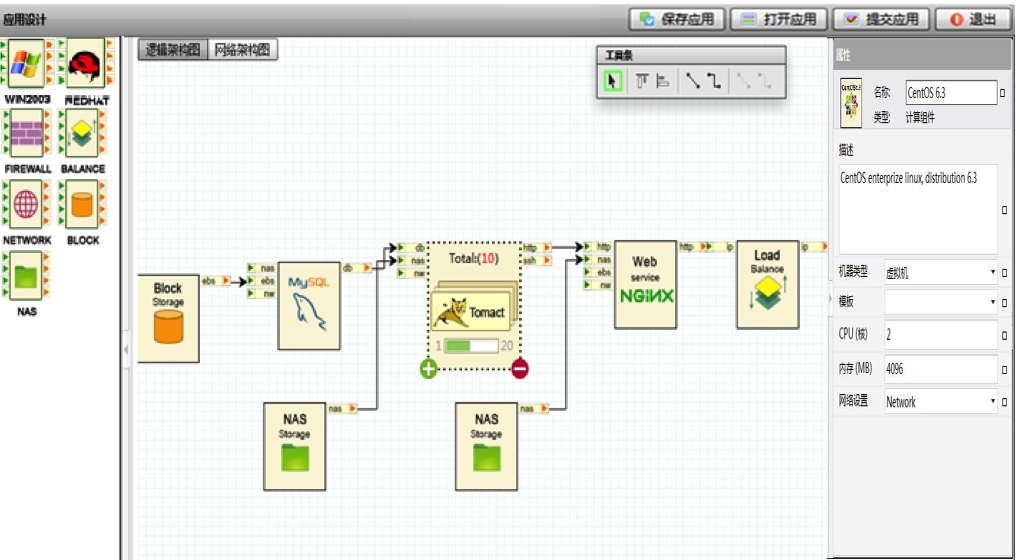
这个产品设计能够自动的按照模板定义自动申请资源、部署软件、配置系统,可以支持OpenStack、CloudStack等开源云平台,支持各种常见的 Apache Tomcat、MySQL,还支持Hadoop、HPC系统的自动部署和配置, 同时支持分布式运维任务执行管理、软件仓库管理等。开发这个系统是在2012年,当时社区还没有好成型的类似系统,尤其是没有统一的业界认可的软件分发格式。所以我们自己基于RPM等格式定义了一套软件包格式和描述语言, 另外还设计了图形化应用设计器,支持拖拽式应用设计,效果如下 :
在用户处实际使用的效果并不理想, 比如用户的应用不能或很难改造, 更需要应用拓扑展示, 另外我们定义的软件包格式也很难推行。用户需要应用性能监控数据, 同时希望基于性能的AutoScaling能力。 具体实现AutoScaling的过程中,也有两种需求: 一种是用户应用自主控制的方式,即通过API来扩展系统; 一种是采用系统提供的AutoScaling服务, 通过配置扩展策略和原始监控策略有系统自动实现。从管理的角度, 应用平台的建设和管理者的关注点在于应用的全貌, 比如应用的资源使用情况, 应用的运行数据(包括资源利用率, 业务处理能力), 应用弹性管理能力, 继而得到整体系统资源的使用情况以此为系统建设和再投资决策做出数据支撑。
架构演进
基于以上的用户需求,我们参考AWS的实践将原来的一体化设计拆分并扩展为部署服务, cloudwatch服务和AutoScaling服务。未来的应用基本都有大量数据处理的需求,所以需要支持大数据技术,再加上Docker的出现, 整体软件架构演进到下面的阶段:
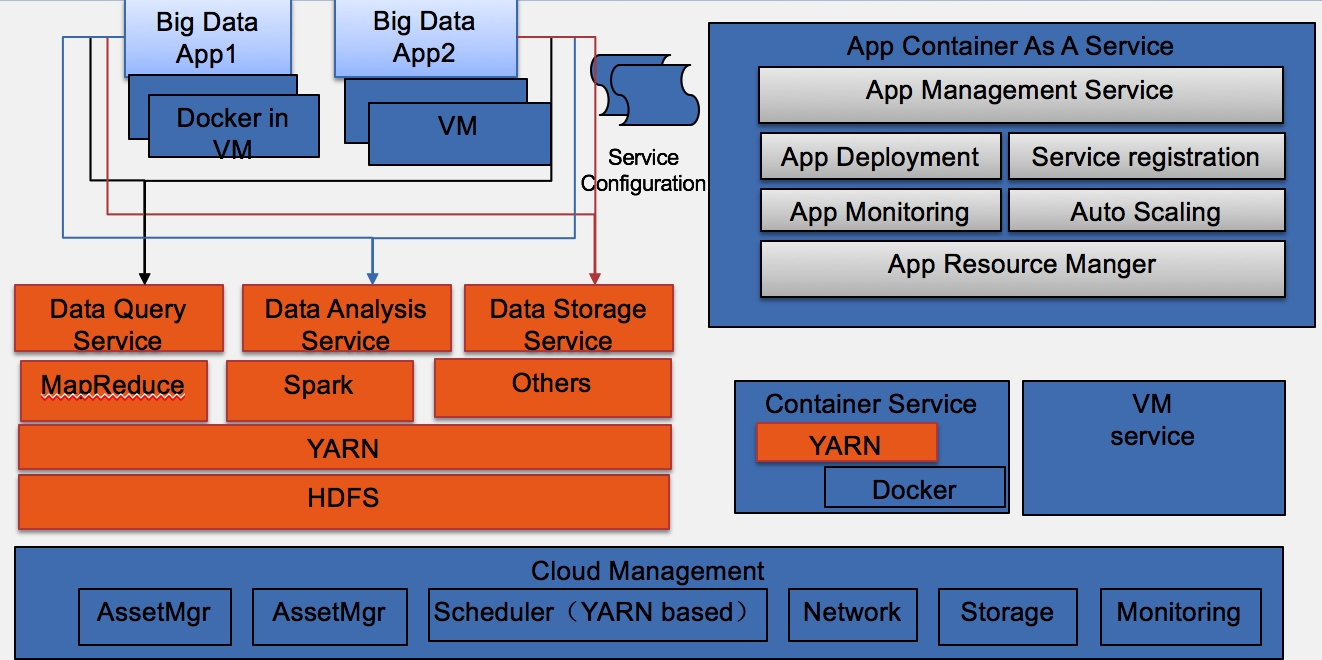
架构演进有以下几点动机:
- 互联网技术在企业逐步推广,我们看到传统企业在不断学习互联网的技术。
- 企业环境一般为混搭结构, 需要支持容器, VM和传统的遗产应用。
- 微服务架构正在互联网和企业软件开发中大量使用,应用管理平台需要针对它做一定设计。
在这个产品开发过程中的经验就是基于服务的架构和服务内部的微服务架构是满足当前云化应用的一个好的实践。
综合以上两个产品的经验和教训,建议设计和开发人员多研究一下AWS,它的服务设计和定义在企业领域有很多可借鉴的, 比如它就有专门的IAM服务来管理人、组织、安全、权限方面的需求。而且它的设计已经从局部模块的插件化的抽象方式上升到了整体架构的服务化抽象, 如何具体应用需要大家认真揣摩。我的实践总结下来为:功能层级化、架构SOA化、服务内插件化、 配合开发技术平台化。
Q&A
Q:你认为面向资源和面向应用架构的区别是?
A:一个关注的资源的供给,一个关注应用的架构、实现第2个其中会有一部分资源的申请、管理问题。面向应用更关注业务,所以上层的应用往往叫做负载管理系统或任务管理系统。
Q:大数据HDFS是在虚拟机VM里面还是真实物理机里面?
A:建议不要使用虚拟机,除非能将IOPS搞到类似物理机的程度,或者就是用来做算法验证,要不对存储系统冲击太大。
Q:目前 作者分享的一般都是基于互联网,针对企业级其实也有类似的技术,具体有哪些,怎么实现?
A:我介绍的第一个产品EGO就是完全面向企业的, 主要给金融等领域使用,比如花旗银行,倒闭的雷曼兄弟等 ,现在也在电信等行业使用,互联网行业基本没有用户。
Q:在服务化的过程中,架构如何同时兼顾老的非服务化的部件和服务化的服务?
A:其实我们有个实践就是,有的服务或部件就让它随着时间over吧。 重要的考虑云化,实在不行考虑盖个帽子封装成服务,就是经典的设计模式中的门面,adapter等的在服务层面的使用,也可以叫做服务网关之类的。
Q:你们是如何对集群资源做到细粒度的管理的,能说说你们遇到过哪些坑吗?
A:主要通过设计了资源组和各种资源tag来过滤资源,同时设计了一种规则语言和引擎支持select、order,支持各种数学运算和与、或非的逻辑关系来让用户定义资源的需求。最大的坑其实就是资源粒度定义有点问题,一度都出现零点几个slot的情况,其实简单点就好了,甚至随机分配都会有个很好的效果,毕竟这个宇宙也是混沌的,呵呵。当然只是个人的看法,其他人不一定同意。
Q:你们肯定有考虑过硬件资源使用情况负载的问题,Docker容器上前段时间倒是出了监控宝,可以监控容器的各种资源使用情况,但是想问下今天您提到的“应用的资源使用情况”,你们是做的实时监控吗?这个是怎么实现的?
A:原来EGO的调度策略一直有个基于负载的规则,LIM会准实时的收集系统的负载,包括CPU、MEM、DISK等信息然后汇总到master LIM供 EGO master使用。 天云的系统构建了一套自己的监控体系、也支持zabbix采集信息,还支持名的APM公司newrelic的agent 协议,另外也开放了API,可以自己定制监控采集系统。 监控宝我们也看过,类似的都有几个,不过这是应用开发团队需要自己选择的。
Q:Auto Scaling过程中是需要停止服务吗?
A:不需要停止服务,参考AWS和具体业务,我们设计了多个AutoScaling group,一部分用于系统基本运行需要的最少的资源,其他则为动态改变的,也就是说会保留最少的服务节点。
Q:天云的云平台如何解决单点问题,除了热备冷备,实现了分布式吗,怎么实现的,分布式的事务怎么处理的?
A:天云云平台一开始就是Load Balance模式设计,类似OpenStack,单点主要就是数据库。DB的问题也是采用常规的做法,当然也可以采用类似etcd、zk的方式,不过规模大不了。
Q:我觉得云平台最吸引人是弹性调度,能否就弹性调度如何实现这个问题,分享些经验给我们?
A:个人建议,多研究一下AWS的autoScaling服务,比如QingCloud的调度服务其实也是它的简化版。它支持定时、手动、规则驱动等触发方式,对执行的动作也有很多可配置的方式,比如发消息、自动执行动作等。
Q:EGO中对容错机制是怎么理解的么,能否讲下?
A:EGO的容错分了2部分,一部分是系统本身的,主要靠共享存储来保存核心数据,然后每个模块做到可以随意重启。 应用主要靠其中的egosc,它会监视应用的模块,做到按照定义的规则执行重启等动作,应用本身的数据一致问题,则要应用自己处理。
Q:能介绍下Symphony在DCOS中的作用么?
A:Symphony整体是个SOA的任务或负责管理系统,底层需要一个资源管理系统,类似Hadoop、Habase与Yarn的关系。
Q:EGO核心Master它是基于插件的架构,支持热插拔吗?
A:没有采用热插拔。 因为系统的每个组件都能够做到重启不丢数据,启动时会和相关模块同步数据并纠正不一致的地方,所以对系统稳定运行没有影响,类似Google的思路,做到每个点都能很容易的重启。
Q:能否介绍一个典型的调度器实现策略?如何考虑资源和需求的?
A:简单来说,就是将所有的资源请求先放到队列中,然后针对请求采用背包算法,或者线性规划算法来找一个次优解就行。因为要近实时的给出资源分配结果,所以没有最优解。
Q:云平台的容灾措施是怎么样,有什么好的方案?
A:容灾关键还是数据,关键在企业的存储设计,我也没有太多建议。
Q:Docker网络选择是host还是nat,性能损失分别是多少?
A:Docker网络真实只在自己环境管理自己SkyForm使用过,其他的都是实验室环境,没有真实线上环境测试,没法给出实际数据,建议去看一下新浪、雪球等公司的建议。 当前只是在一些项目中实验Docker,没有大规模去推。
Q:目前我们都提倡服务抽象、组合化,我们目的是为了向稳定、便捷的方向进取,那么,我想问是着重管理,还是着重技术功能方向呢?
A:具体分析,建议按照建设、实用、运维、优化管理的次序来考虑。
=======================================================================================
本文根据Dockone技术分享整理而成。分享人贾琨,云基地旗下初创公司北京天云融创软件技术有限公司产品研发总监兼架构师,2005年开始从事大规模Web服务、HPC/网格及云管理平台等分布式系统研发,历任腾讯Qzone、IBM Platform Computing资源管理调度系统,华为FusionSphere等产品的开发、架构及产品设计工作。精通各种IaaS平台、资源管理、资源调度等相关技术,2010年开始从事OpenStack研发、社区活动,当前主要关注Docker及相关资源管理技术,如Mesos、Yarn等。