事情是这样的, 现在有一个 redis 3.0 集群节点都是裸 redis 或 host 网络模式部署的容器 redis (基本上跟裸 redis 差不多), 需要把它们替换成 macvlan 网络模式的 redis 容器, 以显得我们的 dockerized redis cluster 很上档次.
这事情几个月前也搞过一次毫无压力.
然而这一次又搞, 就出岔子了. (这剧本不对啊摔)
于是开始加了两个 macvlan 的容器到上述 redis 集群作为从节点, 打算稍候 failover 替换掉主, 过了十分钟左右群里炸毛, 说数据都取不到, 或者格式不对...
上线一查, 发现正在加从节点的这个集群跟另一个集群的节点混到一起去了.
这里吐槽一下 redis 集群的协议, 两个正常服务的集群可以直接通过一个 cluster meet 合并成一个集群, 然后槽位分布乱了...
首先当然是紧急恢复线上业务, 先拉一个新集群出来再说 (所幸这个集群的数据不需要持久化).
结果, 新集群刚弄出来, 又被合进了上面那个集群. (这时我满脑子都是某个科教片里两个星系合并的一段视频, 满天都在炸! (论脑洞
然后 cluster nodes 看了一下, 发现集群里有几个节点地址变成了 172.17.x.x, 这应该是 docker 的内部网段地址, 所以反应过来, 可能是 docker 网络配置问题, 将握手流量发给了错误的节点, 然后那些节点被并了进来.
这时候创建一个新网段有点来不及了 (还打了个电话给已经请假回家的 @小六哇啦啦 老师...) 换了个思路, 把新 redis 换个端口部署, 再组个集群, 观察了一会儿, 这方法起作用了 -.-!!
恢复了被炸得鸡飞狗跳的线上业务之后, 就开始排查问题了.
线索还是之前 cluster nodes 看到的那个 172.17.x.x 网段, 测试确认了一下, 从 docker 容器内连宿主机, 宿主机 accept 得到的会是 172.17.x.x 这个地址. 而容器内路由表是这样的

确实如果宿主机的 IP 是 10.100.1.100 那么流量走的是 eth0 也就是 172.17.x.x 网卡. (10.222.0.0/16 是容器 macvlan 地址)
之后就明白了, 172.17.x.x 这样的网卡地址在不同物理机上是可能相同的. 也就是说, 遭遇的问题可能是如下过程所致
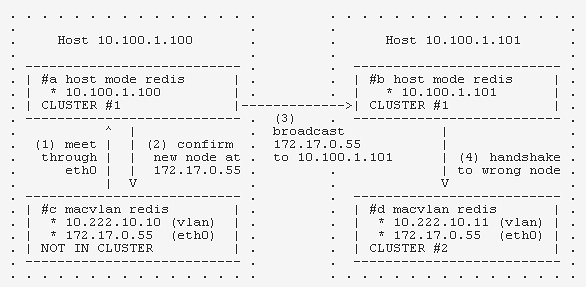
- 四个 redis #a #b #c #d
- #a #b 是两个 host 网络的 redis, 在同一个集群中, #d 是 macvlan 部署的 redis, 在另一个集群中
- #c 是一个空闲的 redis, 它与 #d 恰好有相同的 eth0 地址
- #c 通过 eth0 向 #a 发送了一个 handshake
- #a 确认, 这时, 它认为 #c 的地址是 172.17.0.55
- #a 将新节点地址广播给 #b
- #b 向 172.17.0.55 发送一个握手请求, 然而, 此地址在它所在机器上对应的是 #d, 之后两个集群就混一起去了
这也解释了为啥几个月之前这么搞的时候没出问题, 应该是那时候运气好没有相同地址的容器; 同时也解释了为啥不是每个纯 macvlan 模式的 redis 集群都中枪.
后来在测试机房找了两个恰好相同网卡的容器, 按上述思路搭了集群试了试, 果然重现了.
解决方案
- 因噎废食 : 以后别这么混搭玩了
- 绕过 : 端口号不一样法
- 改默认路由 : 默认就走 vlan 网卡, 不过这样的话不能访问外网, 对 redis 而言没问题, 但其他业务可能就不行了
- 加路由 : 其实可以通过在容器内加一条路由 10.100.0.0/16 走 vlan 这样宿主机 accept 到的地址就会是机房***的 vlan 网卡地址了, 这个方案 @CMGS 正在评估中
EOF