这是我们依托Docker容器来构建数据密集型产品AdRoll Prospecting系列文章中的***篇。 PPT。
一个数据驱动产品
就在6月17号,我们的一款新产品AdRoll Prospecting,发布了公网测试版。了不起的是,该产品是由一个六人小组,在六个月时间内,从头开发并且按时发布的。
该产品所做的实际上是市场营销的圣杯:AdRoll Prospecting的核心是一种大规模机器学习模型,通过对数十亿Cookie进行分析,能够预测出谁最有可能对您的产品感兴趣,从而为您的企业发现新客户。
现代化的数据驱动产品AdRoll Prospecting,不单单是机器学习,还提供一个易用的仪表盘(基于React.js构建),让您能够详细查看分析的效果。在幕后,我们连接了AdRoll的实时竞价引擎,还有许多检查点和仪表盘用以监控产品内部的健康情况,这使得我们能够在问题影响客户之前就将其解决。
借助于AdRoll之前开发再定位广告产品的经验,我们在如何构建一种复杂系统上取得了共识。当我们着手开始AdRoll Prospecting产品之时,我们回顾已有的经验教训,在不牺牲健壮性和成本前提下,如何对此类大规模数据驱动产品尽快建立一个灵活的并可持续发展的后端基础架构。
管理复杂度
我们对结果非常满意,这也促成了本系列文章。它不仅使我们的开发和发布按时完成,而且我们也计划将现有工作负荷迁移到新系统。
新架构最重要的功能是简单。知晓了我们诚待解决的问题是如此复杂,我们不想引入框架使其更加复杂,并迫使我们在此框架中工作。
我们的架构是基于三个互补层所构成的一个Stack,依赖于众所周知并身经百战的组件:
- 在底层,我们使用AWS的Spot Instances和Auto-Scaling Groups来按需提供计算资源。数据存储在AWS的简单存储服务S3中。我们建立了一个简单内部工作队列,Quentin,所以可依据工作队列的实际长度,利用自定义的CloudWatch指标触发扩缩容。
- 在中间层,我们使用Luigi来编排一套由相互依赖的批量作业组成的复杂关系图,Luigi是基于Python的开源工作流管理工具。
- 在最上层,每个独立任务(批量作业)均被打包成一个Docker容器。
上述Stack允许任何人使用Docker快速构建新任务,根据输入和输出使用Luigi定义任务间依赖关系,并使任务可在任意数量的EC2实例上执行,而无须考虑服务供应(这要感谢我们的调度和自动扩缩容组),如下图所示。
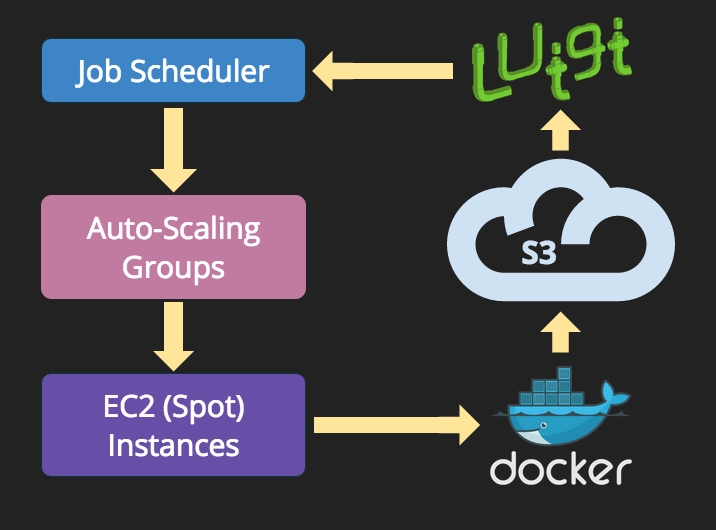
这一简单的架构使大量复杂性可被很好的管理起来。Docker容器封装了用7种不同语言实现的批量作业。Luigi用来编排约50种作业紧密相连的关系图,Quentin和Auto-Scaling Groups(自动扩缩容组)技术,允许我们在弹性的数百台大规模EC2 Spot Instances实例上,以最为经济的方式执行作业。
拥抱这一错综复杂、集市化方式的***好处是我们可以安全的为每个任务选用最适合的语言,实例类型和分布式模式。
旧新范式
将批量作业容器化已经使用了几十年。早在上世纪60年代,在大型机上就已率先使用批量作业和虚拟化技术了。此外在本世纪初,谷歌使用操作系统级的虚拟化技术(谷歌内部系统Borg)隔离批量作业。若干年后,使用开源软件如OpenVZ和LXC,这种方法广泛流行起来,后来又有了管理服务,例如基于Solaris Zones的Joyent Manta。
容器技术解决了批处理中的三个棘手问题,即:
- 作业打包 – 一个作业可能依赖于众多的第三方库,而这些库也有自己的依赖包。特别是,如果作业是脚本语言如Python或R编写的,封装整个环境在一个独立包中的意义非凡。
- 作业部署 – 打包好的作业需要在主机上部署,且需要在不改变系统资源情况下被顺畅地执行。
- 资源隔离 – 如果多个作业在同一主机上被同时执行,它们必须共享资源且不能相互干扰。
在Docker出现之前,这些问题使用已有的虚拟化技术都可以解决,且有几十年了。什么原因Docker如此成功?Docker的出现使得创建容器非常容易并被大众接受,现在每个分析师,数据科学家,初级软件工程师都可以使用笔记本电脑在容器里打包他们的程序。
这样做的结果是,我们可以允许并鼓励每个系统用户使用他们最喜爱的,最适合的工具完成作业,而不必学习一种新语言或是MapReduce等计算模型,怎么高效怎么来。每个人自然也就对他们使用Docker打包的作业负责,出了问题也在容器内进行修复。
其结果不仅是更快的上市时间(这要感谢使用不同技能和实战工具如R语言带来的高效性),也是跨组织赋权的感觉。每个人都可以访问数据,测试新的模型,并使用他们所知道的***的工具发布代码到生产环境。
良好行为的预期
将批量作业容器化不仅是关于和平,爱,和持续集成与部署。我们希望作业能够遵循一定的规则。
大多数作业遵循的基本模式是,作业只能从S3中获取不可变数据作为输入,产生不可变数据存入S3中作为输出。如作业坚持这一简单模式,那此类作业就是幂等的。
实际上,从函数式编程角度上来说,每个容器就是一个函数。在这一思路下,我们发现,从最简单的Shell脚本到最复杂的数据处理作业,很自然的就写好了容器化的批量作业。
另一相关要求是作业必须是原子的。我们期望,如同Hadoop一样,作业在成功完成后,产生一个_SUCCESS文件。在S3中对单一文件的操作是原子的,所以这一要求很容易满足。我们的任务依赖关系是由Luigi建立的,只有当成功文件存在时,输出数据才被视为有效,因而部分结果并非问题。
我们发现这一明确依赖S3中的文件方式,容易解释、问题定位和故障排除。S3是一个近乎***的数据结构:它高度可扩展,运行时间有着惊人的记录,且廉价易用。如果数据不容易被访问,则Docker带来的便捷性将大打折扣。
下一步:Luigi
容器化批量作业得益于关注点的明确划分。这不仅使得作业编写变得容易了,而且也明确了每一作业执行时间长短,是几分钟还是最多几小时,对于利用瞬时计算服务Spot Instances来说意义重大。
一个不可避免的结果是,系统变成了一个作业间相互依赖的复杂毛团。Luigi已被证明是管理这一依赖关系图的最直接的方式,我们将在下一篇博客中探讨这一主题。
译者介绍
Andrew,PPTV总监,乐于分享对于云计算的一些想法和对未来科技的猜想。